Wave-tacotron: 无需频谱图的端到端文本转语音合成
摘要
我们描述了一个序列到序列的神经网络,它直接从文本输入生成语音波形。该架构通过将归一化流 (normalizing flow) 合并到自回归解码器循环中来扩展 Tacotron 模型。输出波形被建模为一系列不重叠的固定长度块,每个块包含数百个采样点。每个模块内波形采样点的相互依赖性使用归一化流 (normalizing flow) 建模,从而实现并行训练和合成。通过在前面的块上条件依赖于每个流,自回归处理长期依赖关系。该模型可以直接以最大似然进行优化,无需使用中间的、手工设计的特征或额外的损失项。当代最先进的文本到语音 (TTS) 系统使用一系列单独学习的模型:一个(例如 Tacotron)从文本生成中间特征(例如频谱图),然后是声码器(例如WaveRNN)从中间特征生成波形样本。相比之下,所提出的系统不使用固定的中间表示,而是端到端地学习所有参数。实验表明,所提出的模型生成的语音质量接近最先进的神经 TTS 系统,生成速度显着提高。
Introduction
现代文本到语音 (TTS) 合成系统使用在大量数据上训练的深度神经网络,能够生成自然语音。 TTS 是一个多模态生成问题,因为文本输入可以通过多种方式实现,就总体结构而言,例如,具有不同的韵律或发音,以及低级信号细节,例如,具有不同的,可能在感知上相似的相位。最近的系统将任务分为两个步骤,每个步骤都针对一个粒度。首先,合成模型从文本中预测中间音频特征,通常是频谱图、声码器特征或语言特征,控制生成语音的长期结构。接着是神经声码器,它将特征转换为时域波形样本,填充低级信号细节。这些模型最常单独训练,但可以联合微调。神经声码器示例包括自回归模型,例如 WaveNet 和 WaveRNN 、使用归一化流normalizing flow的完全并行模型 、支持高效训练和采样的基于耦合的流或并行建模长期结构但自回归建模精细细节的混合流。其他方法避开了概率模型,使用 GAN 或精心构建的频谱损失。
这种两步走的方法使端到端 TTS 变得易于处理; 然而,它会使训练和部署复杂化,因为获得最高质量通常需要微调或由于后者的弱点而在合成模型的输出上训练声码器。
由于难以有效地对波形中的强时间依赖性(例如,相位必须随时间保持一致)进行有效建模,因此难以从文本中端到端生成波形样本。 sample-level的自回归声码器通过条件于所有先前生成的样本来生成每个波形样本,来处理这种依赖性。 由于它们的高度顺序性,它们在现代并行硬件上的采样效率很低。
在本文中,我们将基于流的声码器集成到类似于 Tacotron 的语音波形块级block-level自回归模型中,以字符或音素序列为输入条件。 序列到序列解码器处理输入文本,并为生成波形块的归一化流生成条件特征。
输出波形被建模为一系列固定长度的块,每个块包含数百个样本。 每个模块内样本之间的依赖关系使用normalizing flow建模,从而实现并行训练和合成。 通过条件于先前块,对长期依赖性进行自回归建模。 由此产生的模型解决了比文本到频谱图生成更困难的任务,因为它必须综合波形中的精细时间结构(确保连续输出块的边缘正确排列)以及产生连贯的长 术语结构(例如,韵律和语义)。 尽管如此,我们发现该模型能够对齐文本并生成高保真语音,而不会产生framing artifacts。
最近的工作将归一化流与序列到序列的 TTS 模型相结合,以启用非自回归解码器,或改进中间梅尔谱图 的建模。Fastspeech2 和 EATs 还提出了直接生成波形的端到端 TTS 模型,但依靠频谱损失和梅尔频谱图进行对齐。 相比之下,我们完全避免了频谱图的生成,而是使用normalizing flow直接对时域波形建模,采用完全端到端的方法,简单地maximizing likelihood。
Wave-Tacotron Model
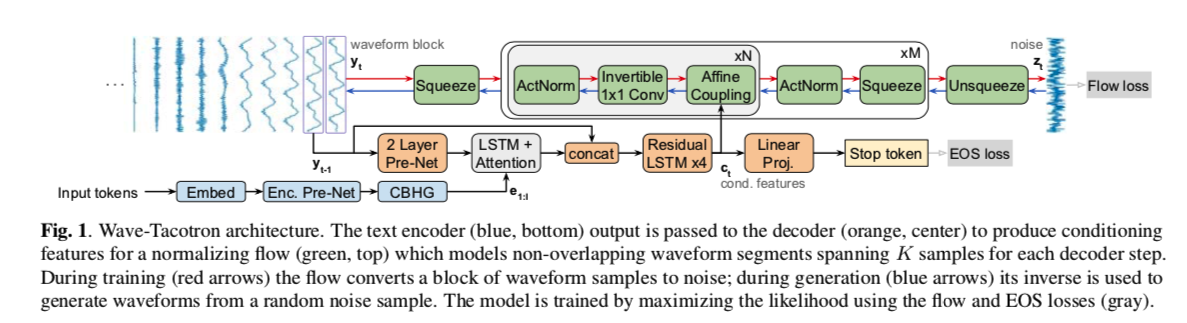
