Unsupervised speech representation learning using WaveNet autoencoders https://export.arxiv.org/pdf/1901.08810
感想
第一次完整的精读完一篇期刊文章,一开始还是自己逐字句翻译的,但后面发现这样太耗费时间了(主要是突然解锁了typora的copy-paste功能),所以这篇文章从模型部分开始主要是Google翻译的。通篇来说论文Idea很容易理解,模型结构主要展示在了图1的模型结构里面。但是后面采用了6页的科学实验来验证这个想法,并且分析这个想法中的每一步细节。总体来讲,与MelGAN这种A类的长篇论文来对比的话,我更青睐于MelGAN的这种论文,是由于读到本文的一些实验细节,并且我尝试从图中去分析实验现象的时候,个人感觉实验现象都相对来说有一些牵强,尽管实验内容很详细,但是没有很好的控制变量,以得到有效的实验结果,并且很多实验结果有点晦涩难懂。(并且这篇文章采用了4个TPU训练了一周,没有资源还是不要轻易去re-train了,或许这个方向也像BERT一样,需要投入大量的资金和精力才能够实现宇宙第一的效果,所以还是建议轻易不要挑战)。所以本次打分:🌟🌟🌟
Abastract
现状:无监督的语音表示学习可以通过对语音进行自编码来实现。目标是从语音中抽取出高层级语义特征,例如,音素id,与语音信号低层级的混淆信息如音高轮廓或者背景噪声无关。
解决方案:因为learned representation 被tuned来仅仅包含音素内容,我们借助于一个高容量的WaveNet decoder来从之前的样本点中推理encoder丢失的信息。除此之外,自编码器模型的行为依赖于被应用到隐状态表示的约束条件。我们将三种variants进行对比:一个简单的dimensionality reduction瓶颈特征,一个高斯VAE,和一个离散的VQ-VAE。
实验分析:我们通过speaker independence,预测音素内容的能力,准确重构独立频谱帧的能力三个方面来评估learned representation的质量。除此之外,对于采用VQ-VAE模型提取的离散编码,我们度量从它们映射到phonemes的难度。我们引入了一个“正则化”的机制,来强迫representations集中于语句的音素内容的建模,并且报告出效果是与Zerospeech 2017 无监督声学单元发现任务的前几名能够匹敌的。
关键字:autoencoder,speech representation learning,unsupervised learning, acoustic unit discovery
Introduction (1 page)
Deep learning被高层级表示学习算法所触发,如stacked Restricted Boltzman Machines和Denoising Autoencoders. 然而,近期在计算机视觉,机器翻译,语音识别和语言理解的突破,依赖于大规模的标记数据集,而几乎没有利用无监督表示学习。这样有两点缺陷:1)大规模人工标注的数据集的需求经常使得deep learning models的发展十分昂贵。2)尽管一个深度模型能够擅长于解决一个given task,但是这种方法对于问题域产生有限的启发,主要的启发是从显著输入特征的可视化中组成的,一种仅仅能够应用于问题域的策略,很容易被人类所解释。
本文集中于评估和提高无监督语音表示学习。具体来讲,我们集中于从音素内容中学习能够区分说话人特征(特别是说话人性别和id)的表示,这种特性类似于从语音识别器学习到的内部表示特征。这样的特征在多个任务中都有价值,例如低资源语音识别(当仅仅小数据量的标签训练数据被提供)。在这种情景下,有限的数据可能足够基于无监督发现的表征训练一个声学模型,但是对于训练一个声学模型或者以一种有监督的方式来学习数据表征是不充足的。
我们集中于将自编码器学习到的表征应用到原始语音和频谱特征,并且采用LibriSpeech来调研learned representations的质量。我们tune learned 隐状态表征来仅仅编码phonetic content并且移除其他的混淆特征。然而,为了做信号重构,我们采用了一个自回归的WaveNet模型作为解码器, 来推理被编码器拒绝掉的信息。这个解码器的作用是一个inductive bias,使得编码器无需使用它的capacity来表示低层级细节,而是允许编码器集中于高层级的语义特征。我们发现当使用ASR特征,如MFCC作为输入,原始语音作为decoder targets的时候,能够得到最好的representations. 这强迫系统学习生成在特征抽取的过程中,被移除的sample level的细节。此外,我们注意到VQ-VAE模型可以生成在声学内容和说话人信息之间最好的分割。我们调研VQ-VAE的可视化直观性,通过将它们映射到phonemes,展示了模型超参数在可视化上的影响,并且提出了一个新的正则化机制,能够提高latent representation -> phonetic content 的质量。最终,我们展示了模型在ZeroSpeech 2017声学单元发现任务上的有效性,度量了当一句话的音素发生了最小改变的时候,learned representation的区分度。
Representation learning with neural networks (1.5 page)
神经网络是高层级信息处理的模型,常用多层计算单元来进行实现。每一层可以被理解为是一个特征抽取器,它的输出被传递到上游单元。特别是在图像领域,神经网络学习到的特征可以被展示出一个可视化原子的层级结构,能够与可视化的脑皮层组织在一定程度上匹配。相似地,当应用到语音领域时,神经网络倾向于在音乐,语音的低层级上学习到听觉的频谱特征。
