Paper 1: STATISTICAL PARAMETRIC SPEECH SYNTHESIS USING DEEP NEURAL NETWORKS ---- Google, Heiga Zen (ICASSP 2013)
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/40837.pdf
总结以及感想
看了考古文对科研又产生了新的理解,目前的论文大多修修补补,灌水严重,实验部分不是很充分,无法印证论文的可复现性和实验结论的可靠性。这篇论文虽然采用的DNN技术还是最早期的神经网络系统架构,但是对于系统设计的每一个细小的结构都进行了充分的实验对比验证,得到了可靠的实验结论。在结论处也给同行留下了更多想象和探索的空间。强烈建议TTS从业者逐字逐行阅读本文,学习论文构思和写作的思想,并且了解深度学习在TTS领域应用的起源,至少从实验部分的objective /subjective evaluation可以学习到客观评估TTS合成效果的方法,使得自己的TTS研究更加扎实可靠。打分:🌟🌟🌟🌟🌟
Abstract
痛点:传统的统计参数语音合成方式通常采用决策树,上下文依赖的HMM模型来表示给定文本的语音的概率密度。其中,语音参数是从概率密度中生成的来最大化它们的输出概率,然后再用生成的语音参数,重构语音波形。这种方法的缺点是,决策树对于建模复杂的上下文依赖关系是比较无效的。
解决方案:本文基于深度神经网络(DNN)。输入文本和声学表示的关系通过一个DNN来建模。DNN的使用能够解决许多传统方法的局限性。
实验结果:DNN效果优于HMM
Introduction
基于HMM的参数方法在过去十年间盛行,相对于波形拼接算法来讲,它的优势在于能够灵活地替换音色,小的踪迹和鲁棒性。然而,它的主要局限性是合成语音的质量。Zen等提出了合成质量的三个主要特征:声码器,声学模型的准确度,和过拟合。本文的方法主要在于解决声学模型的准确度。
影响语音的一定数量的上下文特征包含音素、语言和语法特征,会在统计参数合成过程中,参与建模。典型系统包含50种上下文。因此,这些复杂的上下文依赖的有效建模是统计参数语音合成的关键点。为了解决这种上下文问题的标准方法是基于HMM的统计参数语音合成算法。对于每一种独立的上下文组合,都采用一个独立的HMM模型,作为一个上下文相关的HMM模型。通常来讲,对于这种全部上下文依赖的HMM模型来说,训练数据是不充分的,难以学习到一个稳定的模型,能够覆盖到所有所需的上下文组合。
