Reinforce-aligner: 增强对齐搜索以实现稳健的端到端文本到语音
摘要
文本到语音 (TTS) 合成是从文本或音素输入生成合成语音的过程。传统的 TTS 模型包含多个处理步骤,需要外部对齐器,提供音素到帧序列的注意力对齐。随着每增加一个步骤的复杂性增加和效率降低,对具有高效内部对准器的端到端 TTS 的现代合成管道的需求不断扩大。在这项工作中,我们提出了一种端到端的文本到波形网络,该网络具有一种新颖的基于强化学习的持续时间搜索方法。我们提出的生成器是前馈的,对齐器通过从为最大化累积奖励而采取的行动中接收主动反馈来训练代理做出最佳持续时间预测。我们展示了由受过训练的代理生成的音素到帧序列的准确对齐增强了合成音频的保真度和自然度。实验结果还表明,与具有内部和外部对准器的其他最先进的 TTS 模型相比,我们提出的模型具有优越性。
Introduction
自回归模型启动了文本转语音 (TTS) 的快速进展。这些模型取代了传统方法,并且通常在具有注意力机制的编码器-解码器框架中进行序列到序列。编码器的目的是从音素序列中提取隐藏的表征特征向量,解码器从产生的向量中生成梅尔谱图。尽管有这些优点,但自回归模型中的端到端注意力也有局限性,例如推理速度慢、跳词和阅读。作为解决这个问题的一种方法,非自回归模型被提议用于从文本或音素并行生成梅尔谱图。尽管新架构减轻了自回归模型的一些缺点,但非自回归模型的持续时间对齐器仍然需要外部对齐器的指导。使用外部矫正器的最关键问题是增加了训练过程的复杂性。在训练之前,自回归模型需要正确对齐的文本和语音注意力图。这会延迟训练过程,并且非自回归模型变得依赖于外部对齐器生成的对齐质量。因此,最近的合成管道的设计目标是强大的端到端内部对准器。
最近与我们的工作相关的 TTS 工作是 EATS 和 HiFi-GAN 。 EATS 是一种端到端的文本到波形网络,具有内部对齐器,该对齐器将音素与高斯核的梅尔谱序列对齐近似。尽管该模型提出了强大的文本到波形合成,但没有额外训练对齐以确保改进的持续时间对齐。 Hifi-GAN 通过多尺度和多周期鉴别器生成高质量的音频波形,但该模型仅限于仅考虑梅尔谱图作为输入。我们提出的文本到波形网络代表了两全其美的优点和对缺点的改进。
在本文中,我们提出了一种具有强化对齐器的端到端文本到波形网络,这是一种基于强化学习的对齐搜索方法,用于鲁棒语音合成。我们的代理通过一系列步骤与环境交互,以选择给定当前状态的最佳动作。然后,环境对动作应用更新并返回动作的奖励,以便代理在下一步考虑。重复这个训练过程直到收敛,并使网络能够在内部学习自己的对齐方式。我们的实验结果显示了强化对齐器对生成的音频波形的持续时间对齐和质量的积极影响。我们的在线演示网页上提供了合成音频样本。
Model Architecture
我们提出的全卷积生成器利用文本或音素作为输入并生成原始音频波形作为输出。编码器包含一个改进的多感受野融合模块(MRF)。 MRF 的原始实现使用梅尔频谱图作为输入,并通过转置卷积将梅尔频谱图上采样为原始波形。我们的实现利用音素嵌入作为输入和输出隐藏表示,而无需上采样。基于 MRF 的音素编码器包含多个具有多个内核大小和扩张率的残差块,这是我们网络的重要组成部分,因为各种感受野能够从音素嵌入中提取不同的上下文特征。然后,编码器输出通过强化对齐器进行输出以产生输出帧。输出帧由 $γ$ 随机分割。最后,解码器将 $γ$ 上采样 256 以产生原始音频波形。