A. 有监督特征学习
神经网络能够采用有监督或者无监督的方式学习到数据表征。在有监督的情况下,从大规模数据集中学习的特征是能直接被使用的,除了data-poor tasks。例如,在视觉领域,ImageNet中发现的特征也会被用作其他计算机视觉任务的输入表示。相似的,语音社区采用从在音素预测任务的网络中抽取的瓶颈特征也可以作为ASR的特征表示。相似的,在NLP,可以从机器翻译或者语言推理任务训练的网络抽取通用文本特征。
B. 无监督特征学习
在这篇文章中,我们关注于无监督特征学习。因为没有训练标签,所以我们采用自编码器,i.e. 网络任务是重构她们的输入。自编码器采用一个encoding network来抽取隐状态表示,然后这个隐状态表示被输入到一个解码器网络来恢复原始数据。理想情况下,隐状态表示保留了原始数据的显著特征,是容易分析和解决的,e.g. 通过解耦数据中不同因子的变化,并且摒弃虚假特征(噪音)。这些渴望的性质典型是通过一个包含正则化技巧和contraints or bottlenecks的明智的应用。因此,自动编码器学习到的表示会受到两种相互竞争的力量的影响。一方面,它会提供给解码器以必要信息为了完美的重构,因此会在隐状态提取尽可能多的输入数据特征模式。另一方面,contraints限制了一些信息需要被摒弃,避免了latent representation颠倒到微不足道。因此,瓶颈特征对于强迫网络学习到一个非-微不足道的数据转换是必要的。
降低隐表示的维度是应用到隐向量的最基本的约束,autoencoder扮演作为一个非线性的variant of 线性低维数据映射,如PCA和SVD。然而,这样的表示是很难直观解释的,因为输入的重构完全依赖于所有的隐状态特征。对比来讲,字典学习的技巧(dictionary learning techniques),例如sparse和non-negative decompositions,从一个大池子里使用了小数据量的挑选特征来表示每一种输入特征,能够帮助他们的可解释性。基于VQ的离散特征学习能够被视为sparseness的一种极端形式,其中,重构仅需使用字典中唯一的一个元素。
VAE提出了一种特征学习的不同的表示方式,follows 概率框架。自编码网络结构是从一个latent variable generative model衍生的。首先,一个latent vector \(z\) 被从一个先验概率\(p(z)\) 采样(典型情况下,是一个多维的正态分布)。然后,数据采样点\(x\)是采用一个深度解码器神经网络来生成的,神经网络的参数是\(\theta\), \(x \sim p(x|z;\theta)\)。然而,在最大似然估计训练中,计算精准的后验概率分布\(p(z|x)\)是很困难的。取而代之的是,VAE给后验概率引入了一个变分估计,\(q(z|x;\phi)\),这个变分估计是通过一个参数为\(\phi\)的编码器神经网络建模的。因此VAE模拟了一个传统的自编码器的过程,其中,其中,编码器生成隐状态的分布,而不是deterministic encodings,然而解码器是从这个分布生成的样本上进行训练。编码和解码网络是联合训练的,以最大化一个lower bound on the log-likelihood of data point x: \[ J_{VAE}(\theta, \phi; x) = E_{q(z|x;\phi)}[log p(x|z;\theta)] - \beta D_{KL}(q(z|x;\phi)||p(z)) \] 以上公式中的两个terms分别是autoencoder的重构损失,以及一个对隐状态应用了penalty term。特别地,KL散度表示了网络中的信息数量,即隐表示携带的有关数据样本的信息数量。因此它作为一个隐表示的一个信息瓶颈,其中\(\beta\)控制了重构质量和表示相似度之间的trade-off。
VAE目标函数的另一种表示方式明确的限制了隐表示的信息: \[ J_{VAE}(\theta, \phi; x) = E_{q(z|x;\phi)}[log p(x|z;\theta)] - max(B, D_{KL}(q(z|x;\phi)||p(z))) \] 其中常数\(B\)是指\(q\)中自由信息的数量,因为模型仅仅会被惩罚,如果它比隐状态的先验损失传递了超过B的信息。
近期提出的一种VQ-VAE的方式,用确定的量化特征,取代了连续和随机的隐向量。VQ-VAE维护了一些原型向量\(e_i, i=1,...,K\)。在前向计算的过程中,编码器生成的representations被原型向量中最近的一个替代。Formally, 让\(z_e(x)\)是编码器在量化之前的输出。VQ-VAE通过 \(q(x)=argmin_i||z_e(x)-e_i||^2_2\)找到最近的原型,并且将其使用作隐状态表征\(z_q(x)=e_{q(x)}\)输入到解码器中。当模型应用到downstream tasks时,learned representation 能够被当作一个distributed representation处理(其中的每一个采样点都被一个连续vector表示),或者一个离散的representation(每个sample都被一个原型ID / token ID表示)。
