GRAPHSPEECH:用于神经语音合成的语法感知图注意力网络
感想
读下来感觉与ICASSP 2020 发表的GraphTTS的方法差不多少,均是采用GGNN的方法进行TTS的图结构化建模。只不过GraphTTS基于Tacotron2建模,而Graphspeech 基于Transformer 建模,但是Graphspeech的实验部分相对充实简单清晰一些。
Paper | Demo | ICASSP 2021 | Rate: 🌟🌟🌟
摘要
基于注意力的端到端文本到语音合成(TTS)在很多方面都优于传统的统计方法。 基于Transformer的 TTS 是此类成功的实现之一。 虽然 Transformer TTS 使用自注意力机制很好地模拟了语音帧序列,但它没有从句子级别的句法角度将输入文本与输出话语关联起来。 我们提出了一种新的神经 TTS 模型,表示为 GraphSpeech,它是在图神经网络框架下制定的。 GraphSpeech 对句子中输入词法标记的句法关系进行显式编码,并结合这些信息为 TTS 注意力机制推导出句法驱动的字符嵌入。 实验表明,GraphSpeech 在话语的频谱和韵律渲染方面始终优于 Transformer TTS 基线。
关键词:TTS, Graph Neural Network, Syntax
Introduction
文本转语音 (TTS) 旨在为输入文本合成类似人类的自然声音。 最近的进步使许多应用成为可能,例如智能语音助手、电影和游戏的配音、在线教育和智能家居。 最近,拼接和统计参数语音合成系统是主流技术。 我们注意到这两种技术都有复杂的pipelines,包括前端模型、持续时间模型和声学模型。
随着深度学习的出现,端到端TTS生成模型使用单个神经网络简化了合成pipelines。 基于 Tacotron 的神经 TTS 及其变体就是这样的例子。 在这些技术中,关键思想是将传统的 TTS pipelines集成到一个统一的编码器-解码器网络中,并直接从
自注意力网络(SAN)代表了另一种类型的编码器 - 解码器实现,它实现了高效的并行训练,并在机器翻译中具有良好的性能。 在 Transformer TTS 中实现,该模型允许并行计算。 SAN 的另一个好处是与内部注意力一起工作,它具有更短的路径来模拟长距离上下文。 尽管取得了进展,但 Transformer TTS 并没有在句子级别从句法的角度明确将输入文本与输出话语相关联,这在说话风格和韵律建模中被证明是有用的。 结果,特别是对于长句子,话语的呈现受到不利影响。
图神经网络 (GNN) 是连接主义模型,它通过图节点之间的消息传递来捕获图的依赖性。 在图到序列学习中,我们可以在图神经网络的框架中构建自注意力网络,其中将令牌序列视为未标记的全连接图(每个令牌作为一个节点 ),而self-attention机制被认为是一种特定的消息传递方案。 受此启发,我们提出了一种新颖的神经 TTS 模型,表示为 GraphSpeech,它采用两个新颖的编码模块:关系编码器(relation encoder)和图编码器(graph encoder)。 关系编码器从输入文本中提取语法树; 然后将语法树转化为图结构; 并对图中任意两个标记之间的关系进行编码。 图编码器提出了句法感知图注意机制,它不仅关注标记而且关注它们的关系,从而受益于有关句子结构的知识。