为了解决这种问题,基于自上而下的决策树算法的上下文聚类被广泛使用。在这种方法中,上下文-依赖的HMM的状态被区分为多个“簇”,并且每个“簇”的分布参数是共享的。HMM模型的任务是通过二分类决策树,检验每一个HMM的上下文组合,其中一个上下文相关的二分类问题是与每一个 非叶子结点 相关的。“簇”的数量,也是 叶子结点 的数量,决定了模型的复杂程度。决策树通过序列化挑选能够在训练数据集上产生最高mle的分数来挑选问题。树的大小是通过一个预定义的mle阈值,一个模型复杂度惩罚,以及交叉验证来决定的。采用了上下文相关的问题和状态参数共享后,未知的上下文和数据稀疏性问题得到了有效解决。就像在语音识别中所成功解决的,基于HMM的方法自然地对于有丰富数据的上下文有较好的效果。
尽管基于上下文决策树的HMM模型在统计参数语音合成方法中是有效的。但是,有以下局限性:
- 对于复杂上下文依赖如“XOR”,奇偶校验和复用问题,这种方法是无效的;
- 这种方法将输入的空间区分开,并且对于每个区域都采用了独立的参数,每个区域对应着一个决策树的叶子结点。这导致了分裂训练数据集,并且在聚类和估计分布的时候,使得每个簇的数据不充分。
有一个相对大的决策树,并且分裂训练数据集都会导致过拟合,损害合成语音的质量。
为了解决上述局限性,本文采用基于DNN的结构。上述基于决策树的方案,建模了从 文本中抽取的语言上下文到语音参数的映射。在这里的决策树被一个DNN模型所替代。值得注意的是,自从90年代开始,NN就尝试被应用于TTS中。
DNN VS Decision tree (DT)
- DT 在表达输入特征的复杂关系时无效,如XOR、d 位奇偶校验函数、或者多路复用的问题。为了表达上述情境下的问题,决策树可能会十分巨大。然而,这些关系能够被DNN模型来具象表示
- 决策树致力于分割输入空间,对每个空间采用一组独立的参数和一个叶子结点。这样会导致在每个区域的数据数量少和较差的泛化性能。Yu et al 证明了在采用决策树建模时,一些较弱的输入特征如语音中词级别的重读会被丢失。由于DNN的权重是从整体的训练数据得到的,所以DNN会得到更好的泛化性能。DNN也提供了输入高维、多种输入特征的可能性。
- 相较于决策树,通过反向传播来训练一个DNN模型通常需要大量的计算过程。在预测过程中,DNN需要在每一层都有一个矩阵乘法,但是决策树仅仅需要通过一个输入特征的子集从根结点遍历树直至叶子结点。
- 决策树的推理是更加可解释的,DNN中的权重很难在直观上获得解释。
基于DNN的语音合成
由于人类的发声系统是多层级的,才能够将文本信息转换为语音波形,所以本文尝试采用深度神经网络来进行语音建模。
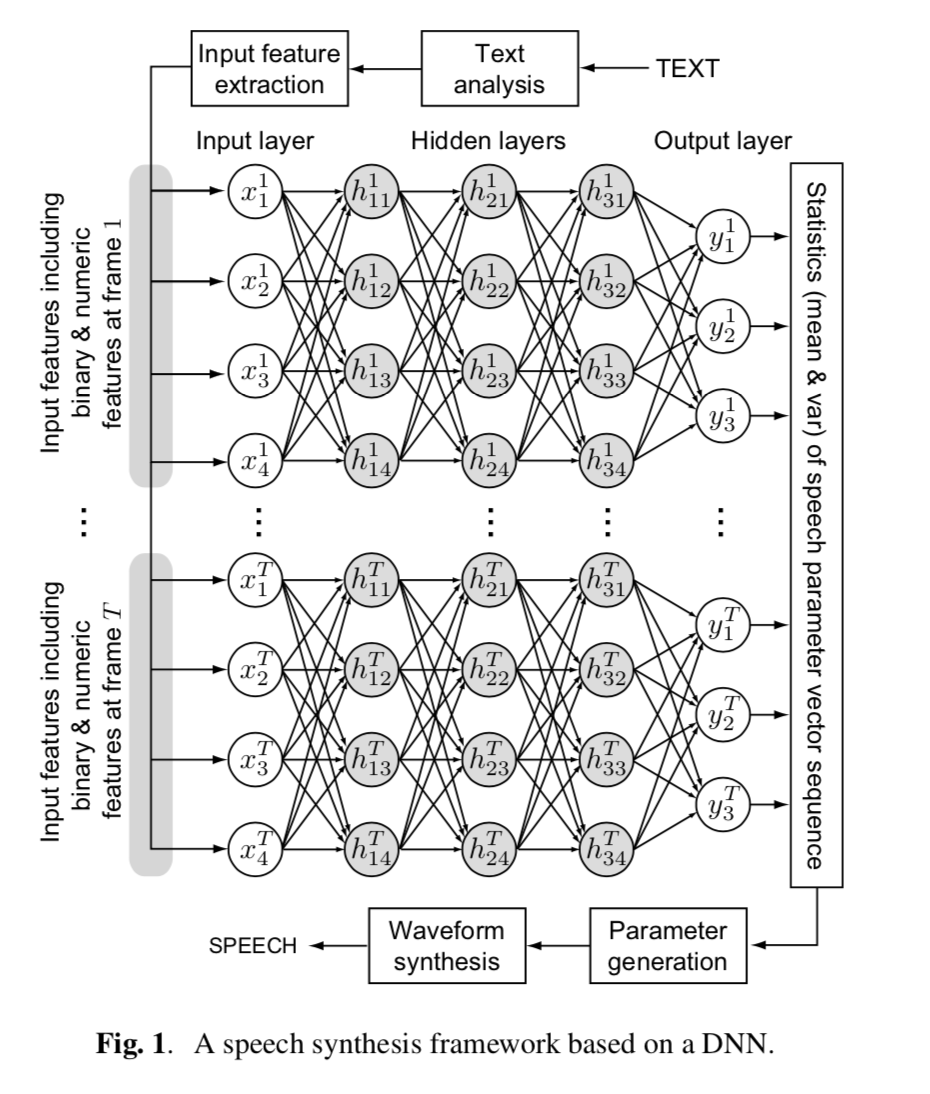
DNN-based-tts
上图展示了一个基于DNN的语音合成框架。输入文本首先被转换为输入特征序列\(\{x^t_n\}\),其中的\(x^t_n\)表示在第\(t\)帧的第\(n\)维输入特征。输入的特征是对于文本上下文关系的二分类问题,包含如(e.g is-current-phoneme-aa?)和数值(e.g. 在短语中的单词数量,在当前音素序列的当前帧的相对位置,和当前音素的发音时长)
