低资源语种序列-序列语音合成无监督学习方法
Abstract
待解决问题:近些年,包含attention机制的序列-到-序列在TTS领域获得了广泛的成功。这些模型能够以一个大的标注的语料库来生成近似人的语音。
解决方案:然而,准备这样一个大的数据集是昂贵且耗费人力的,为了解决数据依赖的问题,我们提出了一种创新性的无监督预训练机制。具体来讲,首先,我们采用VQVAE模型来从大规模公开发表的,未标注的数据中抽取无监督语言单元。然后,我们采用<无监督语言单元,语音>对来预训练序列-序列TTS模型。最终,我们采用目标说话人的小数据量的
实验结果:主观和客观实验结果均显示,我们提出的方案可以采用相同数量的成对训练数据,合成更加智能化和自然的语音。除此之外,我们将我们提出的方案延伸到假设的低资源语言中,采用客观评估方法,验证模型的有效性。
Introduction
序列到序列的TTS模型由一个编码器-解码器-attention的框架组成,能够生成自然语音。然而,训练这些S2S TTS模型需要成百上千的标注语音来生成近似人声的语音。尽管少量的数据需要被用来生成类人的语音,它限制了整体的自然度,并且模型容易造成不希望的错误。
尽管收集一个这样一个大型的标注语音语料库是昂贵的,耗费成本的,研究者开始调研TTS中数据的有效性。一些学者集中于采用少量数据集迁移TTS模型到新说话人。一些调研采用Speaker embeddings来在TTS中建模speaker identities。一些也探索使用一个speaker embeddings的组合并且fine-tune。一些人甚至致力于zero-shot 说话人自适应研究。
其他的一些学者探索通过通用数据来建模TTS模型。一些人尝试采用传统TTS的技术,将分布式的文本或语言信息引入TTS。一些人采用ASR数据或者通过数据筛选或分析找到的已有数据数据来训练TTS模型。最近,有学者提出了一个简单但是有效的半监督学习方法来仅仅采用语音预训练端到端TTS中的decoder。
目前有一些工作在研究低资源语种TTS的数据有效性,并且显示,训练一个多语种的统计参数语音合成方式,能够将adaption迁移到有小数据量的新语言。最近的工作调查显示从高资源的语种语言,迁移到低资源的语言也是有效的。
本文目的在于通过利用大量的,公开的,未标注的语音数据,来减轻S2S TTS训练中的数据需求量。我们提出了一个训练Tacotron2的无监督学习框架。具体来讲,我们首先通过VQ-VAE模型来从未标注语音中抽取无监督语言单元。然后通过使用<无监督语言单元,语音>对来预训练Tacotron。最终,我们采用目标说话人少量的