本文的主要贡献如下: 1)我们提出了一种新颖的神经 TTS 架构,表示为 GraphSpeech; 2)我们制定了从句法树到句法图的扩展,以及字符级的关系编码; 3)我们提出了一种语法感知图注意力机制,将语言知识纳入注意力计算; 4) GraphSpeech 在频谱和韵律建模方面都优于最先进的 Transformer TTS。 据我们所知,这是第一个在 Transformer TTS 中使用图神经网络视角的句法-感知的注意机制的实现。
本文的组织如下:在第 2 节中,我们重新审视了作为基准参考的 Transformer TTS 框架。 在第 3 节中,我们研究了提议的 GraphSpeech。 在第 4 节中,我们报告了评估结果。 我们在第 5 节总结了这篇论文。
Transformer TTS
Transformer TTS 是一种基于自注意力网络 (SAN) 的神经 TTS 模型,具有编码器-解码器架构,可以并行训练和学习长距离依赖。 基于 SAN 的编码器具有多头自注意力机制,可以直接在任意两个令牌之间建立长时间的依赖关系。 给定输入文本的标记序列 \(x_{1:n}\),对于每个注意力头,标记 \(x_i\) 和标记 \(x_j\) 之间的注意力分数只是它们的查询向量和关键向量的点积,如下所示: \[ \begin{equation}\label{eq1} s_{ij} =f(x_i,x_j)=x_iW_q^TW_kx_j \end{equation} \] 最终的注意力输出 attn 通过 softmax 函数进行缩放和归一化,如下所示: \[ \begin{equation}\label{eq2} attn = \sum^n_{i=1} a_iW_vx_i \end{equation} \]
\[ \begin{equation}\label{eq3} a_i = \frac{\text{exp}(s_{ij}/{\sqrt d}) } { \sum^n_{j=1} \text{exp}(s_{ij}/ \sqrt d)} \end{equation} \]
其中\(\sqrt d\)是缩放因子,\(d\) 是层状态的维度,\(W_q\)、\(W_k\) 和 \(W_v\) 是可训练的矩阵。 最后,将所有注意力头的输出拼接并投影以获得最终的注意力值。
虽然 SAN-encoder 在任何两个标记之间建立远程依赖来建模全局上下文,但它没有对句子中单词的复杂句法依赖进行建模,这通常由树结构或 图形。 我们认为需要一种表示深层句法关系的机制来对输入文本和输出话语之间的关联进行建模。 接下来,我们在第 3 节中研究了一种新颖的 GraphSpeech 模型。
Graphspeech
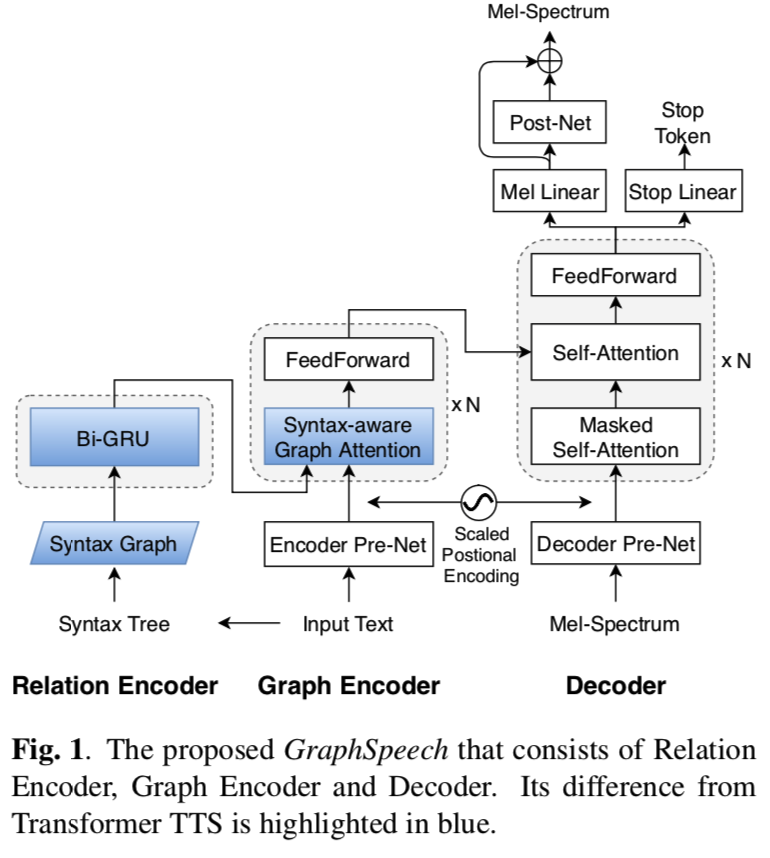
graphspeech-fig1
图结构在自然语言处理 (NLP) 中扮演着重要角色,它经常作为表示句法、语义和知识的中心形式。 我们建议将图形建模合并到神经 TTS 架构中,称为 GraphSpeech,如图 1 所示,以对输入文本、其句法结构和输出语音之间的关联进行建模。