然后输入特征通过一个训练好的DNN,采用前向传播的方法被映射到输出特征\(\{y^t_m\}\),其中\(y^t_m\)表示在第\(t\)帧的第\(m\)个输出特征。输出特征包含频谱和激励参数以及他们的时间导数(动态特征)。DNN的权重能够采用从训练数据集中抽取的成对的输入和输出特征来进行训练。类似于HMM的方法,这样是可以生成语音参数的。通过从DNN中设定预测的输出特征作为均值向量,再加上从所有训练数据预先计算的方差作为协方差矩阵,语音参数的生成算法能够生成平滑的语音参数特征轨迹,满足了静态和动态特征的统计情况。最终,一个语音合成模块通过得到的语音参数来生成语音波形。
注意到,文本分析,语音参数生成,和波形生成模块可以与HMM模型共享,即仅仅从上下文依赖关系的标签生成统计参数的过程需要被替换。
Experiments
4.1 实验条件
实验数据:US-EN 女性语音数据,约33000条。语音分析的条件和方法论类似于Nitech-HTS2005系统的方法。语音数据首先从48KHz降采样到16KHz,然后每5ms抽取一次40维的Mel倒谱系数,\(log F_0\),和5段非周期性系数。每一个观察向量包含40维的mel倒谱系数,\(log F_0\),和5段非周期性系数,以及他们的delta和delta-delta特征。从左至右,包含5个状态的无跳过隐藏半马尔可夫模型 (HSMM)被采用。为了建模 \(log F_0\)序列包含了声学和非声学观察序列。一个多空间的密度分布被使用(multi-space probability distribution (MSD))。基于决策树的上下文聚类的问题数量是2554个。在HMM系统中的决策树大小是通过改变模型复杂度惩罚因子\(\alpha\)来控制的(最小描述长度标准(MDL)是(\(\alpha=16,8,4,2,1,0.5,0.375,or 0.25\))。当\(\alpha=1\)时,Mel频谱,\(log F_0\)和频带非周期性的叶子结点的数量分别是12342, 26209, 和401(总共有3209991个参数)。
基于DNN系统的输入特征包含表征类别语言上下文(例如音素身份、重音标记)的342个二分类特征和表征数字语言上下文(例如,单词中的音节数、短语中当前音节的位置)的25个数值特征。除去文本上下文相关的输入特征,还包含了3个用于粗略编码当前音素序列中当前帧位置的数值特征,以及一个用于估计当前音节时长的数值特征。输出特征与HMM系统基本一致。为了通过DNN模型建模\(log F_0\)序列,我们采用了显式发声建模(explicit voicing modeling)的方法来获取连续\(F_0\) ,发声/不发声的二分类特征值被用于添加到输出特征,并且在不发声值中的 \(log F_0\) 通过插值得到。