我们的模型在训练期间包含针对不同目标的两个判别器。第一个鉴别器是中提出的多尺度鉴别器。该鉴别器通过音阶的变化有效地学习音频的不同频率分量。三个子鉴别器中的每一个都包含不同尺度的卷积:原始音频,按因子 2 下采样,按因子 4 下采样。第二个鉴别器是 Multi-Period Discriminator,它通过卷积捕获音频的不同特征在周期性变化中。每个不同的周期值考虑输入音频的不同周期段。
Reinforce-Aligner
3.1 Reinforcement learning setup
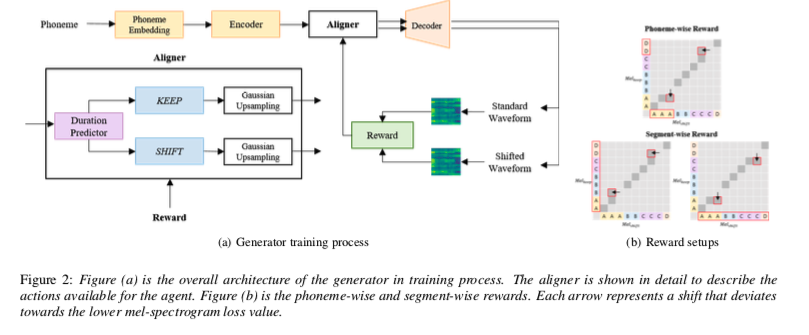
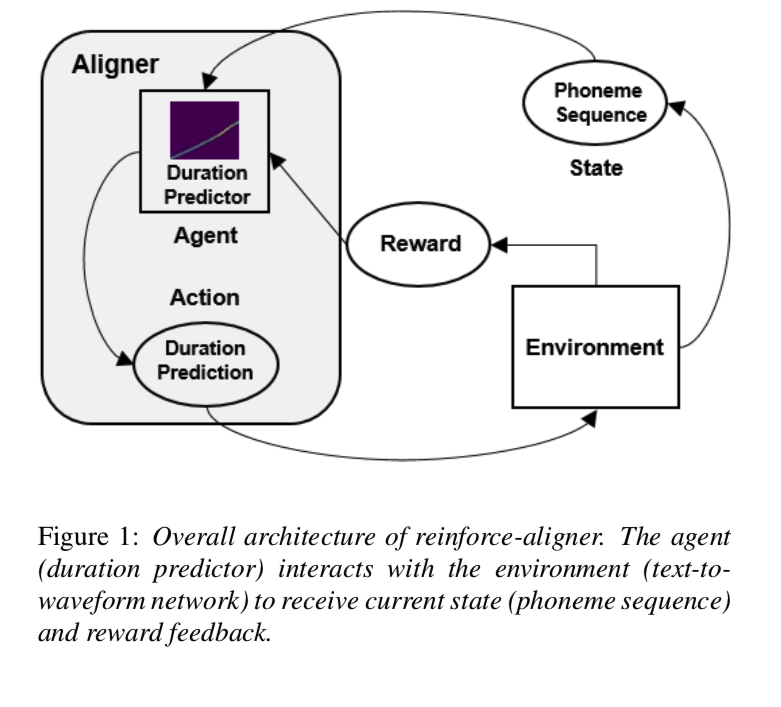
强化对齐器的一般架构如图 1 所示。持续时间预测器是在训练过程的每个步骤中与环境交互的代理。 环境是整个文本到波形网络。 如图 2(a) 的生成器训练过程所示,每个持续时间预测都被上采样为波形,并通过各个 melspectrogram 的 mel-spectrogram 损失计算奖励。 奖励反馈返回给代理以进行最终动作选择。
3.2 Agent
持续时间预测器为每个音素持续时间预测返回一个标量值。 Predictor 由两个 1D 卷积层组成,每个层都有层归一化、ReLU 激活和跟随的 dropout。最后一个线性层将卷积输出重塑为单个标量值。代理有两种可用的操作:
- 保持:保持音素持续时间预测而不对预测输出进行任何更改。
- 移位:移位音素持续时间预测,移位值应用于交替符号。
应用于每个音素持续时间的移位由交替符号组成,这对于保持持续时间预测输出的总和很重要。此外,我们设计了两种类型的转换:分段转换和音素转换。分段移位对应于应用于整个音素序列段的移位。音素移位是应用于音素序列的每个音素持续时间的移位。我们在消融研究中检查了班次类型和值对对齐结果和语音质量的影响。
3.3 Environment
在这个基于强化学习的设置中,环境是经过训练的文本到波形网络,它从音素输入输出音频波。 强化对齐器中的环境有两个主要目标:
- 在代理采取行动之前向代理提供输入音素序列信息,
- 在考虑两种可能的行动中的每一个之后向代理提供反馈。
3.3.1 State
环境在每个训练步骤中为代理生成音素嵌入输出。 从音素序列输入,基于多感受野融合的音素编码器通过多个残差块生成音素嵌入输出。 这些编码器输出是代理决定动作的当前状态输入。
3.3.2 Rewards
根据shift的类型,我们有两种不同的奖励。 两种奖励都考虑了梅尔谱图损失,即真实数据和生成波形的梅尔谱图之间的 L1 损失。 如图 2(a) 所示,每个质谱图都是由预测 (KEEP) 和移位 (SHIFT) 持续时间合成的波形产生的。 分段奖励比较用于训练的整个波段的损失值。 较低的损失值意味着生成的波形与真实情况的相似度较高。 音素方面的奖励考虑了音素方面的梅尔谱损失值。 具体来说,梅尔谱图损失值通过下采样插入到音素持续时间序列的形状中。 将预测时长的音素时长序列表示为 $D_k = [d_1,d_2,d_3,…,d_j]$ 并将移位shifted时长表示为 $D_s =[d_1 +α,d_2 −α,d_3 +α…,d_j ±α]$,其中$α$ 表示移位shift值。 然后,我们的奖励被公式化为:
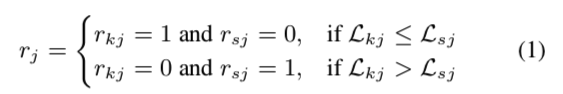
这里,$L_k$ 表示预测和真实梅尔谱图之间的 L1 损失,$L_s$ 是移位shifted和真实梅尔谱图之间的 L1 损失。 $r_k$ 和 $r_s$ 分别是保持奖励和转移奖励值。 每个$j$是音素时长序列中总共$N$个索引的音素时长索引值。 对于分段奖励,保持奖励值和转移奖励值均具有相等的值 $∀j$。 对于音素方面的奖励,每个 $j$ 都有唯一的保持和转移奖励值。