Wave-Tacotron 扩展了 Tacotron 基于注意力的序列到序列模型,生成非重叠波形样本块而不是频谱图帧。 有关概览,请参见图 1。 编码器是一个 CBHG,它对一系列 I 标记(字符或音素)嵌入 $x_{1:I}$ 进行编码。 使用注意力将文本编码传递给块自回归解码器,为每个输出步骤 $t$ 生成条件特征 $c_t$。 normalizing flow 使用这些特征来采样该步的输出波形, $y_t$ :
流 $g$ 将从高斯采样的随机向量 $z_t$ 转换为波形块。 $c_t$ 上的线性分类器计算 $t$ 是最终输出步骤(在之后称为停止标记)的概率 $\hat s_t$:
其中 $σ$ 是 sigmoid 非线性。 默认情况下,每个输出 $y_t ∈ R^K$ 包含 40 ms 的语音:$K = 960$,采样率为 $24 kHz$。 $K$ 的设置通过normalizing flow控制可并行性与通过自回归的样本质量之间的权衡。
网络结构遵循Tacotron,对解码器稍作修改。 我们使用位置敏感注意力,它比非基于内容的 GMM 注意力更稳定。 我们在 pre-net 中用 tanh 替换 ReLU 激活。 由于我们从解码器循环中的normalizing flow中采样,因此我们不需要在采样时应用 pre-net dropout。 我们也不使用 post-net。 在每个解码器步骤生成的波形块被简单地连接起来形成最终信号。 最后,我们在解码器 pre-net 和注意力层上添加了一个跳过连接skip connection,让flow直接访问当前块之前的样本。 这对于避免块边界处的不连续性至关重要。
与 Tacotron 类似,$y_t$ 的大小 $K$ 由缩减因子超参数 $R$ 控制,其中 $K = 320 · R$,默认情况下 $R = 3$。 与Tacotron 一样,解码器的自回归输入仅包含来自上一步 $y_{t-1}$ 的输出的最终 $K/R$ 个采样点。
2.1 flow
归一化流 $g(z_t ; c_t )$ 是可逆变换的组合,它将从球面高斯抽取的噪声样本映射到波形段。 它的表现力来自于组合许多简单的函数。 在训练过程中,逆函数 $g^{−1}$ 将目标波形映射到球面高斯下,一个密度易于计算的点。
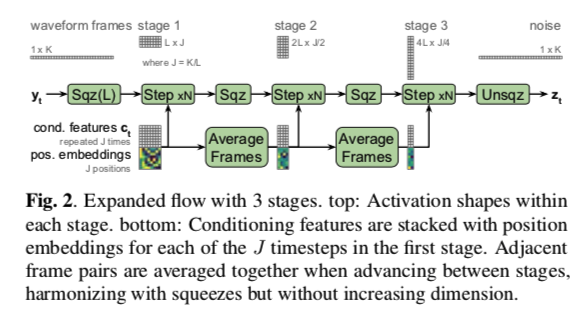
由于训练和生成分别需要有效的密度计算和采样,$g$ 是使用仿射耦合层构建的。 我们的标准化流是 Glow 的一维变体,类似于FloWaveNet。 在训练期间,$g^{−1}$ 的输入,$y_t ∈ R^K$,首先被压缩到 $J$ 帧的序列中,每个帧的维度 $L = 10$。流被分为 $M$ 个阶段,每个阶段在不同的时间分辨率下运行,遵循多尺度中描述的配置。 这是通过交错挤压interleaving squeeze 操作来实现的,该操作重塑每个阶段之间的序列,将时间步数减半并将维度加倍,如图 2 所示。在最后阶段之后,解压unsqueeze操作将输出 $z_t$ 展平为 $R^K$ 中的向量 . 在生成过程中,为了通过 $g$ 将 $z_t$ 转换为 $y_t$,每个操作都被颠倒并且它们的顺序颠倒。
每个阶段进一步由 $N$ 个flow steps组成,如图 1 顶部所示。我们不像Glow那样对我们的 ActNorm 层使用数据相关的初始化。 仿射耦合层使用内核大小为 3、1、3 和 256 个通道的 3 层 1D convnet 输出变换参数。 通过使用挤压层squeeze layers,不同阶段的耦合层使用相同的内核宽度,但相对于 $y_t$ 具有不同的有效感受野。 默认配置使用 $M = 5$ 和 $N = 12$,总共 60 步。