为了降低计算成本,80%的静音段从训练数据中移除。DNN的权重被随机初始化,然后在最小化MSE的目标函数下得到最优化。优化策略为基于小批次的随机梯度下降(SGD)的后向传播算法。DNN的输入和输出特征均被正则化,其中输入特征被正则化至(0,1)分布,然后输出特征根据训练数据中的最大最小值被正则化至0.01-0.99隐藏层采用sigmoid激活函数。建模频谱和激励特征参数的DNN神经网络被训练。
在评估的语句中,语音参数通过语音参数生成算法被生成。在倒谱域采用了基于后过滤的频谱增强算法。语音波形通过source-filter模型来重构语音波形。
为了客观评估HMM和DNN模型系统,MCD(mel-cepstral distortion)(dB),Linear aperiodicity distortion (dB), 发声/不发声错误率(%),和\(log F_0\)的RMSE被使用。音素发音时长在后面被使用,我们挑选了173句训练集外的语句用于模型评估。
4.2 客观评估
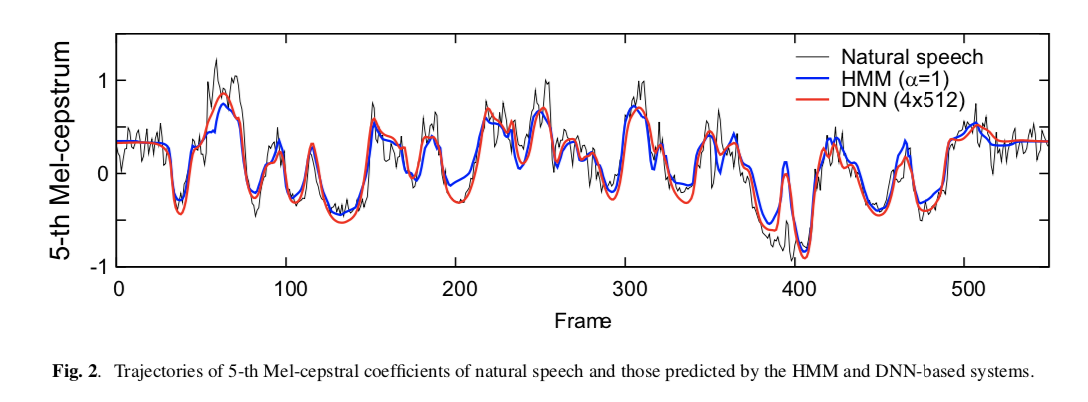
5th-mcep-comparison
上图绘制了Ground-Truth、HMM预测值和DNN预测值的第五个mel倒谱系数,从图中可以观察到,三个模型都可以产生合理的语音参数轨迹。
在客观评估中,我们调查了预测结果和DNN结构(1,2,3,4,5层)的关系,以及与每层神经元个数(256,512,1024,2048)的关系,下图展示了实验结果。
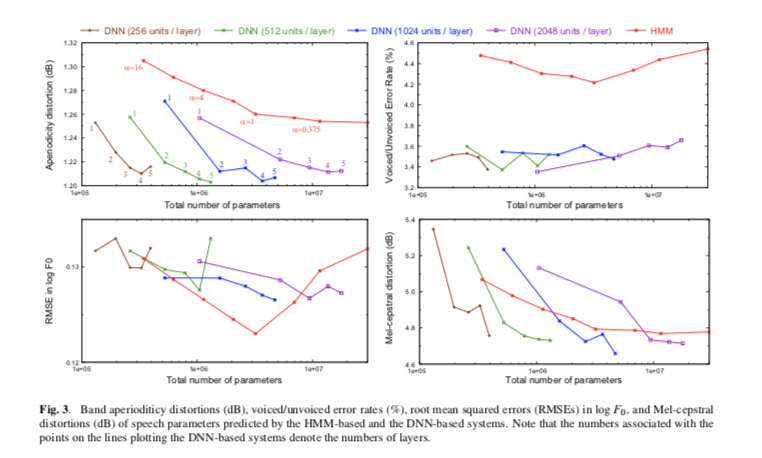
dnn-tts-exp-res
基于DNN的系统一直都比HMM系统要好在 "voiced/unvoiced error rate"和"aperiodicity prediction"。在MCD中,有多层的DNN模型要相似于或者好于HMM模型。然而,在\(log F_0\)的预测中,HMM在大多数情况下要好于DNN模型。其中,所有的不发音帧都被插值作为发音帧来建模。我们认为这种方法会降低\(log F_0\)的预测效果,因为这些插值的\(F_0\)对于DNN模型来说是一个bias。对于MCD和aperiodicity预测中,模型深度的提升比在每一层上增加神经元的个数更加有效。
以上的客观指标并不能评估合成语音的自然度,但是可以作为评估声学模型准确率的指标。
4.3 主观评估
173句话被评估,每个评估人最多评估30句话,这些话术是随机打乱的。每一对语音被5个人评估。评估人有带耳机。在听完一对语音后,评估人需要选择一个更喜欢的语音,如果觉得两个语音很相似的话,可以选择“中立”,在这个评估过程中,HMM系统和DNN系统采用相似的模型数量来被评估。DNN模型采用了4个隐藏层,神经元的个数也进行了多组实验(256,512,1024个神经元)