3.4 Gaussian upsampling
预测的持续时间被缩放到帧序列输出的长度。 如 [21] 中所介绍的,每个缩放预测用于查找缩放令牌长度及其中心位置的累积总和。 我们首先计算权重:
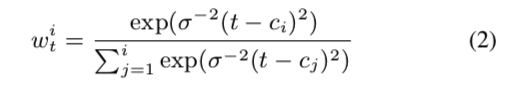
给定固定温度参数 $σ^2$、缩放标记中心位置 $c$ 和时间步长 $t$。 我们通过在编码器输出和权重之间产生加权和来完成上采样。 输出特征用作解码器输入,转置卷积将特征上采样为原始波形。
3.5 Reinforced Duration Loss
我们通过包含奖励和持续时间预测动作的损失为代理提供适当的反馈。 对于每个音素序列索引 $j$,在原始持续时间预测和所选动作的持续时间之间比较持续时间值。 损失定义为:
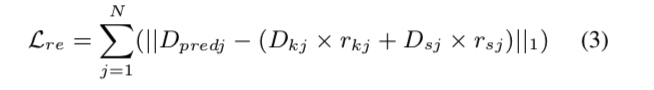
给定 $N$ 个total tokens,每个 $D_k$、$r_k$ 对和 $D_s$、$r_s$ 对分别代表保持、转移动作的持续时间和奖励值。 $D_{pred}$ 等于 $D_k$,因为保持动作不会改变预测的持续时间值。 因此,该损失为 shift 动作返回正损失,而为 keep 动作返回零损失。
Auxiliary loss
我们利用 GAN 损失 和reinforcement 持续时间损失。 此外,辅助损失用于支持我们的文本到波形网络的训练。
4.1 Total duration loss
对齐器的主要目的是产生音素到帧序列的准确对齐。 但是,对齐器在训练期间没有“正确”的持续时间对齐可供参考,因此不确定持续时间输出是否准确。 因此,总持续时间损失被用作模型的指导。 我们参考了中的对准器长度损失。 令 $m_{length}$ 是真实谱图的长度,$l_j$ 是第 $j$ 个标记的预测长度。 总持续时间损失为:
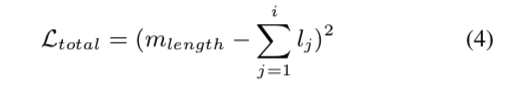
4.2 Mel-spectrogram loss
之前的研究提到梅尔谱损失能够优化发生器并提高生成波形的质量。 此外,强化对齐器的奖励设计取决于梅尔谱图损失值,以在我们的模型中为代理产生质量反馈。 损失公式为:
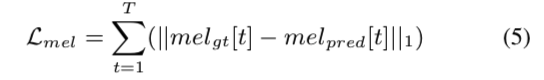
其中 $mel_{gt}、mel_{pred}$ 是 $T$ 时间步长的真值和合成波形的梅尔谱图。
4.3 Soft DTW
我们通过在Ground-truth和具有动态时间扭曲 (DTW) 的合成频谱图之间迭代地找到对齐路径,使梅尔频谱图有容错空间。 这种方法的主要目标是减轻两个频谱图必须完全对齐的要求。
总共的loss定义如下:
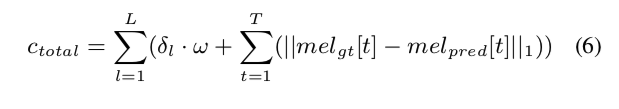
其中 $L$ 是梅尔谱图长度,$ω$ 是动作 2 和 3 发生的扭曲惩罚。$δ$ 是一个二进制指示符,当扭曲惩罚大于零时为 1。 对于我们的损失,我们使用 [29] 中的软最小值来产生 Soft-DTW。
结论
我们提出了一种端到端的文本到波形网络,该网络具有一种新颖的基于强化学习的持续时间对齐搜索方法。 该模型的优势在于代理能够通过基于奖励反馈的动作主动搜索最佳持续时间对齐。 我们进行了一系列实验来为我们的强化对齐器选择最佳奖励。 我们提出的模型能够以更准确的持续时间对齐和增强的合成音频自然度优于其他最先进的方法。