Hifi-GAN: 用于高效和高保真语音合成的生成对抗网络
摘要
最近关于语音合成的几项工作采用了生成对抗网络 (GAN) 来生成原始波形。虽然这些方法提高了采样效率和内存使用率,但它们的样本质量还没有达到自回归和基于流的生成模型的质量。在这项工作中,我们提出了 HiFi-GAN,它实现了高效和高保真语音合成。由于语音音频由具有不同周期的正弦信号组成,我们证明了对音频的周期性模式进行建模对于提高样本质量至关重要。单个说话者数据集的主观人类评估(平均意见得分,MOS)表明,我们提出的方法证明了与人类质量的相似性,同时在单个 V100 GPU 上生成 22.05 kHz 高保真音频的速度比实时快 167.9 倍。我们进一步展示了 HiFi-GAN 对看不见的说话者的 vocoder音频生成 和端到端语音合成的泛化能力。最后,HiFi-GAN 的小尺寸版本在 CPU 上生成样本的速度比实时快 13.4 倍,质量与自回归对应物相当。
Introduction
语音是人类最常用和最自然使用的通信接口之一。随着最近科技的发展,语音被用作亚马逊Alexa等人工智能(AI)语音助手服务的主要接口,也被广泛应用于汽车、智能家居等领域。因此,随着人们与机器对话的需求增加,正在积极研究合成人类语音等自然语音的技术。 近年来,随着神经网络的发展,语音合成技术有了飞速的发展。大多数神经语音合成模型使用两阶段管道:1)从文本中预测低分辨率中间表示,例如梅尔谱图或语言特征,以及 2) 从中间表示合成原始波形音频。第一阶段是从文本中对人类语音的低级表示进行建模,而第二阶段模型以每秒高达 24,000 个样本和高达 16 位保真度的方式合成原始波形。在这项工作中,我们专注于设计第二阶段模型,该模型可以有效地从梅尔频谱图合成高保真波形。
已经进行了各种工作来提高第二阶段模型的音频合成质量和效率。 WaveNet 是一种自回归 (AR) 卷积神经网络,它展示了基于神经网络的方法在质量上超越传统方法的能力。但是,由于 AR 结构,WaveNet 在每个前向操作中生成一个样本;合成高时间分辨率音频的速度非常慢。提出了基于流的生成模型来解决这个问题。由于它们能够通过并行转换相同大小的噪声序列来对原始波形进行建模,因此基于流的生成模型充分利用现代并行计算处理器来加速采样。 Parallel WaveNet 是一种逆自回归流 (IAF),经过训练以最小化其与称为教师的预训练 WaveNet 的 Kullback-Leibler 散度。与教师模型相比,它将合成速度提高到 1,000 倍或更多,而不会降低质量。 WaveGlow 消除了对教师模型进行提炼的需要,并通过采用基于 Glow 的高效双射流通过最大似然估计简化了学习过程。与 WaveNet 相比,它还可以产生高质量的音频。然而,它的深度架构需要很多参数,超过 90 层。
生成对抗网络 (GAN) 是最主要的深度生成模型之一,也已应用于语音合成。库马尔等人(2019) 提出了一种多尺度架构,用于在多个原始波形尺度上运行的鉴别器。考虑到复杂的架构,MelGAN 生成器足够紧凑,可以在 CPU 上进行实时合成。山本等人 (2020) 提出了多分辨率 STFT 损失函数来改进和稳定 GAN 训练,并且比 IAF 模型 ClariNet 实现了更好的参数效率和更少的训练时间。 GAN-TTS 通过在不同窗口大小上运行的多个鉴别器,成功地根据语言特征生成了高质量的原始音频波形,而不是梅尔谱图。与 Parallel WaveNet 相比,该模型还显示出更少的 FLOP。尽管有这些优势,但 GAN 模型与 AR 或基于流的模型之间的样本质量仍然存在差距。