我们的工作与[20]Y.-A Chung (ICASSP 2019) “Semi-supervised training for improving data efficiency in end-to-end speech synthesis”相关。然而,区别如下:
- 我们的方法采用无监督学习方法抽取类似于音素的语言单元,使得有可能预训练整个TTS模型,然而[20]分开预训练模型的几个部分;
- 我们也在假设的低资源语言上,证实了方法的可行性;
- 最后,我们在实验中主要采用公开数据集,因此能够很容易被复现。
提出的方案
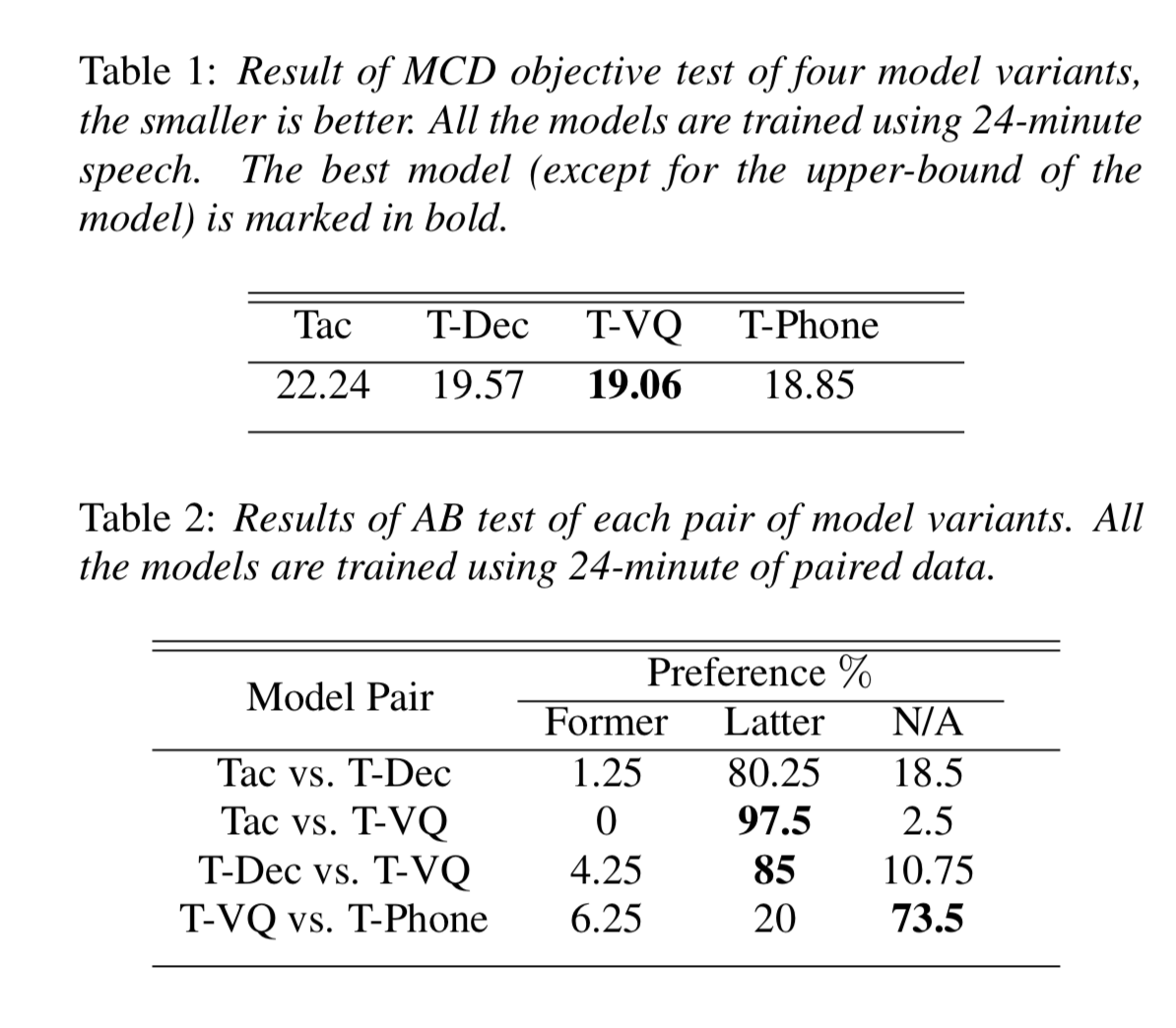
我们采用一个baseline Tacotron的模型架构,其中采用location-sensitive attention 和 从文本中生成的音素序列。为了将预测的频谱转换为语音,我们采用Griffin-Lim算法for fast experiment cycles,因为我们是关注于数据有效性的问题,而不是生成高保真的语音。在baseline模型中,模型是从0开始训练的,意外着模型的所有parameters全都是被paired data来训练的。

vqvae-algorithm
2.1 半监督预训练
在baseline Tacotron model中,模型应该同时学习到文本声学表示和他们之间的对齐。[20] 提出了两种模型预训练的方法来利用外部的文本和声学信息。对于文本表示来说,他们通过外部的word-vectors预训练了Tacotron的encoder,对于声学表示,他们通过未标注的语音,预训练了decoder。
[20]然后采用paired data来fine模型,在这一步,模型集中于学习textual representations和acoustic ones之间的对齐。
2.2 无监督学习---预训练
尽管[13] 展示出提出的半监督预训练的方法能够合成更加智能的语音,但是它也发现同时分开训练编码器和解码器不会相较于仅仅预训练解码器带来更多提升。然而,仅预训练解码器和fine-tune整个模型有一个不匹配。为了避免这种不匹配带来的潜在损失,并且进一步通过仅仅使用语音来提高数据有效性,我们提出从未标注语音中抽取无监督语言单元来预训练整个模型。