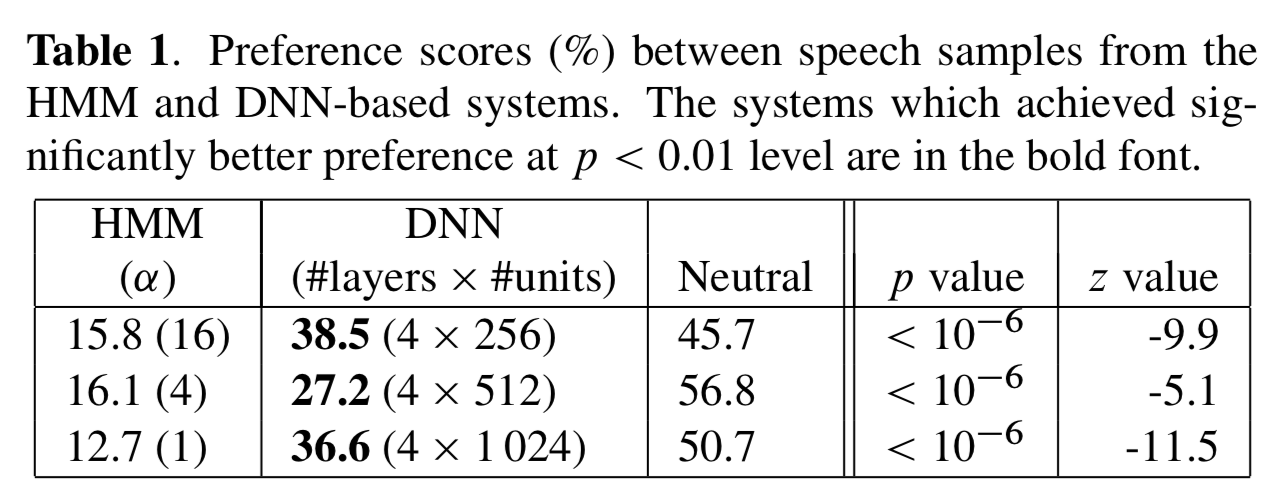
dnn-tts-mos
上表展示了实验结果,可以从以上结果看出,在相似的参数数量配置的情况下,DNN模型要远优于HMM模型。我们认为较好的MCD代表了更佳的效果。
结论
这篇文章examined the use of the DNNs to perform speech synthesis. DNN模型有潜力解决传统DT-HMM模型的局限性。主观评估和客观评估均显示DNN能够实现较好的效果。HMM的一个优势在于模型参数较少,计算开销较小。在合成时,HMM模型便利决策树来找到每一个状态的参数。然而,本文提出的DNN算法是在每一帧进行输入到输出的预测,接下来的工作可以在如何降低DNN模型的计算开销,添加更多的输入特征包括一些弱特征如重读,并且可以探索如果获得一个更好的 \(log F_0\)建模方案。
Paper 2: Speech Synthesis with Neural Networks ---- Motorola, Orhan Karaali (1996, Sep, World Congress on Neural Networks Invited Paper)
https://arxiv.org/pdf/cs/9811031.pdf
感想与总结
这篇1996年的文章算是nn-tts的创世之作,文章采用了一个duration mode来预测音素的发音时长,以及一个phonetic network来预测每一个音素的声学特征,这个idea让我不由得想到当前的如Fastspeech等与这个想法如出一辙,同样的也是需要预测duration和音素的声学特征,但本文的行文思路尤其是实验部分,感觉没有上一篇论文更加翔实充分,所以打分的话我会给:🌟🌟🌟🌟
Abstact
传统的文本-语音转换通过拼接短的语音单元或者采用基于规则的系统来将语音的音素表示转换为声学表示形式,然后被转换为语音。本文描述了一种采用时延神经网络(time-delay neural network TDNN)的方案来进行音素-声学特征的建模,不需要额外的神经网络来控制生成语音的timing。这个神经网络系统相较于拼接算法可以降低对于系统存储资源的需求,对比于其他的商业系统表现良好。
Introduction
1.1 Description of Problem
文语转换通常包含了先将文本转换为语音参数,再将语音参数转换为语音波形。计算机交互可以采用对话沟通交互方式,也可以配置到移动端。拼接系统首先制作拼接数据库,然后再拼接时,调整音素的发音时长,平滑转接点来生成语音参数。拼接系统的主要问题是存储成本高昂。基于规则的合成方法将每一种可能的音素表示存储好目标声学参数。然后根据衔接点的情况来根据规则选择语音参数,主要问题是:拼接点不自然,因为转接规则倾向于只生成少量的转接风格。另外,大量的转接规则需要进行存储,会造成合成的机械音。