我们提出了 HiFi-GAN,它比 AR 或基于流的模型实现了更高的计算效率和样本质量。由于语音音频由具有不同周期的正弦信号组成,因此对周期模式进行建模对于生成逼真的语音音频很重要。因此,我们提出了一个由小的子鉴别器组成的鉴别器,每个子鉴别器只获得原始波形的特定周期部分。这种架构是我们模型成功合成逼真语音音频的基础。当我们为鉴别器提取音频的不同部分时,我们还设计了一个模块,该模块放置多个残差块,每个残差块并行观察不同长度的模式,并将其应用于生成器。
HiFi-GAN 的 MOS 分数比最好的公开可用模型 WaveNet 和 WaveGlow 更高。它在单个 V100 GPU 上以 3.7 MHz 的速度合成人类质量的语音音频。我们进一步展示了 HiFi-GAN 对看不见的说话者的梅尔谱图反演和端到端语音合成的普遍性。最后,HiFi-GAN 的小尺寸版本只需要 0.92M 参数,同时超越了最好的公开可用模型和最快版本的 HiFi-GAN 样本,CPU 实时速度比实时快 13.44 倍,单个实时比实时快 1,186 倍。 V100 GPU 具有与自回归对应物相当的质量。
我们的音频样本可在演示网站上获得,并且我们将实施作为可重复性和未来工作的开源提供。
Hifi-GAN
2.1 Overview
HiFi-GAN 由一个生成器和两个判别器组成:多尺度和多周期判别器。 生成器和鉴别器进行对抗训练,还有两个额外的损失以提高训练稳定性和模型性能。
2.2 Generator
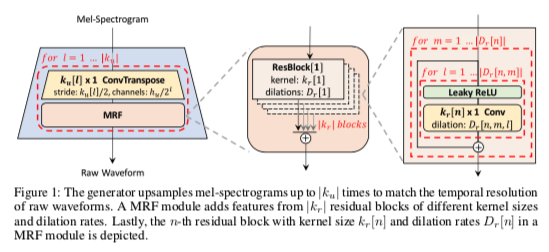
hifigan-fig1
生成器是一个完全卷积的神经网络。 它使用梅尔谱图作为输入,并通过转置卷积对其进行上采样,直到输出序列的长度与原始波形的时间分辨率相匹配。 每个转置卷积后跟一个多感受野融合 (MRF) 模块,我们将在下一段中描述。 图 1 显示了生成器的架构。 与之前的工作一样,噪声没有作为额外输入提供给生成器。
多感受野融合 我们为我们的生成器设计了多感受野融合(MRF)模块,它并行观察各种长度的模式。 具体来说,MRF 模块返回多个残差块的输出总和。 为每个残差块选择不同的内核大小和扩张率,以形成不同的感受野模式。 MRF 模块和残差块的架构如图 1 所示。我们在生成器中留下了一些可调参数; 可以调节隐藏维度 \(h_u\)、转置卷积的内核大小 \(k_u\)、内核大小 \(k_r\) 和 MRF 模块的膨胀率 \(D_r\),以在合成效率和样本质量之间进行权衡,以匹配自己的要求。
2.3 Discriminator
识别长期依赖关系是模拟真实语音音频的关键。例如,音素持续时间可能长于 100 毫秒,从而导致原始波形中超过 2,200 个相邻样本之间的高度相关性。这个问题在之前的工作中已经通过增加生成器和鉴别器的感受野得到了解决。我们专注于另一个尚未解决的关键问题;由于语音音频由不同周期的正弦信号组成,因此需要识别音频数据中的各种周期模式。
为此,我们提出了多周期鉴别器(MPD),它由几个子鉴别器组成,每个子鉴别器处理输入音频的一部分周期信号。此外,为了捕获连续模式和长期依赖关系,我们使用 MelGAN 中提出的多尺度鉴别器 (MSD),它连续评估不同级别的音频样本。我们进行了简单的实验来展示 MPD 和 MSD 捕获周期性模式的能力,结果可以在附录 B 中找到。