我们提出的方法提供在了算法1中。整体的框架包含两个模型:一个无监督模型,用来抽取类似于音素的语言特征,和Tacotron模型。
2.2.1 无监督语言单元
无监督语言表示在表示学习和特征解耦两个方面都带来了很大的提升。在它们之间,离散表示在语言和语音社区是较为流行的,因为直观上来看,语言和语音都是由有限的离散单元来组成的,例如文本中的字母和语音中的音素。本文利用VQ-VAE模型作为离散语言单元的抽取器。
在这种情况下,VQ-VAE模型作为一个类似于ASR的识别模型。然而,VQVAE模型和ASR模型的主要区别是VQVAE模型以一种无监督的方式来训练,然而ASR是采用一种有监督的方式。这种区别只要考虑到低资源语种的问题就会有所影响。当我们没有一个用于低资源语种的ASR模型时,这种提出的无监督方法对于提取低资源语种的语言表示单元是有意义的。
VQ-VAE模型有采用了一个encoder-decoder的框架,和一个码书(codebook dictionary)$e = C D \(,其中\)C\(是字典中隐状态嵌入的数量,\)D\(是每一个嵌入的维度。编码器\)E$输入原始语音波形 \(x_{1:T}=x_1, x_2, ..., x_T\)作为输入,并且生成编码状态\(z_{1:N}=E(x_{1:T})\),其中\(N\)依赖于文本时间长度\(T\)和编码器中下采样层的数量。然后,连续的隐状态表示\(z_{1:N}\)能够被映射到\(\hat z_{1:N}\)通过在字典中找到最近的预定义的离散嵌入\(\hat z = e_k\),其中\(k=argmin_j||z-e_j||\),\(e_j\)是在码书中的第\(j\)个嵌入,并且\(j\in 1,2,...,C\)。最终,隐嵌入\(\hat z_{1:N}\)和说话人嵌入\(s\)被一同输入到解码器\(D\)来重构语音波形\(\hat x = D(\hat z, s)\)。
因为模型输入和输出是相同的,模型能够以一种auto-encoder的方式来训练。然而,梯度不能够通过\(argmin\)计算来获取,因此直接采用梯度估计来近似。因此模型的整体loss为: \[ L = -log(x|\hat z(x), s) + ||sg(z(x))-e_j||^2_2 + \beta \ast ||z(x) - sg(e_j)||^2_2 \] 其中第一项是negative log-likelihood用来更新整体模型的;第二项更新码书字典,其中 \(sg\)指代stop-gradient计算;第三项,指代承诺损失,鼓励编码器输出\(z\)来接近于码书嵌入,超参数\(\beta\)是用于给第三项增加一个权重。
