声纹识别中的vectors
一、i-vector
i-vector 模型是输出一个400维的向量
二、d-vector
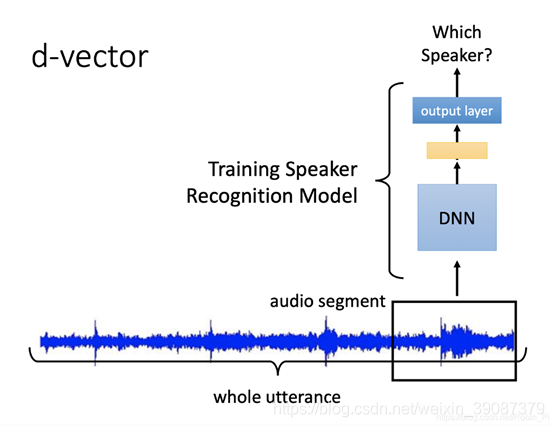
DNN 会输入一个固定长度的语音,对它做 Speaker Recognition。然后我们把这个模型的最后一层隐层抽取出来,它就是这段语音的 d-vector。不用 output layer 中的最后一层输出,因为它的维度是和训练时语者数目有关的。而是它前面的那一层隐层输出。
在实际预测的时候,输入语音是不等长的,会把语音截成多段,然后取这几段特征的d-vector的平均值作为最后的speaker embedding。
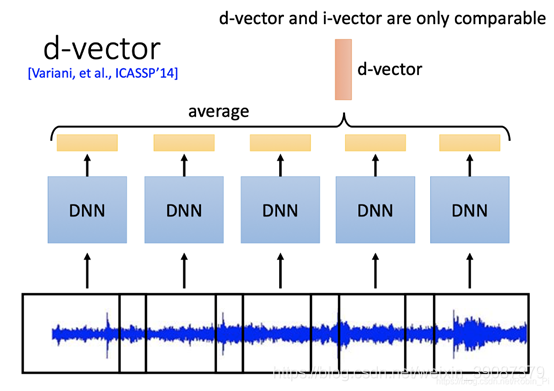
三、x-vector
x-vector 是d-vector的升级版,它不像 d-vector 那样简单的取平均,而是把每一小段的声音信号输出的特征,算一个 mean 和 variance,然后concat起来,再放进一个DNN里去来判断是哪个说话人说的。其他的部分和d-vector一致。
————————————————
版权声明:本文为CSDN博主「weixin_39087379」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_39087379/article/details/112795796

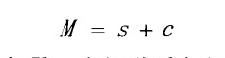
因子分析:
信息冗余是高维数据分析常见的问题,使用因子分析方法,可以将一些信息重叠和复杂的关系变量简化为较少的足够描述原有观测信息的几个因子,是一种数据降维的统计方法。本文介绍JFA和I-vector都为因子分析方法。