条件信号 $c_t$ 由每个解码器步骤的单个向量组成,它必须跨数百个样本对 $y_t$ 的结构进行编码。 由于flow内部将 $z_t$ 和 $y_t$ 视为 $J$ 帧的序列,我们发现对 $c_t$ 进行上采样以匹配此帧很有帮助。 具体来说,我们复制 $c_t$$L$ 次并将正弦位置嵌入(sinusoidal position embeddings)连接到每个时间步,类似于Transformer,尽管频率之间具有线性间距。 上采样的条件特征附加到每个耦合层的输入。
为了避免与将实值分布拟合到离散波形样本相关的问题,我们通过将样本量化为 $[0, 2^{16} − 1]$ 级别来调整 RNADE 中的方法,并通过在 $[0, 1]$ 中添加均匀噪声进行 去量化 ,并重新缩放回 $[−1, 1]$。 我们还发现预加重波形很有帮助,使用 FIR 高通滤波器将信号频谱白化with a zero at 0.9。 生成的信号在模型的输出端被 去加重。 这种预加重可以被认为是一个没有任何可学习参数的流程,作为一种归纳偏置inductive bias,将更高的权重放在高频上。 虽然不是关键,但我们发现这改善了主观听力测试结果。
作为generative flows的常见做法,我们发现在采样时降低先验分布的temperature是有帮助的。 这相当于简单地缩放方程 3 中 $z_t$ 的先验协方差,通过一个因子 $T^2 <1$。我们发现$T =0.7$是一个好的设置条件。
在训练期间,flow的逆,$g^{−1}$,将目标波形 $y_t$ 映射到相应的 $z_t$。 条件特征 $c_t$ 是使用序列到序列网络的教师强制计算的。 步骤 $t$ 中流flow的负对数似然目标是 NICE:
其中$z_t = g^{−1} (y_t ; c_t)$. 停止标记分类器使用二元交叉熵损失:
其中$s_t$是ground truth stop token标签,表示$t$是否是话语的最后一步。 在实践中,我们用几个标记为 $s_t = 1$ 的块对信号进行零填充,以便为分类器提供更好的平衡训练信号。 我们使用公式5和6在所有解码器步骤 $t$ 的的平均值作为整体损失。
2.2 Flow vocoder
作为基线,我们在完全前馈声码器上下文中使用类似的流网络进行实验,该网络从 mel 谱图生成波形。 我们遵循图 2 中的架构,流帧长度 L = 15,M = 6 个阶段,N = 每阶段 10 个步骤。 输入 mel 频谱图特征使用 5 层扩张卷积网络调节堆栈进行编码,每层使用 512 个通道。 特征被上采样以匹配 1600 Hz 的流帧速率,并与正弦嵌入连接以指示每个特征帧内的位置,如上。 这个模型是高度并行化的,因为它不使用自回归。
实验
模型训练时间:500k steps on 32 Google TPUv3 cores, batch size: 128 for LJSpeech
结论
我们提出了一种端到端(标准化)文本到语音波形合成模型,将normalizing flow合并到自回归 Tacotron 解码器循环中。 Wave-Tacotron 使用单一模型直接生成高质量的语音波形,以文本为条件,无需单独的声码器。 训练不需要手工设计的频谱图或其他中级特征的复杂损失,而只是最大化训练数据的可能性。 混合模型结构将基于注意力的 TTS 模型的简单性与归一化流的并行生成能力相结合,直接生成波形样本。
尽管网络结构将输出块大小 K 作为超参数,但解码器基本上仍然是自回归的,需要顺序生成输出块。与并行 TTS的最新进展相比,这使该方法处于劣势,除非输出步长可以变得非常大。探索使所提出的模型适应完全并行 TTS 生成的可行性仍然是未来工作的一个有趣方向。 TTS 任务的两步分解中固有的关注点分离,即将高保真波形生成与文本对齐和长期韵律建模的任务分离,可能导致实践中更有效的模型。两个模型的单独训练还允许在不同的数据上训练它们的可能性,例如,在更大的未转录语音语料库上训练声码器。最后,在类似的文本到波形设置中探索更有效的流替代方案会很有趣,例如,扩散概率模型或 GAN,它们可以更容易地在一个寻求模式的方式可能比对完整数据分布建模更有效。