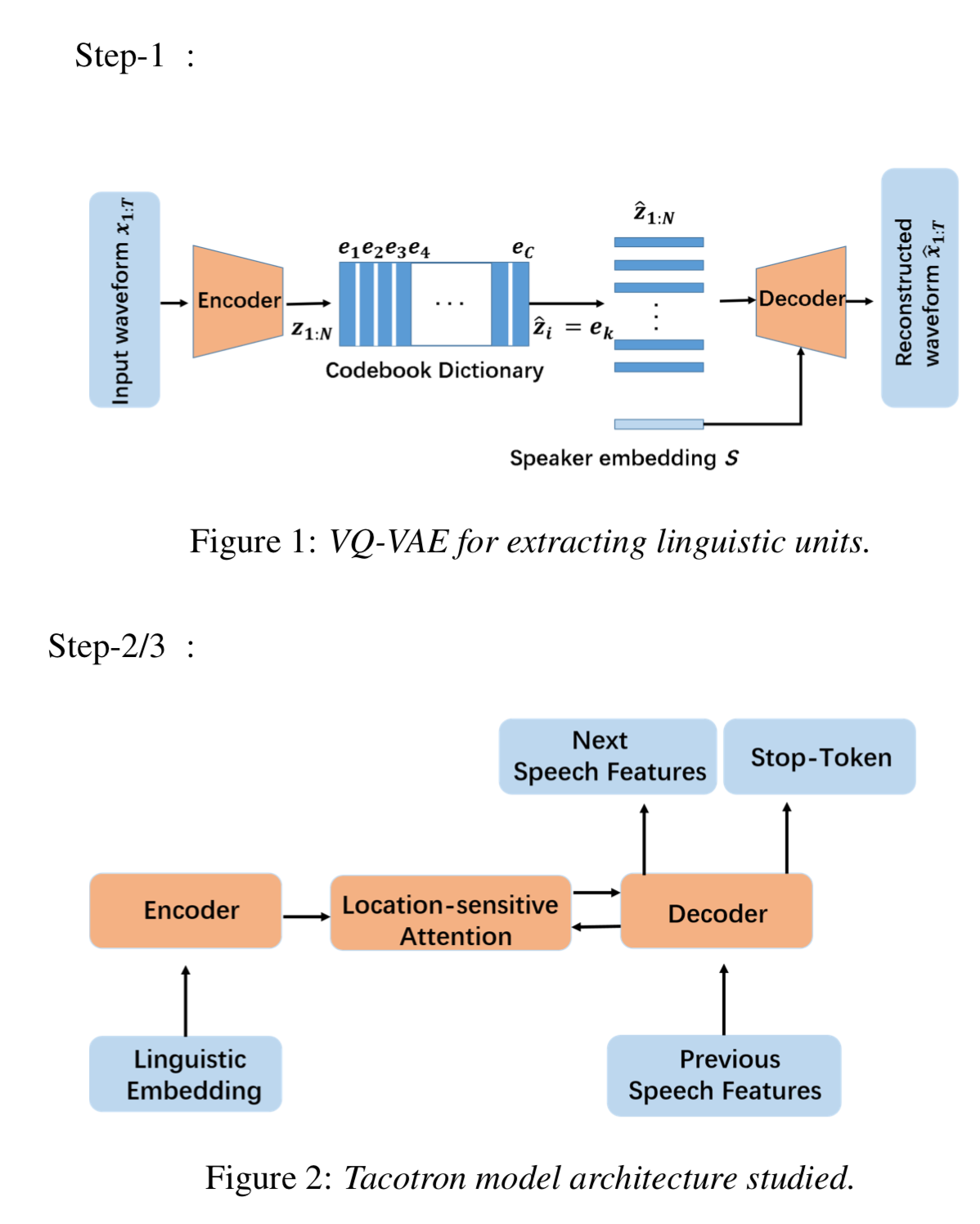
vqvae-t2
2.2.2 Tacotron预训练和fine-tune
在VQVAE被训练后,我们抽取每句话的无监督语言单元。然后给无监督语言单元随机处理化一个嵌入表,通过查表得到的语言嵌入序列被用作Tacotron的输入。因此,我们能够通过
在模型被预训练后,我们采用一些paired语言数据来fine-tune模型。在这一步中,模型的输入是从文本中得到的音素序列。
Experiment
3.1 实验设置
数据集:LJSpeech
VQ-VAE:与“Unsupervised speech representation learning using WaveNet autoencoders”相似的网络结构
当训练VQ-VAE的时候,我们采用39维MFCC作为模型输入。在我们调研学习后,码书的大小是256,并且每一个码书embedding的嵌入是64维。jitter rate 和\(\beta\)是0.12和0.25。
[20]发现24-分钟语音是刚好不能构建一个Tacotron系统的语音的最小最大值。因此,我们集中于对比不同的仅仅采用24分钟paired数据训练的模型。
3.2 在24-min数据上的结果
模型如下:
- Tac:仅仅采用LJSpeech训练的Tacotron
- T-Dec: 以半监督学习方式,采用外部数据集训练的Tacotron,然后在LJSpeech上fine-tune
- T-VQ: 以本文提出的学习方式,采用外部数据集训练的Tacotron,然后在LJSpeech上fine-tune
- T-phone: 以监督学习方式,采用外部数据集训练的Tacotron,然后在LJSpeech上fine-tune,意指模型的上限。
外部数据集:VCTK
其中在预训练T-Dec和T-VQ的时候,仅仅采用语音数据,对于T-Phone,采用VCTK的文本语音对数据。
本文采用了客观和主观两种方式,来评估实验结果。对于客观方式,我们采用了Dynamic-time-warping Mel-cepstral Distortion(DTW MCD),度量了合成语音和真实语音之间的距离,越小越好。我们采用了大约20分钟的unseen数据作为评估数据。对于主观评估方式,我们采用20条unseen utterances执行了一系列的AB tests。20 raters(10男10女)是地道的普通话中文者,英文熟练。