在反向传播时,loss对于预先量化向量的梯度通过straight-through估计器被估计。 \[ \frac{\partial \mathcal{L}}{\partial z_e(x)} \approx \frac {\partial \mathcal{L}}{\partial z_q(x)} \] In TensorFlow, 可以通过如下公式来实现: \[ z_q(x)=z_e(x)+stop\_gradient(e_{q(x)} - z_e(x)) \] 这些原型,是通过延伸learning objective with terms 来最优化quantization来训练的。原型被强迫与它们所替换的vectors近一些,被称为承诺损失(commitment loss),用于鼓励编码器生成靠近原型的vectors。如果没有承诺损失,VQ-VAE 训练可以通过生成unbounded magnitude来发散。因此,VQ-VAE模型的loss包含如下三项,NLL(negative log-likelihood) of the reconstruction, (use the straight-through estimator来反向传播), 2个VQ-相关的loss, 2) prototype 与 assigned vectors 之间的距离,3)commitment cost \[ \mathcal{L} = log p(x|z_q(x)) + ||sg(z_e(x)) -e_{q(x)} ||^2_2 + \gamma|| z_e(x) - sg(e_{q(x)})||^2_2 \] 其中,\(sg(\cdot)\)是stop gradient,来在反向传播的时候,清空gradient。
VQ-VAE中的量化是一个information bottleneck。编码器可以被理解为一个概率模型,puts all probability mass on the selected discrete token (prototype ID). 假设K个tokens服从均匀先验分布(uniform prior distribution),KL 散度是常数,并且等于\(log K\)。因此KL项不需要被包含在VQ-VAE训练标准中,取而代之的,成为了一个与prototype inventory大小相关的超参数。
VQ-VAE被定性地展示出能够学习到一个区分开文本内容和说话人id的representation。除此之外,discovered tokens能够在有限的设置下被映射到phonemes。
C. 序列数据的自编码
序列数据,如语音或文本,经常包含了能够被生成模型探索的局部依赖信息。事实上,序列数据的纯自回归模型,基于历史数据预测下一个观测点,是非常成功的。对于文本来说,很容易想到与n-gram模型相关的卷积神经语言模型。相似地,WaveNet是一个时域采样点的自回归模型。
这样的自回归模型的缺点是,它们不能够生成数据的隐空间表示。然而,可以将如此的生成模型与一个隐表示抽取器来结合使用。目前有两种解决方案,1是编码器能够处理整句话术,生成一个隐状态向量,然后输入到自回归解码器中,2是编码器能够周期性的生成隐状态特征来输入到解码器中。我们采用方案2。
训练这样的latent variable和自回归的混合模型容易造成隐空间坍塌,其中,解码器学习时,忽略受限隐表示,仅仅使用自回归的无约束信号。对于VAE来说,可以给KL项增加一个权重来阻止这种隐空间坍塌,并且使用free-information formulation。VQ-VAE 自然地对潜在崩溃具有弹性,因为 KL 项是一个超参数,它没有使用给定模型的梯度训练进行优化。
Model description (2 pages)
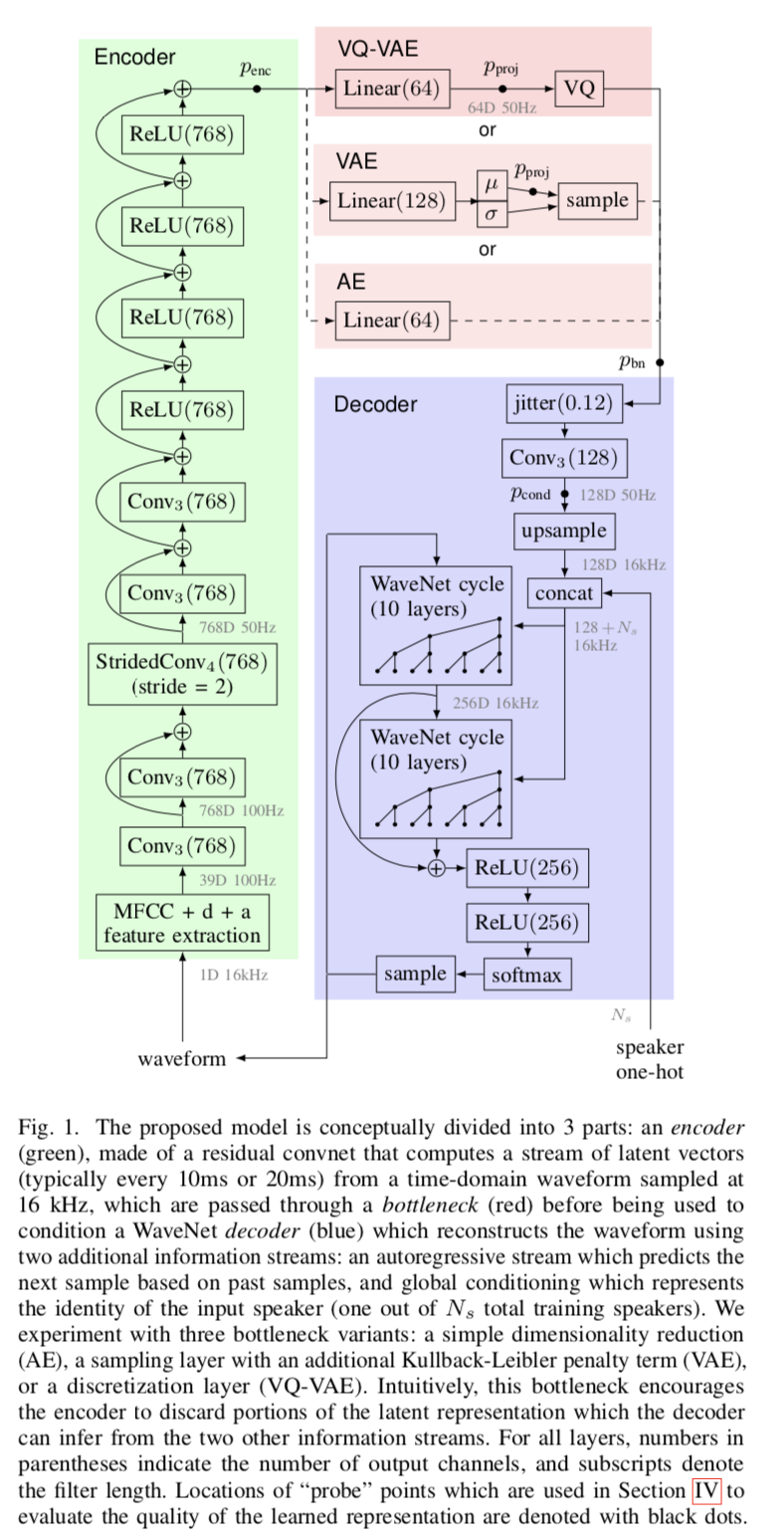
VQVAE-model
模型结构如图1所示。编码器(为了keep the autoencoder viewpoint, encoder可以理解为一层固定的信号处理层)读取原始语音采样点序列,或者是语音特征, 抽取出一个隐向量序列(a sequence of hidden vectors),被输入到一个bottleneck来成为一个隐表示序列(a sequence of latent representations)。latent vectors的哪一个frequency 被抽取是通过number of strided convolutions applied by the encoder来决定的。
解码器通过采用WaveNet来条件于encoder抽取的latent representation和一个speaker embedding来重构语音。解码器显式条件于speaker identity使得encoder不需要在latent representation中捕捉说话人信息。具体来说,解码器1) 输入encoder outputs,2)选择性地应用随机正则化到latent vectors. 3)使用卷积函数来将neighboring time steps抽取的latent vectors 整合, 4)上采样至目标采样率。 语音采样点是采用WaveNet来进行重构的,整合了所有的条件信息,包括:autoregressive information about past samples, global information about the speaker, latent information about past and future samples extracted by the encoder. 我们发现encoder's bottleneck和提出的regularization在提取数据表示时是关键的。如果没有bottleneck, 该模型倾向于学习一种简单的重建策略,该策略可以逐字复制未来的样本。我们还注意到编码器与说话人无关,只需要语音数据,而解码器也需要说话人信息。
