基于依赖解析的语义表示学习与图神经网络增强文本到语音的表达能力
摘要
句子的语义信息对于提高文本转语音 (TTS) 系统的表达能力至关重要,但仅凭借当今的编码器结构无法从有限的训练 TTS 数据集中很好地学习。随着大规模预训练文本表示的发展,来自转换器 (BERT) 的双向编码器表示已被证明可以体现文本上下文语义信息,并作为附加输入应用于 TTS。然而,BERT 不能从句子中的依赖关系点明确关联语义标记。在本文中,为了增强表达能力,我们提出了一种基于图神经网络的语义表示学习方法,考虑了句子的依赖关系。输入文本的依赖图由考虑正向和反向的依赖树结构的边组成。然后通过关系门控图网络 (RGGN) 在词级提取语义表示,该网络以来自 BERT 的特征作为节点输入。上采样语义表示和字符级嵌入被连接起来作为 Tacotron-2 的编码器输入。实验结果表明,我们提出的方法在 LJSpeech 和 Blizzard Challenge 2013 数据集中都优于使用 vanilla BERT 特征的基线,并且从相反方向学习的语义表示对于增强表达能力更有效。
Introduction
文本转语音 (TTS) 作为人机交互框架的一个组成部分,旨在从给定的文本中生成具有丰富表现力的自然语音。韵律是决定合成语音表达能力的关键因素。传统的统计参数 TTS 系统由文本分析模块、持续时间模型、声学模型和声码器组成,其中文本分析模块通常利用专家开发的人工语言特征,如词性(POS) 标签或自然语言解析相关结构,例如解析树,以从输入文本中捕获韵律线索。最近,端到端 TTS (E2E-TTS) 系统通过编码器-解码器结构简化了合成管道,并且在合成语音的自然性和可理解性方面取得了显着的成功。
由于这些 E2E-TTS 技术,例如 Tacotron-2 和 Deep Voice 3,使用编码器仅从文本(字符或音素)生成语言特征,并利用基于注意力的解码器直接生成原始频谱图,因此它们不需要复杂的文本分析或持续时间建模。 E2E-TTS 系统的输入通常通过使用标记器和语法解析器的上下文无关句法信息来丰富。但是,关于语义的部分信息仍可用于这些 E2E-TTS 系统,因为仅凭借当今的编码器结构,无法从训练 TTS 数据集中很好地学习此类信息。
由于预训练文本表示的发展,来自转换器 (BERT) 的双向编码器表示已被证明不仅体现了无文本的句法信息,还体现了文本上下文语义信息。现有的 E2E-TTS 扩展使用 BERT 来提高韵律性能。预训练的 BERT 首先作为附加输入引入 Tacotron-2,并显示平均意见得分的收益。类似的方法进一步验证了 BERT 在中文多说话者 TTS 任务中改善韵律的能力。沿着不同的路线,CHiVE-BERT 在基于 RNN 的语音合成模型中结合了 BERT 模型。这些方法通过利用来自 BERT 的短语和单词的语义信息改进了合成语音的韵律。
显式地结合依赖关系等句子结构有助于有效提高合成语音的自然度和表现力。然而,作为基于transformer的模型,由于训练任务的限制,BERT并没有明确地对依赖结构进行建模。结果,话语的呈现受到不利影响,尤其是对于长句。
为了在句子中明确地合并不同词汇标记之间的依赖关系,GraphSpeech 将输入词汇标记的关系从依赖解析引入到图注意力机制,这被证明对表示语义关联很有用。 然而,Graph-Speech 使用基于循环神经网络 (RNN) 的关系编码器来建模依赖关系,考虑到复杂的句子结构,这不足以捕获信息。 图神经网络 (GNN) 被进一步引入 TTS,因为它能够通过图节点之间的消息传递来学习表示,如 GraphTTS 和 GraphPB ,但所有的他们使用仅从文本中设计的简单结构,而没有考虑更深层次的语义。