3.2.1 MCD客观评估
vqvae-results
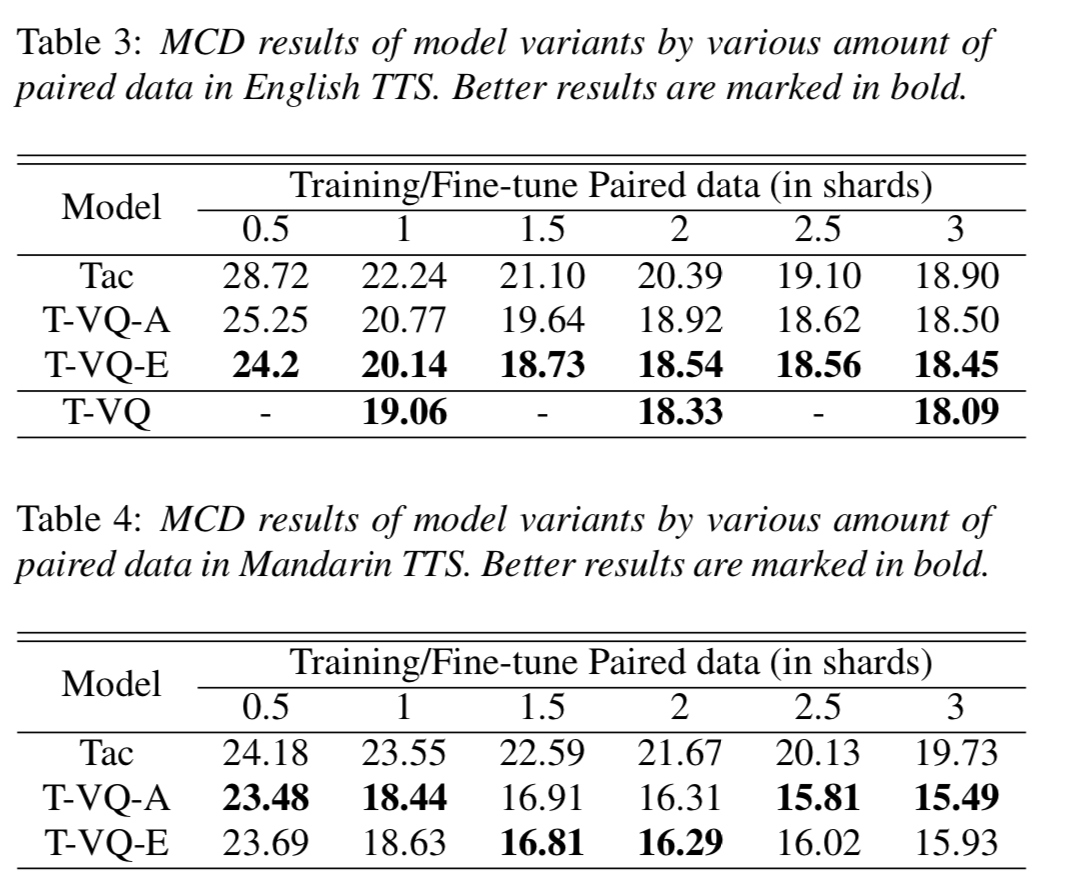
MCD结果如上表1所示,如[20]中所描述的,仅仅预训练decoder能够降低MCD。然而,提出的方法实现了最好的效果,MCD相较于baselineTacotron低了14.3%。我们也发现了T-VQ的结果十分接近Upper bound(T-Phone)
3.2.2 AB偏好主观测试
AB tests的结果如表2所示,可以清晰看出预训练的技巧能够帮助提升模型性能。在Tacotron和预训练模型(T-Dec / T-VQ)中有一个较大的表现差距。我们发现采用LJSpeech数据从0开始训练模型能够很难得到智能数据,部分原因是LJSpeech的数据集质量也不是足够高。
在T-Dec和T-VQ的AB Test中,T-VQ获取了更好的表现,从不正式的听测中,我们注意到T-Dec合成的语音在智能性上更加中庸,T-VQ的智能性会更好。这显示通过无监督语言单元和语音来进行预训练能够进一步提升模型性能。原因是在提出的预训练的配置中,模型不仅仅能够学习到声学表示,也能够学习到对齐信息。尽管无监督的语言单元没有在fine-tune中使用,提出的预训练的方法对于textual representation learning也是有效的,因为这些无监督的语言单元被证明很像音素。
在Tac-VQ和T-phone的对比中,大多数的raters没有选择,但其中还是有20%的人在二者之中选择T-Phone。
3.3 在其他数量数据上的实验结果
实验结果表示:
- 在使用24min数据时,Tacotron与其他三个模型有很大差异
- 随着数据量增大,差异缩小,证明了pre-training的作用在降低
- T-VQ和T-Phone始终比Tac和T-Dec的方法效果要好
3.4 低资源语种的实验结果
本节验证提出的方法在2种低资源语种的实验效果。假设English和Mandarin Chinese是两种低资源语种。主要为了解决以下两个问题:
- 此种方法能否在这种情境下提升数据有效性?
- 那些预训练的语种对于提出的方法更有效?与目标语种音素相近的还是不相关的?
目标语种,英语的语料是LJSpeech,中文是内部数据集Xiaomin,新闻风格,女性。