我们考虑了三种bottleneck:1)简单的降维,2)具有不同潜在表示维数和不同容量的高斯 VAE,3)具有不同数量量化原型的 VQ-VAE。所有bottleneck都可选地跟随下面描述的 dropout 启发的时间抖动正则化(time-jitter regularization)。此外,我们使用原始波形、对数梅尔滤波器组(log-mel filterbank)和梅尔频率倒谱系数 (MFCC) 特征对不同的输入和输出表示进行试验,这些特征丢弃了频谱图中存在的音高信息。
A. Time-jitter regularization
是一个类似于RNN中的Zoneout dropout的本文自主创新的正则化的方法,用于防止过拟合,详情不作描述。
实验 (6页)
我们在两个数据集上评估模型:LibriSpeech(clean subset)和ZeroSpeech 2017 Contest Track 1 data. 两个数据集的共性是:多说话人,清晰,的read speech(sourced from audio books)以16 kHz录制。除此之外,ZeroSpeech Challenge控制了每个说话人的数量,主要的数据是被其中的几个说话人来讲述的。
第 IV-B 节中介绍的初始实验比较了不同的bottleneck变体,并确定模型在图 1 所示的四个不同探测点处生成的连续潜在表示中保留了来自输入音频的哪些类型的信息。使用在每个探测点计算的表示,我们测量几个预测任务的性能:音素预测(每帧准确度)、说话人身份和性别预测准确度,以及频谱图帧的 L2 重建误差。我们确定 VQ-VAE 学习了在语音内容和说话者身份之间具有最强解缠结的潜在表示,并在以下实验中关注该架构。
在第 IV-C 节中,我们通过将每个离散标记映射到小标记数据集 (LibriSpeech dev) 强制对齐中最常见的对应音素来分析 VQ-VAE 标记的可解释性,并报告单独集上映射的准确性 (LibriSpeech 测试)。 直观地说,这捕获了单个令牌的可解释性。
然后,我们将 VQ-VAE 应用于第 IV-D 节中的 ZeroSpeech 2017 声学单元发现任务 [20]。 此任务评估表示相对于语音类的判别力。 最后,在第 IV-E 节中,我们测量了不同超参数对性能的影响。
A. 默认的模型超参数
我们最好的模型使用 MFCC 作为编码器输入,但在解码器输出处重建原始波形。 我们使用每 10 毫秒(即以 100 Hz 的速率)提取的标准 13 个 MFCC 特征,并用它们的时间一阶和二阶导数进行扩充。 这些特征最初是为语音识别而设计的,并且大多对音频信号中的音调和类似的混淆细节是不变的。 编码器有 9 个层,每层使用 768 个单元和 ReLU 激活,组织成以下组:2 个预处理卷积层,过滤器长度为 3 和残差连接,1 个步幅卷积长度减少层,过滤器长度为 4,步幅为 2(对信号进行下采样 因子二),然后是 2 个长度为 3 的卷积层和残差连接,最后是 4 个具有残差连接的前馈 ReLU 层。 产生的潜在向量以 50 Hz(即每隔一帧)提取,每个潜在向量取决于 16 个输入帧的感受野。我们还使用了一个具有两个长度缩减层的替代编码器,它以 25 Hz 的频率提取潜在表示,接受场为 30 帧。
当未指定时,潜在表示为 64 维,适用时限制为 14 位。 此外,对于 VQ-VAE,我们使用推荐的 γ = 0.25 [19]。
解码器应用了随机时间抖动正则化(参见第 III-A 部分)。 在训练期间,每个潜在向量被替换为它的任何一个邻居,概率为 0.12。 抖动的潜在序列通过具有滤波器长度 3 和 128 个隐藏单元的单个卷积层,以混合相邻时间步长的信息。 然后对该表示进行 320 次上采样(以匹配 16kHz 音频采样率),并与表示当前说话者的单热向量连接以形成自回归 WaveNet 的调节输入。 WaveNet 由 20 个因果扩张卷积层组成,每个层使用 368 个带有残差连接的门控单元,组织成两个“循环”,每层 10 层,扩张率为 1,2,4,...,29。 调节信号分别传递到每一层。 使用跳过连接将来自 WaveNet 每一层的信号传递到输出。 最后,信号通过 2 个 ReLU 层,256 个单元。 应用 Softmax 来计算下一个样本概率。 我们在 mu-law 压扩后使用了 256 个量化级别。
所有模型都在从训练数据集中均匀采样的 64 个序列的小批量上训练,长度为 5120 个时域样本(320 毫秒)。 在 4 个 Google Cloud TPU(16 个芯片)上训练一个模型需要一周时间。 我们使用 Adam 优化器,初始学习率为 4 × 10−4,在 400k、600k 和 800k 步后减半。 Polyak 平均应用于所有用于模型评估的检查点。
B. Bottleneck comparison
我们在 LibriSpeech 上训练模型,并分析在自动编码器瓶颈周围的隐藏表示中捕获的信息,如图 1 所示:
- \(p_{enc}\) (768 dim) encoder output prior to the bottleneck,
- \(p_{proj}\) (64 dim) within the bottleneck after projecting to lower dimension,
- \(p_{bn}\) (64 dim) bottleneck output, corresponding to the quantized representation in VQ-VAE, or a random sample from the variational posterior in VAE, and
- \(p_{cond}\) (128 dim) after passing \(p_{bn}\) through a convolution layer which captures a larger receptive field over the latent encoding.