在 GraphSpeech 中,编码器的输入包括文本和句法知识。 众所周知,话语的语言韵律与句子的句法结构密切相关。 GraphSpeech 以语法树的形式使用此类语法信息来增强语音合成输入,这有望改善输入文本的语言表示。 在实践中,语法树用作更准确的自注意力的辅助信号。 GraphSpeech 有 3 步工作流程:1)关系编码器,2)图编码器和 3)解码器,这将在接下来讨论。
3.1 Relation Encoder
Relation Encoder 将输入文本的语法树转换为语法图,描述所涉及的输入标记之间的全局关系。 句法依存分析树是描述词之间语言依存关系的传统方法之一。 在树状结构中,只有在句子中直接相关的词才会被连接起来。 其他人没有直接联系。 为了挖掘句子中两个词之间的句法关系,我们希望扩展句法树的拓扑结构以建立全连接通信。
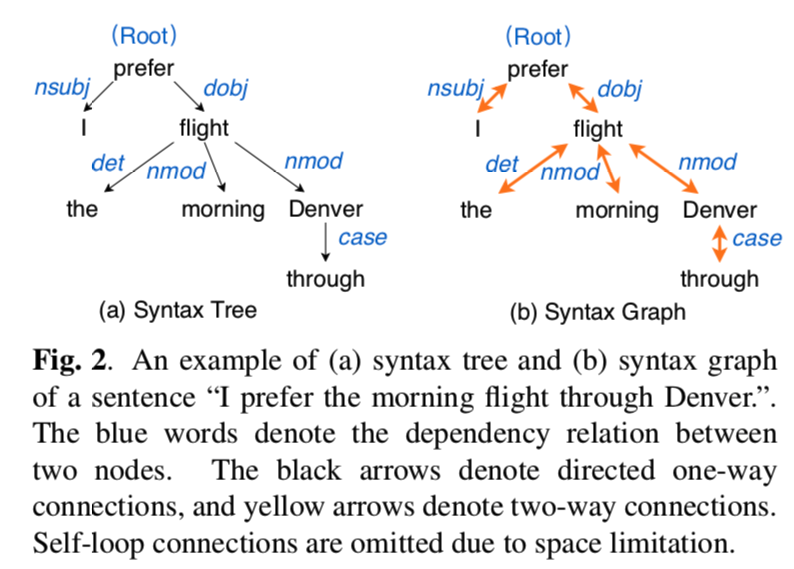
graphspeech-fig2
为此,我们提出了语法图 syntax graph,它是图 2 所示的语法树的扩展。我们的想法是通过添加反向连接将单向连接变成双向连接。 此外,我们为每个单词引入了带有特定标签的自循环边。 这样,句子中的单词用节点表示,它们的连接用边表示。 通过图2(b)中的双向连接,一个词能够直接接收和发送信息给任何其他词,无论它们是否直接连接。
为了对两个节点之间的关系建模,将节点对之间的关系描述为它们之间的最短关系路径。 我们使用带有门控循环单元 (GRU) 的循环神经网络将关系序列转换为分布式表示。 节点 \(i\) 和节点\(j\) 之间的最短关系路径 \(sp_{i→j}\) 表示为 \([sp_1, ..., sp_t, ..., sp_{n+1}] = [e(i, k_1), e(k_1, k_2), ..., e(k_n, j)]\),其中 \(e(·, ·)\) 表示边标签,\(k_{1:n}\) 是中继节点。 我们使用双向 GRU 进行路径序列编码: \[ \begin{equation}\label{eq4} \vec s_t =GRU_f(\vec s_{t−1},sp_t) \end{equation} \]
\[ \begin{equation}\label{eq5} \stackrel{\leftarrow}s_t =GRU_b(\stackrel{\leftarrow} s_{t+1},sp_t) \end{equation} \]
前向 GRU 网络和后向 GRU 网络的最后隐藏状态连接起来形成最终的关系编码 \(r_{ij} = [\vec s_{n+1} ; \stackrel{\leftarrow}s_0 ].\) 最终的关系编码表示两个词之间的语言关系。 在神经 TTS 中,句子的基本单位是字符标记。 我们在这里将 NLP 中的词级关系编码扩展到字符级编码。 如果两个字符属于同一个词,我们使用自循环边编码\(r_{ii}\)来定义它们的关系编码; 如果两个字符属于不同的词,我们直接使用\(r_{ij}\),即它们所属词的关系编码来分配它们的关系编码。
关系编码为模型提供了一个关于如何收集和分发信息的全局视图,即在哪里参加。 接下来我们将讨论所提出的图编码器,该编码器旨在将句法关系编码合并到自注意力机制中以指示字符关系。