为了更好地利用依存分析的句子级语义信息,我们提出了一种基于图神经网络的语义表示学习方法,考虑了句子的依存关系。输入文本的依赖图由考虑正向和反向的依赖树结构的边组成。然后通过关系门控图网络(RGGN)在单词级别提取语义表示,其中输入来自 BERT 的单词特征作为节点输入。上采样语义表示和字符级嵌入被连接起来作为 Tacotron-2 的编码器输入,然后是多频段 MelGAN 声码器 以生成合成语音。
实验结果表明,我们提出的方法在 LJSpeech 和 Blizzard Challenge 2013 数据集的自然度和表现力方面都优于使用 vanilla BERT 特征的基线,并且从相反方向学习的语义表示对于增强表现力更有效。还通过案例研究探索和证明了从依赖图中学习的语义表示的有效性。
2. Methodology
为了提高合成语音的表达能力,我们提出了一种基于图神经网络的语义表示学习方法,考虑了句子的依赖关系。 所提出方法的主要框架如图 1 所示。 在构建输入文本的依赖图后,使用两个单独的关系门控图网络 (RGGN) 来学习语义表示,这些表示作为附加输入传递给 Tacotron-2。
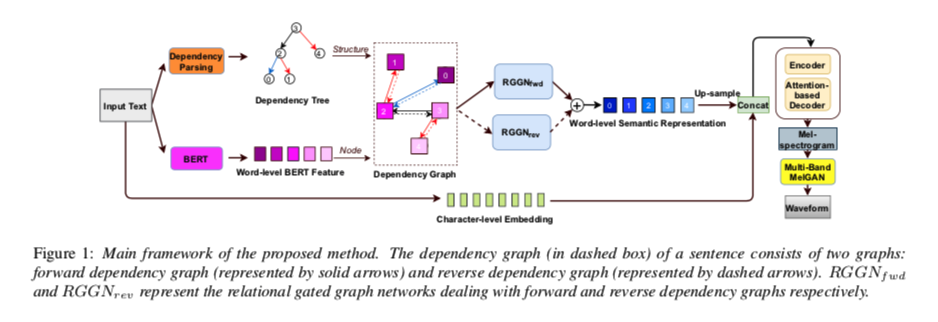
gnn-tts-fig1
2.1 依赖图构建
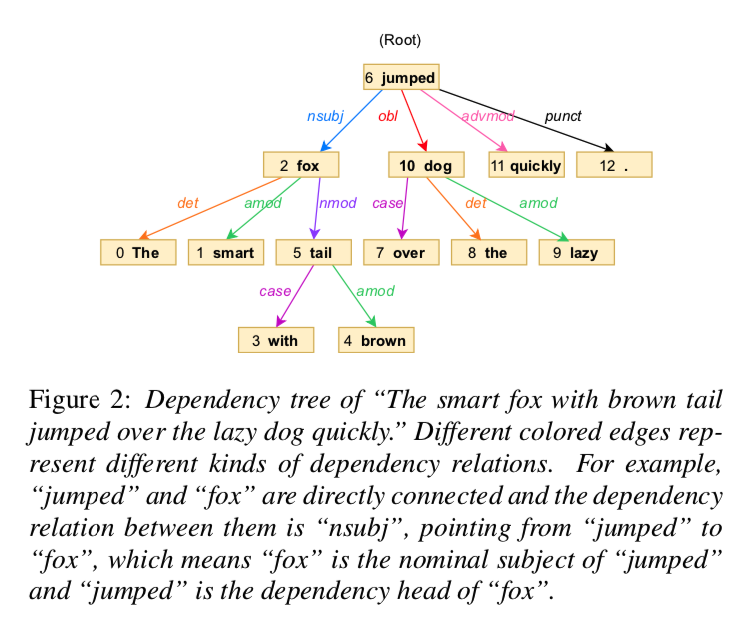
gnn-tts-fig2
在依存树中,使用双词化依存关系来描述词之间的关系进行语义分析,如图2所示。 我们使用图来表示语义标记的依赖关系,定义为 \(G = (V, E)\)。 节点 \(v ∈ V\) 表示句子中带有语义信息的标记,通常是一个词。 边是一对 \(e = (v_i,v_j) ∈ E\),它表示从节点 \(v_i\) 到节点 \(v_j\) 的有向边,具有特定的依赖关系。 并且不同类型的边代表不同类型的依赖关系。 一个句子可以表示为一个单词序列 \(W = [w_1 , w_2 , ..., w_n ]\),其中 \(n\) 是句子的单词数。 我们从 \(W\) 中提取语义表示和依赖树的结构,可以表述为:
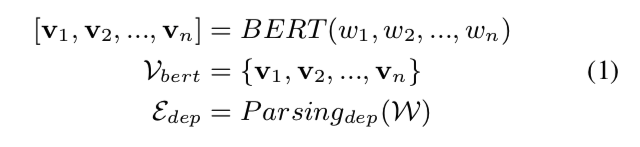
gnn-tts-al1
其中\(v_i\)是第\(i\)个词的BERT特征,组成节点集\(V_{bert}\),\(E_{dep}\)是依赖解析的关系边集,可以看作是\(W\)的依赖结构。
如图2所示,节点“jumped”指向原始依赖树中的节点“quickly”。 但考虑到“quickly”修饰“jumped”,子节点的语义信息应该同时影响父节点。 因此,我们使用两个信息流方向来构建依赖图。 前向定义为信息从父节点流向子节点,与依赖树一致。 反向定义为信息从子节点流向父节点,反向流向依赖树。 正反方向对应的结构可以表示为:
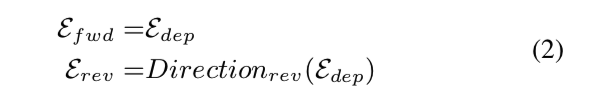
gnn-tts-al2
其中 \(E_{fwd}\) 是前向依赖结构,\(Direction_{rev}\) 是方向反转操作,\(E_{rev}\) 是 \(W\) 的反向依赖结构。 因此前向依赖图和反向依赖图可以表示为:
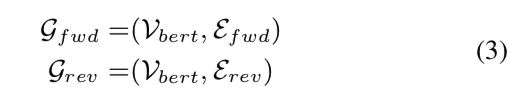
gnn-tts-al3