在每个探测点,我们在四个任务中的每一个上训练具有 2048 个隐藏单元的单独 MLP 网络:对整个片段的说话人性别和身份进行分类(在整个信号中平均汇集潜在向量之后),预测每一帧的音素类(每个潜在向量都制作几个预测),并在每个帧中重建对数梅尔滤波器组特征(再次从每个潜在向量预测几个连续帧)。从信号中捕获高层级语义内容的表示,同时对令人讨厌的低级信号细节保持不变,将具有高音素预测精度和高频谱重建误差。解开的表示还应该具有较低的说话人预测精度,因为该信息明确地提供给解码器调节网络,因此不需要在latent encoding中保留。由于我们主要对发现构建的表示中存在哪些信息感兴趣,因此我们报告了训练性能并且不调整探测网络以进行泛化。
图 2 展示了使用具有不同超参数(latent dimensionality和bottleneck bitrate)的三个瓶颈中的每一个的模型比较,说明了信息通过网络传播的程度。此外,图 3 突出显示了使用不同配置获得的语音内容和说话者身份的分离。
图 2 显示,每种瓶颈类型始终会丢弃 \(p_{enc}\) 和 \(p_{bn}\) 探针位置之间的信息,这可以从每个任务的性能降低中得到证明。 瓶颈还会影响前面层的信息内容。 特别是对于简单地降低维数的 vanilla 自动编码器 (AE),\(p_{enc}\) 的说话人预测精度和滤波器组重建损失取决于瓶颈的宽度,更窄的宽度会导致更多的信息在编码器的较低层被丢弃。 同样,与维数和比特率匹配的 VQ-VAE 相比,VQ-VAE 和 AE 在 \(p_{enc}\) 上产生了更好的滤波器组重建和说话人身份预测,这对应于 VQ-VAE 的令牌数量的对数,以及与先验的 KL 散度 VAE,我们通过设置允许的空闲位数来控制。
正如预期的那样,AE 丢弃的信息最少。 在 \(p_{cond}\) 上,表示仍然对说话者和音素具有高度预测性,并且其滤波器组重建是所有配置中最好的。 然而,从无监督学习的角度来看,AE 潜在表示不太有用,因为它混合了源信号的所有属性。
相比之下,VQ-VAE 模型产生的表示可以高度预测信号的语音内容,同时有效地丢弃说话者身份和性别信息。 在更高的比特率下,音素预测与 AE 一样准确。 滤波器组重建也不太准确。 我们观察到说话者信息主要在 \(p_{proj}\) 和 \(p_{bn}\) 之间的量化步骤中被丢弃。 在 \(p_{cond}\) 表示中组合几个潜在向量会产生更准确的音素预测,但额外的上下文无助于恢复说话者信息。 这种现象在图 3 中突出显示。请注意,VQ-VAE 模型对瓶颈维度的依赖性很小,因此我们以默认设置 64 呈现结果。
最后,VAE 模型比简单的降维更好地分离说话人和语音信息,但不如 VQ-VAE。 VAE 比 VQ-VAE 更一致地丢弃语音和说话者信息:在 \(p_{bn}\) 处,VAE 的音素预测不太准确,而其性别预测更准确。 此外,在 \(p_{cond}\) 上结合更广泛的感受野的信息并不能像 VQ-VAE 模型那样提高音素识别。 对瓶颈维度的敏感性(如图 2 所示)也令人惊讶,与较宽的 VAE 瓶颈相比,较窄的 VAE 瓶颈丢弃的信息更少。 这可能是由于 VAE 的随机操作:为了提供与低瓶颈维度相同的 KL 散度,需要在高维度添加更多噪声。 这种噪声可能会掩盖表示中存在的信息。
基于这些结果,我们得出结论,VQ-VAE 瓶颈最适合于学习潜在表示,这些表示捕获语音内容同时对底层说话者身份保持不变。
C. VQ-VAE token interpretability
到目前为止,我们已经使用 VQ-VAE 作为量化潜在向量的瓶颈。在本节中,我们寻求对离散原型 ID 的解释,评估 VQ-VAE 令牌是否可以映射到音素,即语音的潜在离散成分。示例令牌 ID 显示在图 4 的中间窗格中,我们可以看到令牌 11 始终与瞬态“T”音素相关联。为了评估其他标记是否有类似的解释,我们测量了逐帧音素识别准确度,其中每个标记被映射到 41 个音素中的一个。我们使用 460 小时干净的 LibriSpeech 训练集进行无监督训练,并使用来自干净的开发子集的标签将每个标记与最可能的音素相关联。我们通过在干净的测试集上以 100 Hz 的帧速率计算逐帧电话识别准确度来评估映射。使用来自 s5 LibriSpeech 配方 [55] 的 Kaldi tri6b 模型从强制对齐中获得真实音素边界。
表 I 显示了在 LibriSpeech 上获得 VQ-VAE 令牌到音素的最佳准确度的配置的性能。 在两个时间点给出识别精度:在 200k 梯度下降步骤之后,当可以评估模型的相对性能时,以及在模型收敛后 900k 步之后。 我们没有观察到训练时间较长的过度拟合。 为所有帧预测最常见的静音音素将准确度下限设置为 16%。 在完整的 460 小时训练集上有区别地训练以预测具有与 25 Hz 编码器相同架构的音素的模型实现了 80% 的逐帧音素识别准确率,而没有时间减少层的模型将上限设置为 88%。
表 I 表明映射精度随着标记数量的增加而提高,使用 32768 个标记的最佳模型达到 64.5% 的精度。 然而,最大的准确度增益出现在 4096 个令牌时,随着令牌数量的进一步增加,收益递减。 该结果与 Kaldi tri6b 模型中使用的 5760 个绑定三音素状态大致对应。
我们还注意到,增加令牌的数量并不会轻易提高准确性,因为我们衡量的是泛化,而不是集群纯度。 在为每个帧分配不同标记的限制下,由于对我们建立映射的小型开发集过度拟合,准确性会很差。 然而,在我们的实验中,我们始终观察到提高的准确性。
D. 无监督ZeroSpeech 2017声学单元发现任务