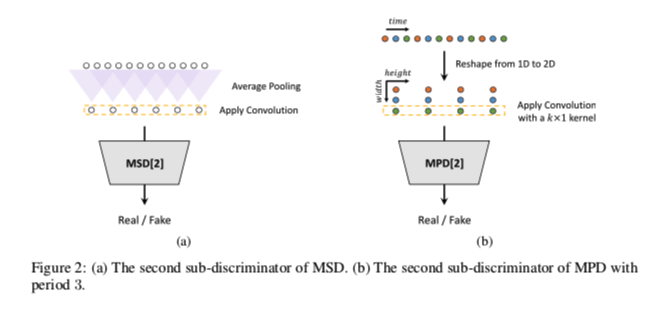
hifigan-fig2
Multi-Period Discriminator MPD 是子鉴别器的混合体,每个子鉴别器只接受输入音频的等距样本;空间以周期 \(p\) 给出。子鉴别器旨在通过查看输入音频的不同部分来捕获彼此不同的隐式结构。我们将周期设置为 \([2, 3, 5, 7, 11]\) 以尽可能避免重叠。如图 2b 所示,我们首先将长度为 \(T\) 的一维原始音频重塑为高度为 \(T /p\) 和宽度为 \(p\) 的二维数据,然后对重塑后的数据应用二维卷积。在 MPD 的每个卷积层中,我们将宽度轴上的内核大小限制为 1,以独立处理周期性样本。每个子鉴别器都是一堆带有泄漏校正线性单元 (ReLU) 激活的跨步卷积层。随后,将权重归一化应用于 MPD。通过将输入音频重塑为 2D 数据而不是采样音频的周期性信号,MPD 的梯度可以传递到输入音频的所有时间步长。
Multi-Scale Discriminator 因为 MPD 中的每个子鉴别器只接受不相交的样本,所以我们添加了 MSD 来连续评估音频序列。 MSD 的架构源自 MelGAN 的架构(Kumar 等,2019)。 MSD 是在不同输入尺度上运行的三个子鉴别器的混合:原始音频、×2 平均合并音频和 ×4 平均合并音频,如图 2a 所示。 MSD 中的每个子鉴别器都是一堆具有泄漏 ReLU 激活的跨步和分组卷积层。 通过减少步幅和添加更多层来增加鉴别器的大小。 除了对原始音频进行操作的第一个子鉴别器之外,还应用了权重归一化。 相反,应用了频谱归一化(Miyato 等人,2018 年)并按照其报道稳定了训练。
请注意,MPD 对原始波形的不相交样本进行操作,而 MSD 对平滑波形进行操作。
对于之前使用 MPD 和 MSD 等多鉴别器架构的工作,Bińkowski 等人 (2019)的作品也可以参考。工作中提出的鉴别器架构与 MPD 和 MSD 的相似之处在于它是鉴别器的混合,但 MPD 和 MSD 是基于马尔可夫窗口的完全无条件鉴别器,而它平均输出并具有条件鉴别器。此外,MPD 和 RWD 之间的相似性(Bin ́kowski et al., 2019)可以在重塑输入音频的部分考虑,但 MPD 使用设置为质数的周期来区分尽可能多周期的数据,而 RWD 使用重塑重叠周期的因素,并且不单独处理重构数据的每个通道,这与MPD的目标不同。 RWD 的一种变体可以执行与 MPD 类似的操作,但它在参数共享和对相邻信号的跨步卷积方面也与 MPD 不同。有关架构差异的更多详细信息,请参见附录 C。
2.4 训练损失函数
GAN 损失 为简洁起见,我们将我们的判别器 MSD 和 MPD 描述为贯穿第 2.4 节中的一个判别器。 对于生成器和鉴别器,训练目标遵循 LS-GAN,用最小二乘损失函数替换原始 GAN 目标的二元交叉熵项 对于非零梯度流。 训练判别器将真实样本分类为 1,将生成器合成的样本分类为 0。训练生成器通过将要分类的样本质量更新为几乎等于 1 的值来伪造判别器。 生成器 G 和鉴别器 D 的损失定义为
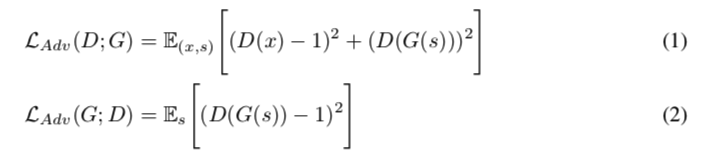
hifigan-al12
,其中 \(x\) 表示真实音频,\(s\) 表示输入条件,真实音频的梅尔谱图。