单词的语义信息会通过 \(G_{fwd}\) 和 \(G_{rev}\) 的拓扑结构直接或间接流向依赖节点。 这样,一个句子的依赖图就由依赖树构造出来,进一步传递给关系门控图网络进行语义表示学习。
2.2 关系图网络
关系门控图网络(RGGN)旨在从第 2.1 节中的依赖图学习语义表示。 门控图神经网络(GGNN)因其信息流的长期传播而被采用。 此外,受关系图卷积网络的启发,将对应于不同类型边的不同权重矩阵引入到GGNN。
RGGN 通过信息传播将依赖图映射到语义表示。 首先,隐藏状态 \(h^0_i\) 由节点 \(i\) 的词级 BERT 特征 \(v_i ∈ V_{bert}\) 发起。 然后传播步骤通过多次迭代计算每个节点的节点表示,表示为:
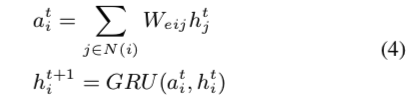
gnn-tts-al4
其中 \(N(i)\) 是节点 \(i\) 的邻居集,\(W_{eij}\) 表示传播中从节点 \(i\) 到 \(j\) 的边的权重参数,\(h^t_i\) 和 \(h^{t+1}_i\) 表示节点 \(i\) 在第 \(t\) 和 \(t+1\)次迭代中的隐藏状态,\(a_i^t\) 是节点 \(i\) t的邻居的隐藏状态 \(h^t_j\) 的加权和,\(GRU(·)\) 表示门控聚合器,它更新隐藏状态 \(h^t_i\) 合并来自邻居和节点的信息。 节点 \(i\) 的前一个迭代步骤。 在 RGGN 中,由于门控循环单元,节点可以在传播过程中保留长期信息。
多次迭代后图中节点的隐藏状态被视为图嵌入,通过显式连接收集相关节点的信息。 根据预先标记的节点顺序,我们将图嵌入用于与原始句子一致的词级语义表示序列。 因此,考虑到句子的依赖关系,我们可以获得每个单词的语义表示。
2.3 带有语义表示的 TTS
如图 1 所示,我们设计了两个 RGGNs \(RGGN_{fwd}\) 和 \(RGGN_{rev}\) 分别处理前向和反向依赖图,并且它们的参数不共享。 词级语义表示可以通过以下方式获得:
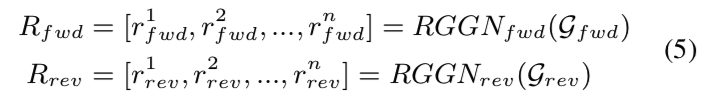
gnn-tts-al5
其中\(r^i_{fwd}\)是从前向依赖图中学习到的\(W\)中第\(i\)个单词的语义表示,\(r^i_{rev}\)是从反向依赖图中学习到的,\(R_{fwd}\)和\(R_{rev}\)是两个依赖图的语义表示序列。 此外,我们结合 \(R_{fwd}\)和 \(R_{rev}\) 来考虑正向和反向的依赖信息:
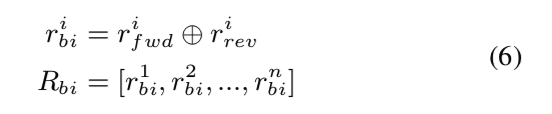
gnn-tts-al6
其中 \(⊕\) 是 \(r^i_{fwd}\) 和 \(r^i_{rev}\) 的元素相加操作,以获得第 \(i\) 个单词的语义表示 \(r^i_{bi}\),\(R_{bi}\) 是 \(r^i_{bi}\) 的序列。
然后将单词级语义表示上采样到字符级并与字符嵌入连接。 也就是说,我们复制单词级别的语义表示以匹配单词的字符长度。 然后将串联传递给 Tacotron 2 的编码器,然后是基于注意力的解码器以生成梅尔谱图。 波形最终使用以梅尔频谱图为条件的多频段 MelGAN 声码器合成。
结论
在这项研究中,我们提出了一种基于图神经网络的语义表示学习方法,考虑句子的依赖关系以增强表达能力。 构建依赖图时,正向和反向都考虑在内。 实验结果表明,我们提出的方法在两个数据集中都优于基线,并且从相反方向学习的语义表示对于增强表达能力更有效。