ZeroSpeech 2017 语音单元发现任务评估representation区分不同声音的能力,而不是将representation映射到预定义语音单元的难易程度。因此,它是对上一节中使用的音素分类准确度度量的补充。 ZeroSpeech 评估方案使用最小对 ABX 测试,该测试评估模型区分三个音素长语音段对的能力,这些语音仅在中间音素(例如“get”和“得到了”)。我们在提供的训练数据(英语 45 小时,法语 24 小时,普通话 2.5 小时)上训练模型,并使用官方评估脚本对测试数据进行评估。为了确保我们不会过拟合 ZeroSpeech 任务,我们只考虑了在LibriSpeech 上找到的最佳超参数设置(参见第 IV-E 部分)。此外,为了最大限度地遵守 ZeroSpeech 约定,我们对所有语言使用了相同的超参数,在表 II 中表示为 VQ-VAE(每语言、MFCC、\(p_{cond}\))。
在带有足够大训练数据集的英语和法语上,尽管使用了独立于说话人的编码器,但我们取得的结果比顶级参赛者更好。
结果与我们对 VQ-VAE 瓶颈执行的信息分离的分析一致:在更具挑战性的跨说话者评估中,最佳性能使用 \(p_{cond}\) 表示,它结合了瓶颈表示(VQ-VAE)的几个相邻帧 ,(表 II 中的每个 lang、MFCC、\(p_{cond}\)))。 比较说话人内部和说话人之间的结果同样与第 IV-B 部分中的观察结果一致。 在说话人内部的情况下,没有必要从语音内容中分离说话人身份,因此 \(p_{proj}\) 和 \(p_{bn}\) 探测点之间的量化会损害性能(尽管在英语中,通过考虑 \(p_{cond}\) 的更广泛的上下文来纠正这一点)。 在跨说话人的情况下,量化提高了英语和法语的分数,因为丢弃混杂说话人信息的收益抵消了一些语音细节的损失。 此外,丢弃的语音信息可以通过在 \(p_{cond}\) 处混合相邻的时间步长来恢复。
VQ-VAE 在普通话上的表现更差,我们可以将其归因于三个主要原因。 首先,训练数据集仅包含 2.4 小时或语音,导致过度拟合(参见第 IV-E7 节)。 这可以通过多语言训练得到部分改善,如 VQ-VAE,(所有语言,MFCC,\(p_{cond}\))。 其次,普通话是一种声调语言,而默认输入特征 (MFCC) 会丢弃音高信息。 我们注意到在 mel filterbank 特征(VQ-VAE,(所有 lang,\(f_{bank}\),\(p_{proj}\)))上训练的多语言模型略有改进。 第三,VQ-VAE 被证明不会在潜在表示中编码韵律。 比较各个探测点的结果,我们发现普通话是唯一一种 VQ 瓶颈会丢弃信息并降低跨说话者测试制度中性能的语言。 尽管如此,多语言预量化特征产生的精度与相当。
我们不认为需要更多无监督训练数据是一个问题。 未标记的数据非常丰富。 我们认为,需要并且可以更好地利用大量未标记训练数据的更强大的模型比性能在小数据集上饱和的更简单的模型更可取。 然而,增加训练数据量是否有助于普通话 VQ-VAE 学会丢弃更少的音调信息还有待验证(多语言模型可能已经学会这样做以适应法语和英语)。
E. Hyperparameter impact
所有 VQ-VAE 自动编码器超参数都使用多组网格搜索 (grid-search) 在 LibriSpeech 任务上进行了调整,优化了最高的音素识别精度。 我们还在 ZeroSpeech 挑战任务的英语部分验证了这些设计选择。 事实上,我们发现所提出的时间抖动正则化提高了所有输入表示的 ZeroSpeech ABX 分数。 使用 MFCC 或滤波器组特征会产生比使用波形更好的分数,并且当使用更多令牌时,模型始终会获得更好的分数。
- 时间抖动正则化:在表 III 中,我们分析了时间抖动正则化对 VQ-VAE 编码的有效性,并将其与两种 dropout 变体进行比较:常规 dropout 应用于编码的各个维度和 dropout 随机应用于整个 在各个时间步进行编码。 常规 dropout 不会强制模型在相邻的时间步长中分离信息。 Step-wise dropout 促进了跨时间步独立的编码,并且性能比时间抖动略差6。
所提出的时间抖动正则化大大提高了令牌映射的准确性,并扩展了性能良好的令牌帧速率范围,包括 50 Hz。 虽然 LibriSpeech 令牌精度在 25 Hz 和 50 Hz 下相当,但更高的令牌发射频率对于 ZeroSpeech AUD 任务很重要,50 Hz 模型在该任务上明显更好。 这种行为是由于 25 Hz 模型容易忽略短音(第 IV-E6 节),这会影响 ABX 在 ZeroSpeech 任务上的结果。
我们还分析了 VQ-VAE、VAE 和简单降维 AE 瓶颈的四个探测点的信息内容,如图 5 所示。对于所有瓶颈机制,正则化限制了滤波器组重建的质量并提高了音素识别精度 在约束表示中。 然而,在 \(p_{cond}\) 探测点中组合了相邻的时间步之后,这种好处就变小了。 此外,对于 VQ-VAE 和 VAE,正则化会降低性别预测的准确性,并使表示对说话者的敏感度略低。
- 输入表示:在这组实验中,我们使用不同的输入表示来比较性能:原始波形、log-mel 频谱图或 MFCC。 原始波形编码器使用 9 个跨步卷积层,这导致令牌提取频率为 30 Hz。 然后,我们用常规的 ASR 数据管道替换了波形:每 10 毫秒从 25 毫秒长的窗口中提取 80 个对数梅尔滤波器组特征,从梅尔滤波器组输出中提取 13 个 MFCC 特征,两者都增加了它们的一阶和二阶时间导数。 在编码器中使用两个跨步卷积层导致这些模型的令牌速率为 25 Hz。