1.2 Discussion of the use of networks
先前提到的两种方法都是语言-依赖的,而NN方法是语言-不相关的;
拼接系统的高昂存储成本导致了难以配置到移动端,而NN通过生成具象的表示方式,能够降低拼接系统的冗余性;
下图展示了TTS的流程图(终于找到了现有的TTS流程设计的出处)
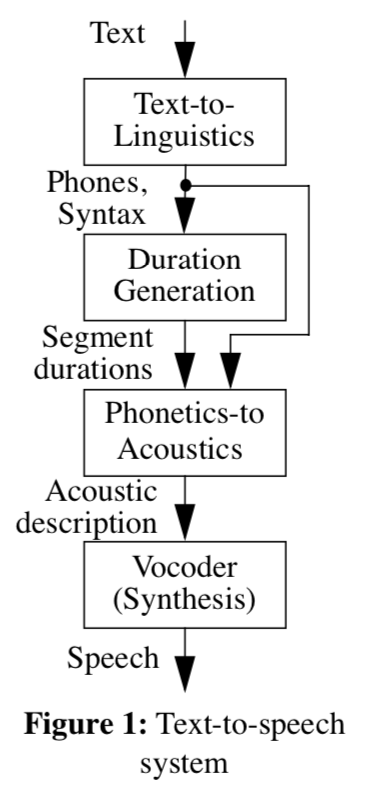
tts-diagram
系统描述
2.1 数据库
38岁男性,居住在Florida和Chicago。录制时采用了类似于近距离麦克风的DAT录制起。文本包含480个音素均衡的语句,是从Harvard sentence list中筛选出来的。除此之外,160句在其他情境下的话术也被录制了下来。录音音频通过数字方式转移到计算机,每句话对应一个音频。每句话被归一化,以使得每句话都在非静音段有相同的平均信号能量。文本信息被标记为音素、节奏和音调信息。
标记方式采用了类似于TIMIT数据库的标记方式(是ARPABET的变种),停止标记为关闭和释放作为单独的音素。这使得模型能够有效预测到停顿,以及开始。精准的对齐对于帧级的损失函数是有效的。
音素不是唯一的输入特征,音素时长,F0曲线(通常被音节重读和语法边界影响)。语法边界(syntactic labelling)标记了音节,词,短语,从句和句子的开始和结束时间。语法重读(lexical stress:primary, secondary, or none)被应用到词汇的每一个字母中。词性(function word (article, pronoun, conjunction or preposition) or content word);每个词语都有一个层级(level),基于生成F0的rule-based系统。
尽管语法(syntactic)和重读(lexical stress)对于语音的韵律变化很重要,但是这些信息没有完全决定了这些韵律变化。说话者对于语句的重读可能取决于句子中的对比度,比如在遇到陌生词汇的时候,可能会不自觉的重读。因此标记如此音调重读的实际位置到字幕上,或者词语间的强对比性是有效的。在英文中的标准是ToBI(Tone and Break Index)系统。
2.2 从音素表示上生成片段时长
神经网络的两个任务之一是去决策,从音素顺序和语法和韵律信息上,每一个音素的发音时长。
网络的输入大多数采用二分类数值,分类数值代表了采用1-out-of-n codes和一些通过bar codes表示的小的整数值。表示音素片段的输入数据包含音素片段,它的发音特点,字幕凸起的描述和包含片段的词语,以及片段接近的任何语法边界。网络结构被训练来生成时长的log。