3.2 Graph Encoder
图编码器旨在将输入字符嵌入序列和关系编码转换为相应的由句法驱动的字符嵌入序列。 我们将两个节点之间的显式关系表示合并到注意力计算中,表示为语法感知图注意力。
然后堆叠多个语法感知图注意和前馈层块以计算最终的字符表示。 在每个块中,基于所有其他字符嵌入和相应的关系编码更新字符嵌入。 最后一个块的结果字符嵌入被馈送到解码器以生成声学特征。
关系编码只对两个字符之间的最短路径进行编码。 为了在计算注意力时对连接的方向进行编码,我们首先将关系编码 \(r_{ij}\) 分为前向关系编码 \(r_{i→j}\) 和后向关系编码 \(r_{j →i} : [r_{i→j} ; r_{j →i} ] = W_r r_{ij}\) 。 然后,使用语法感知图注意力来计算注意力分数,该分数基于字符表示及其双向关系表示: \[ \begin{equation}\label{eq6} \begin{aligned} s_{ij} &=g(x_i,x_j,r_{ij}) \\ &= ( x_i + r_{i → j} ) W_q^T W_k ( x_j + r_{j → i} ) \\ &= \underbrace{x_i W_q^T W_k x_j}_{(a)} + \underbrace{x_i W_q^T W_k r_{j → i}}_{(b)} \\ &+ \underbrace{r_{i→j}W_q^TW_kx_j}_{(c)} + \underbrace{r_{i→j}W_q^TW_kr_{j→i}}_{(d)} \end{aligned} \end{equation} \] 我们注意到以上方程中的项与公式的直观解释有关,如下所示:1) (a) 捕获纯粹基于内容的寻址,这与等式 (1) 一致; 2) (b) 项表示正向关系偏差; 3) (c) 项控制后向关系偏差; 和 4) (d) 项编码通用关系偏差。
通过语法感知图注意力,通过将显式句法关系约束纳入注意力机制,语法知识用于指导字符编码。 最后,解码器采用句法驱动的字符嵌入进行声学特征预测。
3.3 解码器
解码器遵循 Transformer TTS 中报告的相同结构。 我们使用 Mel Linear、Post-Net 和 Stop Linear 分别预测 mel 谱和停止标记。 如上所述,关系编码器对两个远距离字符之间的显式句法关系进行编码。 图编码器采用句法感知图注意力来导出句法驱动的字符表示。 解码器将字符表示作为输入并产生自然的声学特征。 通过这种方式,解码器学习将输入文本及其语法与输出话语相关联。
实验
我们进行客观和主观评估来评估我们提出的 GraphSpeech 框架的性能。 我们使用 LJSpeech 数据库,该数据库由 13,100 个短片组成,其中一位演讲者阅读了大约 7 本书,总共将近 24 小时的演讲。 我们使用最先进的 Transformer TTS 作为基线。
4.1 实验配置