训练VQ-VAE和预训练Tacotron的语言包含以下几种:韩语,日语,西班牙语,法语,德语。我们仅仅利用语音数据来训练VQ-VAE和预训练Tacotron。在训练VQ-VAE的时候,仅做了一个改动:码书的大小从256改变到512,因为这里采用了多语种的数据集。三种模型衍生如下:
- Tac:通过LJSpeech或者Xiaomin训练的Tacotron;
- T-VQ-A:以本文提出的学习方式,采用亚洲数据集(韩语、日语)训练的Tacotron,然后在LJSpeech / Xiaomin上fine-tune
- T-VQ-E:以本文提出的学习方式,采用欧洲数据集(西班牙语,韩语,德语)训练的Tacotron,然后在LJSpeech / Xiaomin上fine-tune
low-resource-languages
To alleviate the burden of raters,我们仅仅评估MCD值。如表3和表4所示。我们提出的预训练的方式,能够有效提升合成语音的质量,对于低资源语种来说很有价值,因为语音的收集成本十分高。
除此之外,在English TTS中T-VQ-E结果好于T-VQ-A,在普通话实验中,T-VQ-A slightly out-performs T-VQ-E。这个结果展示出了,采用音素相近的语言来进行模型预训练,是更加有效的。此外,我们发现了随着fine-tune数据的增多,MCD的下降,这个结果与上一节结果是相似的。最后,通过对比English TTS中最好的模型T-VQ-E模型,和上一节中的T-VQ模型,我们发现这里尽管使用音素相似的语言,仍然会存在一个不可忽视的gap。
结论
本文提出了一种在序列-序列TTS中,提升数据有效性的无监督学习方案。本方案首先从大规模未转译外部数据中,抽取文本和声学特征表示。然后在采用S2S模型来训练。具体来讲,采用了此种预训练的方式,Tacotron能够采用较少的数据,生成较好的语音。尽管我们是采用Tacotron来进行试验的,我们坚信我们的方法在其他的sequence-to-sequence模型中,也应该有效。我们也证实了此种方法在低资源语种上的有效性,这样的话,不需要目标语种的语音,我们的方法能够提供一个显著的效果提升。尽管,我们假设了两种低资源语种,但我们相信此种方法能够泛化到真实的低资源语种。这个结果给单语种和多语种TTS系统增加了曙光。
未来前进方向:可以尝试其他的无监督学习方式;采用小数据量来adaptation neural vocoders也同样需要被调研。