时长预测网络结构如图2所示,网络有两个输入值(2和3),通过I/O block 1 和 2 输入。(Stream 2 包含了通过shift register来给一个音素提供上下文描述),stream 3 包含了仅仅用于一个特定音素时长的生成过程。当神经网络被用于生成时长的过程中,I/O block 6写入输出的数据流。在训练过程中,Block 6 读取目标值并且生成error value。Block 3、4和5是单层的神经网络模块,模块7、8和recurrent buffer控制了循环生成的机制。
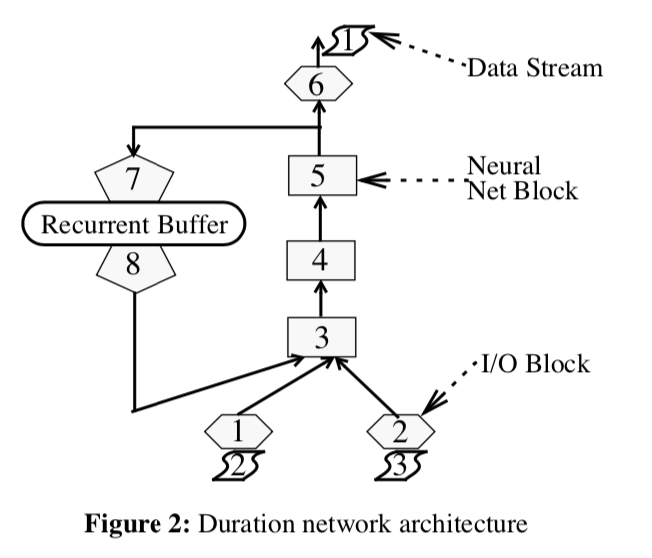
duration-prediction
2.3 从音素和时长信息生成声学信息
系统中使用的第二个神经网络从音素、语法和时长信息来生成语音参数信息。更精准地来说,网络从一个帧级的音素上下文信息生成语音10-ms帧的声学表示。
2.3.1 网络输出 -- Coder
神经网络不会直接生成语音,这个的计算资源十分昂贵,并且不太可能生成好的结果。该网络为声码器的分析-合成风格的合成部分生成数据帧。许多语音编码的研究致力于数据压缩的问题;然而,神经网络对于coder的需求没有被大多数的数据压缩技术所满足。具体来讲,将语音编码成每帧的数值向量是有价值的,这样的话,向量的每个元素对于每一帧都会有一个定义好的数值,因此用于训练的神经网络的错误度量是合适的。(例如,如果神经网络生成向量,并且错误度量相对于训练向量是较小的话,生成语音的质量,即通过running these vectors通过coder的合成部分的话,将得到较好的语音质量。)加权Euclidean距离被用作error criterion使得coder没有使用二分类输出值是明智的,并且根据其他的向量元素,向量元素的含义没有改变。
coder是LPC声码器的形式,采用线性频谱(line spectral frequencies)来表示filter coefficients和一个2-band的激励模型(不同的filter coefficients的表示形式被测试,模型对于线性频谱表现良好)。2-band激励模型是一个multi-band激励模型的变种,包含一个低频带的voiced band,和一个高频带的unvoiced band。两个bands之间的边界是coder之一的参数。F0 和 power of the voice signam是剩下的参数。F0在不发音的帧级,被插值为一个高频的数值。
2.3.2 网络输入
音素网络的输入包含了时长网络的所有输入,和时长网络输出的timing information。网络采用了一定数量的不同的输入coding技术。blocks 5,6,20和21采用了300毫秒的TDNN的风格输入窗口。窗口的采样不是均匀的,最优的采样区间是通过分析神经网络从TDNN窗口的不同部分来决策神经网络对信息的使用。Blocks 6 和20 处理了一组与输入音素相关的特征,Blocks 7和8为音素和语法边界编码时长和距离信息。网络的输入数据是二分类数据的混合,1-out-of-codes和bar codes