结果报告在表III的底部。 高级特征,尤其是 MFCC,比波形表现更好,因为按照设计,它们会丢弃有关音高的信息并提供一定程度的说话人不变性。 使用这种简化的表示迫使编码器向解码器传输更少的信息,作为对更多说话者不变潜在编码的归纳偏置。
3)输出表示:我们构建了一个自回归解码器网络,重建滤波器组特征而不是原始波形样本。 受文本到语音系统最近进展的启发,我们实现了一个类似 Tacotron 2 的解码器,在自回归信息流上有一个内置的信息瓶颈,这被发现在 TTS 应用程序中至关重要。 与 Tacotron 2 类似,滤波器组特征首先由一个小的“预网络”处理,我们应用了大量的 dropout 并将解码器配置为并行预测多达 4 帧。 然而,这些修改最多产生 42% 的音素识别准确率,明显低于本文中描述的其他架构。 然而,该模型的训练速度要快一个数量级。
最后,我们分析了解码 WaveNet 的大小对 VQ-VAE 提取的表示的影响。 我们发现整体感受野 (RF) 的影响大于 WaveNet 的深度或宽度。 特别是,当解码器的感受野跨越大约 10 毫秒时,潜在表示的属性会发生很大的变化。 如图 6 所示,对于较小的 RF,调节信号包含更多说话人信息:性别预测接近 80%,而逐帧音素预测准确度仅为 55%。 对于较大的 RF,性别预测准确率约为 60%,而音素预测的峰值接近 65%。 最后,虽然重建对数似然随着 WaveNet 深度提高到 30 层,但音素识别准确度稳定在 20 层。 由于 WaveNet 的计算成本最大,我们决定保留 20 层配置。
Decoder speaker conditioning:WaveNet 解码器基于三个信息源生成样本:先前发出的样本(通过自回归连接)、对说话者或其他时间固定的信息的全局调节以及提取的时变表示 从编码器。 我们发现禁用全局speaker调节会使音素分类准确度降低 3 个百分点。 这进一步证实了我们关于 VQ-VAE 瓶颈引起的解缠结的发现,这使模型偏向于丢弃以更明确形式提供的信息。 在我们的实验中,我们使用了独立于speaker的编码器。 但是,使编码器适应speaker可能会进一步改善结果。 事实上,展示了使用说话人自适应方法对 ZeroSpeech 任务的改进。
编码器超参数:我们尝试调整编码器卷积层的数量、滤波器的数量和滤波器长度。 一般来说,使用更大的编码器会提高性能,但是我们确定必须仔细控制编码器的感受野,性能最好的编码器对于每个生成的令牌可以看到大约 0.3 秒的输入信号。
可以使用两种机制控制有效的感受野:通过仔细调整编码器架构,或通过设计具有宽感受野的编码器,但将训练期间看到的信号段的持续时间限制为所需的感受野。 通过这种方式,模型永远不会学会使用其全部容量。 当模型在 2.5s 长段上训练时,感受野为 0.3s 的编码器的帧音素识别准确率为 56.5%,而感受野为 0.8s 的编码器的得分仅为 54.3%。 当在 0.3 秒的片段上训练时,两个模型的表现相似。
- 瓶颈比特率:语音 VQ-VAE 编码器可以看作是使用非常低的比特率对信号进行编码。 为了达到预定的目标比特率,可以控制令牌率(即通过控制编码器跨步卷积中的下采样程度)和每一步提取的令牌数(或等效的比特数)。 我们发现标记率是一个必须谨慎选择的关键参数,在 50 Hz(56.0% 音素识别准确率)和 25 Hz(56.3%)下获得 200k 训练步骤后获得最佳结果。 准确率在较高的令牌率(100 Hz 时为 49.3%)时突然下降,而较低的令牌率会错过非常短的电话(12.5 Hz 时为 53% 的准确率)。
与令牌的数量相比,VQ-VAE 嵌入的维度对表示质量具有次要影响。 我们发现 64 是一个很好的设置,小得多的维度会降低具有少量标记的模型的性能,而更高的维度会对具有大量标记的模型的性能产生负面影响。
为完整起见,我们观察到即使对于具有最大令牌库存的模型,整体编码器比特率也很低:50 Hz 时为 14 位 = 700 bps,这与经典语音编解码器的最低比特率相当。
- 训练语料库大小:我们在 LibriSpeech 训练集的子集上试验了训练模型,大小从 4.6 小时 (1%) 到 460 小时 (100%) 不等。 对 4.6 小时的数据进行训练,音素识别准确率在 100k 步时达到 50.5% 的峰值,然后下降。 9 小时的训练在 180k 集上达到了 52.5% 的峰值准确率。 当训练集的大小增加超过 23 小时时,音素识别率在大约 90 万步后达到 54%。 通过对完整 460 小时的数据进行训练,没有发现进一步的改进。 我们没有观察到任何过度拟合,并且为了获得最佳结果,训练模型直到达到 900k 步而没有提前停止。未来一个有趣的研究领域将是研究增加模型容量以更好地利用大量未标记数据的方法。
数据集大小的影响在 ZeroSpeech Challenge 结果(表二)中也可见:VQ-VAE 模型在英语(45 小时的训练数据)和法语(24 小时)上表现良好,但在普通话上表现不佳( 2.5 小时)。 此外,在英语和法语上,我们使用在单语数据上训练的模型获得了最好的结果。 使用对所有语言的数据联合训练的模型在普通话上获得了稍好的结果。
Related Work (1页)
序列数据的 VAE 在 [49] 中被引入。 该模型使用 LSTM 编码器和解码器,而潜在表示由编码器的最后一个隐藏状态形成。 该模型被证明对自然语言处理任务很有用。 然而,它也证明了潜在表示崩溃的问题:当一个强大的自回归解码器与潜在编码的惩罚同时使用时,比如 KL 先验,VAE 倾向于忽略先验并表现得好像它是一个 纯自回归序列模型。 这个问题可以通过改变 KL 项的权重来缓解,并通过使用 word dropout 限制自回归路径上的信息量 [49]。 在确定性自动编码器中也可以避免潜在崩溃,例如 [64],它将卷积编码器耦合到强大的自回归 WaveNet 解码器 [18],以学习由来自各种乐器的孤立音符组成的音乐音频的潜在表示。