Mel-Spectrogram Loss 除了 GAN 目标函数之外,我们添加了 mel-spectrogram loss 以提高生成器的训练效率和生成的音频的保真度。 参考之前的工作,将重建损失应用于 GAN 模型有助于产生真实的结果,在 Yamamoto 等人 (2020) 的工作,通过联合优化多分辨率频谱图和对抗性损失函数,有效地捕获了时频分布。 我们根据输入条件使用了mel-spectrogram loss,由于人类听觉系统的特性,也可以预期它具有更加专注于提高感知质量的效果。 梅尔谱图损失是由生成器合成的波形的梅尔谱图与真实波形的梅尔谱图之间的 L1 距离。 它被定义为
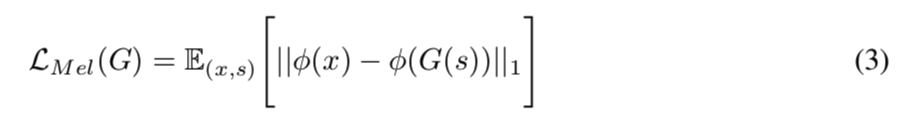
hifigan-al3
,其中 \(φ\) 是将波形转换为相应梅尔谱图的函数。 mel-spectrogram loss 帮助生成器合成与输入条件对应的真实波形,并从早期阶段稳定对抗训练过程。
特征匹配损失 特征匹配损失是一种学习的相似性度量,通过真实样本和生成样本之间鉴别器的特征差异来衡量。 由于它已成功用于语音合成,我们将其用作训练生成器的额外损失。 提取判别器的每一个中间特征,计算每个特征空间中一个ground truth样本和一个条件生成的样本之间的L1距离。 特征匹配损失定义为
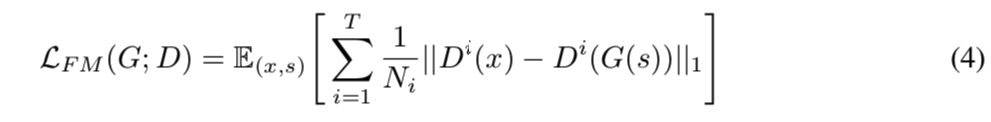
hifigan-al4
,其中 \(T\) 表示鉴别器的层数; \(D_i\) 和 \(N_i\) 分别表示鉴别器第 \(i\) 层的特征和特征数量。
最终损失 我们对生成器和鉴别器的最终目标是
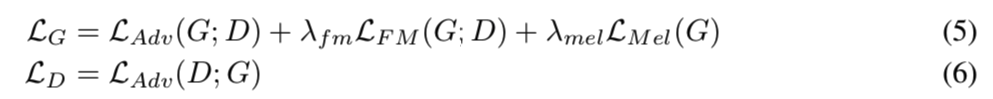
hifigan-al56
,其中我们设置 \(λ_{fm} = 2\) 和 \(λ_{mel} = 45\)。因为我们的判别器是一组 MPD 和 MSD 的子判别器,等式 5 和 6 可以相对于子判别器转换为
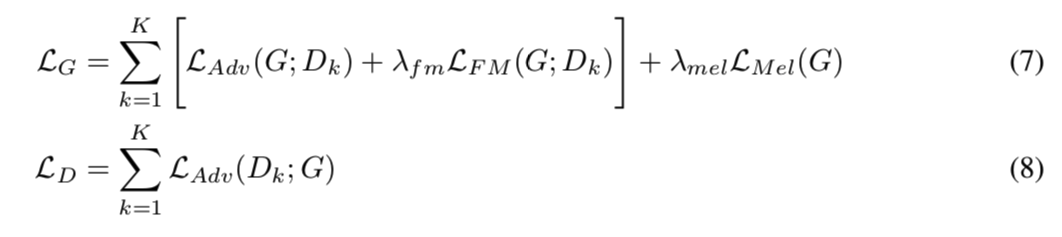 ,其中 \(D_k\) 表示 MPD 和 MSD 中的第 \(k\) 个子鉴别器。
,其中 \(D_k\) 表示 MPD 和 MSD 中的第 \(k\) 个子鉴别器。
结论
在这项工作中,我们引入了 HiFi-GAN,它可以有效地合成高质量的语音音频。最重要的是,我们提出的模型在合成质量方面优于性能最佳的公开可用模型,甚至可与人类水平相媲美。此外,它在合成速度方面显示出显着提高。我们从由不同周期的模式组成的语音音频的特征中汲取灵感并将其应用于神经网络,并通过消融研究验证了所提出的鉴别器的存在对语音合成的质量有很大影响。此外,这项工作提出了几个在语音合成应用中具有重要意义的实验。 HiFi-GAN 展示了从端到端设置中的嘈杂输入中概括看不见的扬声器并合成与人类质量相当的语音音频的能力。此外,我们的小尺寸模型展示了与最佳公开可用的自回归对应物相当的样本质量,同时在 CPU 上以比实时更快的数量级生成样本。这显示了设备上自然语音合成的进展,这需要低延迟和内存占用。最后,我们的实验表明,可以使用相同的判别器和学习机制训练各种配置的生成器,这表明可以根据目标规范灵活选择生成器配置,而无需耗时的超参数搜索鉴别器。
我们将 HiFi-GAN 作为开源发布。我们设想我们的工作将作为未来语音合成研究的基础。