2.3.3 网络结构
决定好的网络结构需要大量的实验,也就需要大量的计算资源,然而本课题的复杂程度和数据集的大小使得训练时间成为了主要瓶颈。因此,一个 in house neural network simulator被开发来降低训练时间(多个月->几天),并且可以同时验证多个方法。一些神经网络的技术和理论通过这种方式被pass掉了。
最终的网络结构整合了TDNN、recurrent、和modular网络,和一些实验过程中演化的技巧。下图是当前方法的图示,其中六边形模块是I/O或者用户写入的子程序,方块是神经网络的模块。神经网络的模块采用后向传播来训练。网络的模块化是通过专家知识来手动调整的。
网络通过逐渐降低的学习率和momentum方法来训练,以一种新型的顺序和随机混合的训练模式来训练。训练的网络需要<100 Kilobyters of 8-bit quantized weights ,对比于拼接算法,得到了显著降低。
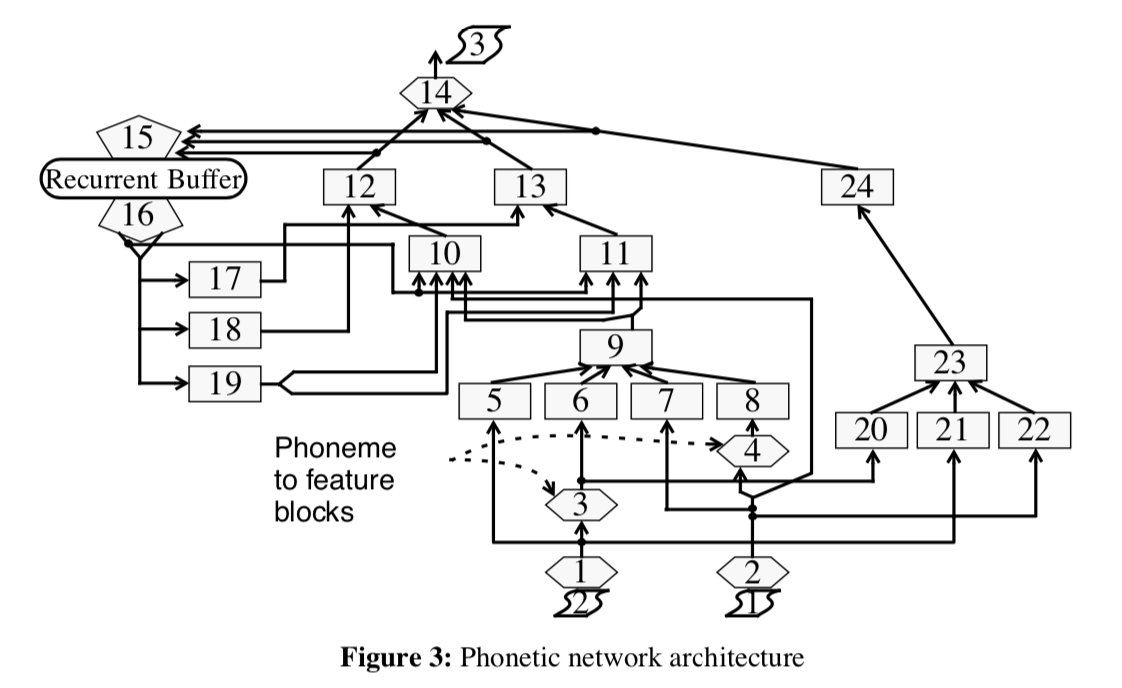
phonetic-network
系统效果
3.1 语音质量和自然度
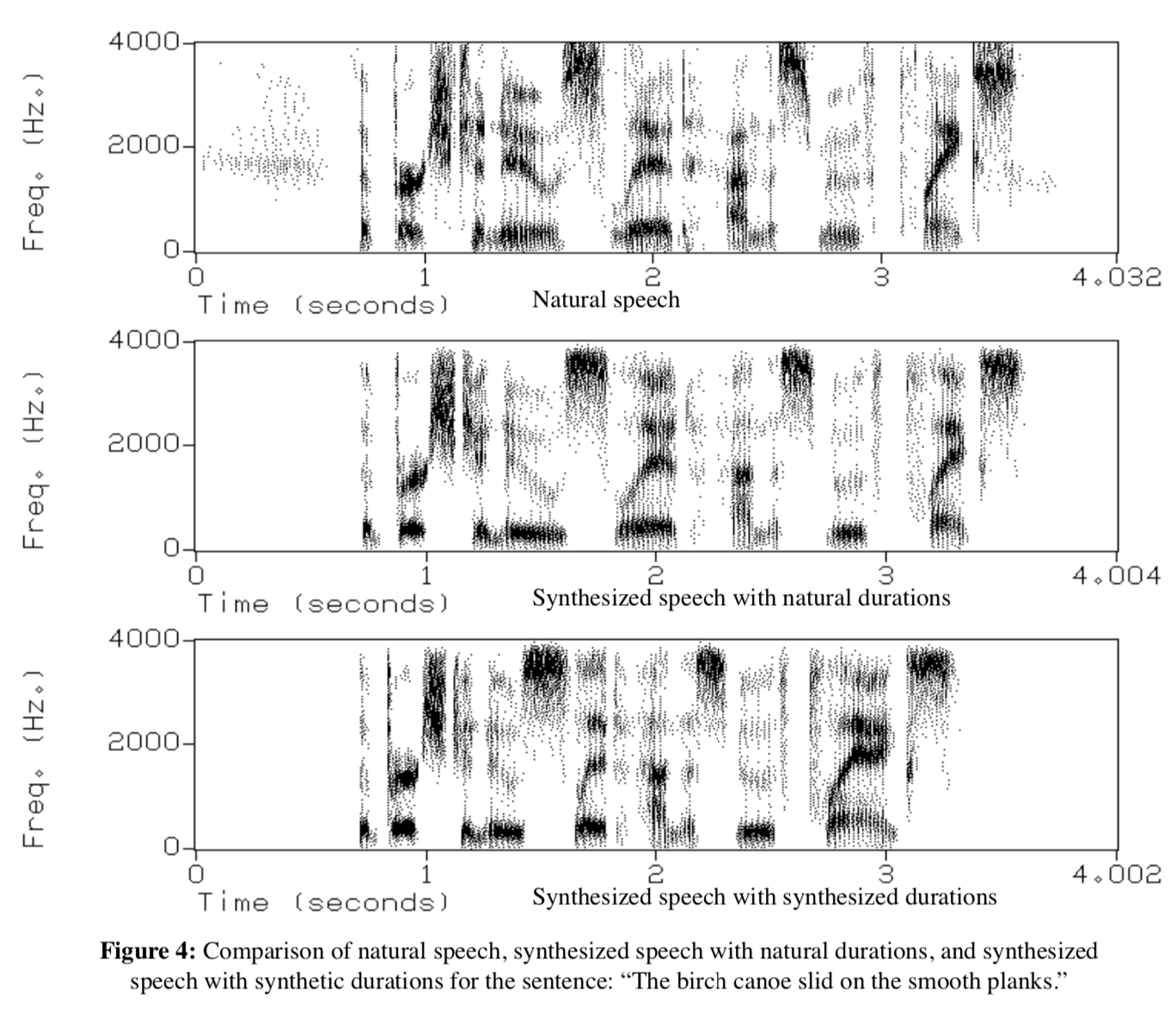
tts-nn-exp-results
上图展示了GT语音频谱和系统生成的语音频谱(生成的频谱没有采用ToBI标注系统)。为了对比更加清晰,有两种合成语音频谱被展示出来。第一种,phonetic 特征是网络预测的,而duration是真实的,为了仅仅展示phonetic network的效果。第二种,duration和phonetic都是预测的。对比实验发现,在语音接受度(Acceptability)上,本方法生成的质量远好于其他的系统。在片段的拟人度方面(Segmental Intelligibility),本方法仍旧有提升空间,而本次试验中的较差的数据可能是由于缺少单字语音样本所导致的。
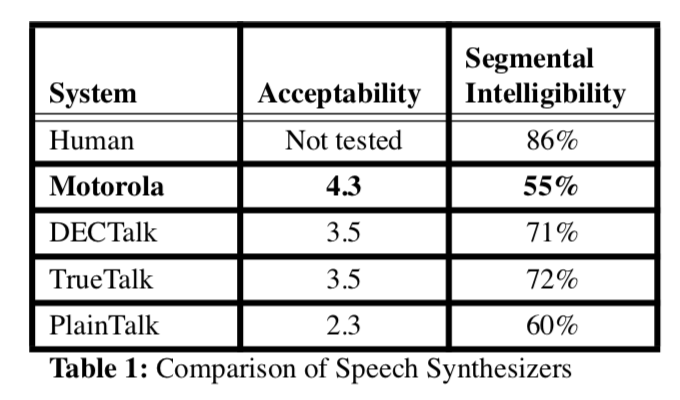
tts-nn-table1
实时合成
最开始模型是在Sun SPARCstation平台来通过ANSI C语言实现的。最近这个被插入到Power Macintosh 8500/120,PowerPC快速的乘法和加法使得合成器能够实时合成。
结论
本方法从Acceptability角度来看,是优于传统算法的,但是仍旧可以有一些提升,如数据库可以扩充,来获得更多的音调变化,包含更多的音素上下文特征,数据库可以包含更多的短语,单字,和长段的语句。在coder、network architecture、和训练方法上也可以做出一些提升。