在这项研究中,我们使用 Stanza 来提取句法依赖解析器树。 对于关系编码器,边缘嵌入的大小设置为 200 维随机初始化。 我们在两个方向上将 GRU 层的大小设置为 200,并生成 200 维的关系编码。 图编码器将 256 维字符嵌入或节点嵌入作为输入。 我们在图编码器中使用 N = 6 个块,在 GraphSpeech 的解码器中使用 N = 6 个块。 我们在图编码器和解码器中设计了 4 个用于多头注意力的头。 解码器生成一系列 80 通道梅尔谱声学特征作为输出。
在训练期间,我们提取帧大小为 50 毫秒和帧偏移为 12.5 毫秒的梅尔谱声学特征,进一步归一化为零均值和单位方差,作为参考目标。 我们使用 Adam 优化器训练模型,\(β_1 = 0.9,β_2 = 0.98\)。 在我们的实验中采用了与Transformer中相同的学习率计划。
为了计算效率,我们在训练和测试批次中组合了所有不同的最短路径。 然后我们通过关系编码器将它们编码为向量表示,如第 3.1 节所述。 为了快速周转,我们使用 Griffin-Lim 算法来生成波形。
4.2 客观评估
我们采用梅尔谱失真 (MCD) 来测量合成和参考梅尔谱特征之间的光谱距离。 我们使用均方根误差 (RMSE) 作为韵律评估指标。
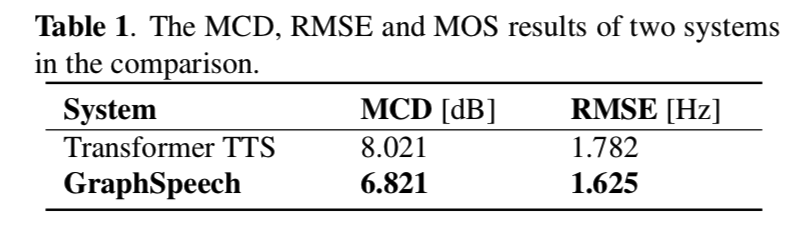
graphspeech-tab1
在表 1 中,我们报告了比较研究中的 MCD 和 RMSE 结果。 我们观察到 GraphSpeech 提供了验证其有效性的较低 MCD 和 RMSE 值。 通过语法感知图注意力机制,GraphSpeech 不仅学习将输入文本关联起来,还学习将其语法结构与目标话语关联,从而改进 TTS 语音渲染。
4.3 主观评估
我们进行主观评价的听力实验。 我们首先根据平均意见得分 (MOS) 评估 Transformer TTS、GraphSpeech 和 ground truth。 听者以5分制对话语进行评分:“5”为优秀,“4”为好,“3”为一般,“2”为差,“1”为差。 15 名受试者参与了这些实验,每人听了 100 个合成语音样本。
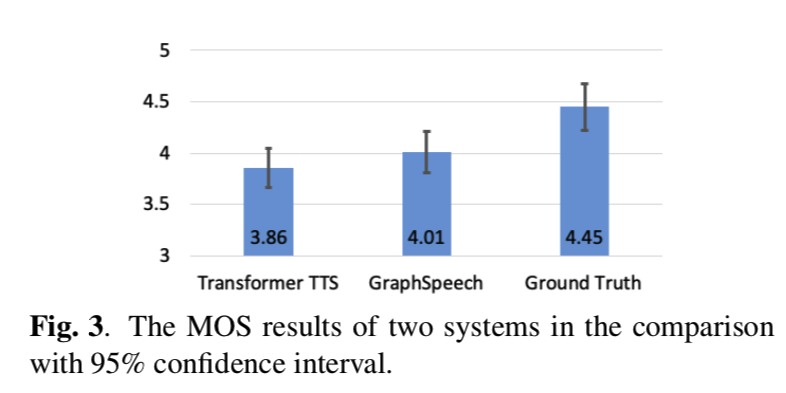
graphspeech-fig3
如图 3 所示,GraphSpeech 大大优于 Transformer TTS,并且取得了与Ground-truth自然语音相当的结果,我们认为这是非常了不起的。 这些结果清楚地表明,在 GraphSpeech 中提出和实施的语法感知图注意力策略有效地对语言知识建模并实现了高质量的合成语音。
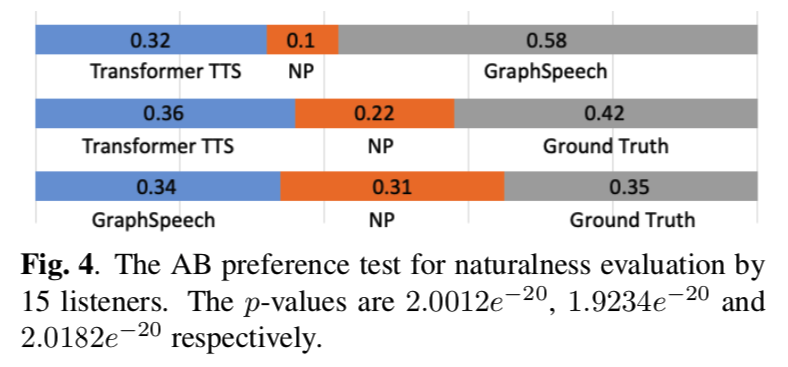
graphspeech-fig4
我们进一步进行 AB 偏好测试,其中要求听众比较一对系统之间合成语音样本的质量和自然度,并选择更好的一个。 从图 4 中可以看出,听众始终喜欢所提出的 GraphSpeech 模型,这进一步验证了所提出的图注意力机制。 据悉,GraphSpeech合成的样本接近自然语音,令人鼓舞。
结论
在这项工作中,我们提出了一种新颖的神经 TTS 架构,表示为 GraphSpeech。 所提出的语法感知图注意机制有效地对输入文本的任意两个字符之间的语言关系进行建模。 实验结果表明,GraphSpeech 在客观和主观评价中均优于原有的 self-attention 系统,并且在语音质量和韵律自然度方面取得了显着的表现。