我们凭经验验证,根据说话人信息调节解码器会导致编码更具有说话人不变性。[54] 给出了一个严格的证明,这种方法产生的表示对于明确提供的信息是不变的,并将其与域对抗训练相关联,这是另一种旨在对已知干扰因素实施不变性的技术 [65]。
当应用于音频时,VQ-VAE 使用 WaveNet 解码器从建模信息中释放潜在表示,这些信息很容易从最近的过去 [19] 中恢复。 它通过使用具有统一先验的离散潜在代码来避免后折叠问题,从而导致恒定的 KL 惩罚。 我们采用相同的策略来设计潜在表示正则化器:我们没有使用可能导致潜在空间崩溃的惩罚项来扩展成本函数,而是依靠潜在变量的随机副本来防止它们的共同适应并促进稳定性 时间。
本文中引入的随机时间抖动正则化受到数据的缓慢表示 [48] 和 dropout 的启发,dropout 在训练神经元期间随机删除以防止它们的协同适应 [50]。 它也与 Zoneout [51] 非常相似,后者依赖于所选神经元的随机时间副本来规范循环神经网络。
几位作者最近提议使用使用变量层次结构的 VAE 对序列进行建模。 [66] 探索了一个分层潜在空间,它将序列相关变量与序列无关变量分开。 他们的模型被证明可以执行说话人转换并在存在域不匹配的情况下提高自动语音识别 (ASR) 性能。 [67] 为序列数据引入了一个随机潜在变量模型,该模型还可以产生解开的表示,并允许在生成的序列之间进行内容交换。 这些其他方法可能会受益于规范潜在表示以实现进一步的信息解开。
声学单位发现系统旨在将声学信号转换成一系列类似于音素的可解释单位。 它们通常涉及声学帧、MFCC 或神经网络瓶颈特征的聚类,使用概率先验进行正则化。 DP-GMM [68] 在高斯混合模型上强加了狄利克雷过程先验。 使用 HMM 时间结构为子语音单元扩展它会导致 DP-HMM 和 HDP-HMM [69]、[70]、[71]。 HMM-VAE 建议使用深度神经网络代替 GMM [72]、[73]。 这些方法通过 HMM 时间平滑和时间建模来强制执行自上而下的约束。 语言单元发现模型在类似单词的级别检测重复出现的语音模式,找到具有约束动态时间扭曲的常见重复段 [74]。
在分段无监督语音识别框架中,神经自动编码器用于将可变长度的语音段嵌入到一个公共向量空间中,在那里它们可以被聚类为单词类型 [75]。 [76] 用一个模型代替分段自动编码器,该模型可以预测附近的语音片段,并证明该表示与词嵌入共享许多属性。 结合无监督的分词算法和在单独的语料库 [77] 上发现的词嵌入的无监督映射,该方法产生了一个在不成对的语音和文本数据上训练的 ASR 系统 [78]。
ZeroSpeech 2017 挑战赛的几个条目依赖于神经网络来发现语音单元。 [61] 在使用无监督术语发现系统 [79] 找到的语音段对上训练自动编码器。 [59]首先对语音帧进行聚类,然后训练神经网络来预测聚类 ID,并将其隐藏表示用作特征。 [60] 使用在 MFCC 上训练的自动编码器发现的特征扩展了该方案。
Conclusion (半页)
我们将序列自动编码器应用于语音建模并比较了不同的信息瓶颈,包括 VAE 和 VQ-VAE。 我们使用可解释性标准以及区分相似语音的能力仔细评估了诱导的潜在表示。 瓶颈的比较表明,使用 VQ-VAE 获得的离散表示保留了最多的语音信息,同时也是最大的说话人不变性。 提取的表示允许将提取的符号准确映射到音素,并在 ZeroSpeech 2017 声学单元发现任务中获得有竞争力的表现。 Cho 等人的 VQ-VAE 编码器和 WaveNet 解码器的类似组合。 在 ZeroSpeech 2019 [80] 中具有最佳的声学单元发现性能。
我们确定模型需要一个信息瓶颈来学习将内容与说话者特征分开的表示。 此外,我们观察到,通过使瓶颈强度成为模型超参数,或者完全去除它(如在 VQ-VAE 中),或者通过使用自由信息 VAE 目标,可以避免由太强的瓶颈引起的潜在崩溃问题 .
为了进一步提高表示质量,我们引入了一种时间抖动正则化方案,该方案限制了潜在代码的容量,但不会导致潜在空间的崩溃。 我们希望这可以类似地提高与其他问题域中的自回归解码器一起使用的潜在变量模型的性能。
VAE 和 VQ-VAE 都限制了潜在表示(latent representation)的信息带宽(information bandwidth)。 然而,VQ-VAE 使用量化机制,它确定性地强制编码等于原型,而 VAE 通过注入噪声来限制信息量。 在我们的研究中,VQ-VAE 比 VAE 产生了更好的信息分离。 然而,需要进一步的实验来充分理解这种影响。 特别是,这是量化的结果还是确定性操作的结果?
我们还观察到,虽然 VQ-VAE 产生离散表示,但为了获得最佳结果,它使用了一个如此大的标记集,以至于为每个标记分配一个单独的含义是不切实际的。 特别是,在我们的 ZeroSpeech 实验中,我们使用了每个令牌的密集嵌入表示,这提供了比简单地使用令牌标识更细微的令牌相似性度量。 也许需要更结构化的潜在表示,其中可以以连续方式调制一小组单元。
广泛的超参数评估表明,优化编码器和解码器网络的感受野大小对于良好的模型性能很重要。 多尺度建模方法可以进一步分离韵律信息。 我们的自动编码方法还可以与更专门用于语音处理的惩罚相结合。 在 [73] 中引入 HMM 先验可以促进潜在表示,从而更好地模仿语音的时间语音结构。