基于神经网络的 TTS 与句法解析树遍历的句法表示学习
摘要
句子文本的句法结构与语音的韵律结构相关,这对于提高文本到语音 (TTS) 系统的韵律和自然度至关重要。如今,TTS 系统通常尝试将句法结构信息与基于专家知识的手动设计特征结合起来。在本文中,我们提出了一种基于句法解析树遍历的句法表示学习方法,以自动利用句法结构信息。两个成分标签序列通过来自成分分析树的左先和右先遍历线性化。然后通过相应的单向门控循环单元 (GRU) 网络从每个组成标签序列中在单词级别提取句法表示。同时,引入了核范数最大化损失以增强组成标签嵌入的可辨别性和多样性。上采样的句法表示和音素嵌入被连接起来作为 Tacotron2 的编码器输入。实验结果证明了我们提出的方法的有效性,与基线相比,平均意见得分 (MOS) 从 3.70 增加到 3.82,ABX 偏好超过 17%。此外,对于具有多个句法分析树的句子,从合成语音中可以清楚地感知韵律差异。
Introduction
最近,基于神经网络的文本到语音 (TTS) 系统在合成语音的韵律和自然度方面取得了一定的成功,而不是传统方法。通过应用带有注意力的编码器-解码器框架,这些系统可以通过从语言空间到声学空间的灵活映射来学习声学和韵律模式,从而直接从字素或音素预测语音参数。然而,学习到的韵律模式仅包含部分韵律结构信息,导致韵律和自然性表现不佳,甚至不正确的韵律。
为了进一步提高合成语音的韵律和自然度,提出了在基于神经网络的 TTS 模型的输入序列中添加韵律结构注释,如音调和中断索引 (ToBI) 标签或其他韵律结构标签。韵律结构标注需要从语音中主观标注,耗时较长。
虽然这些注释可以通过训练另一个韵律结构预测模型自动注释,但预测的韵律结构标签的准确性仍然受到使用主观标记的注释作为基本事实的限制。成功的句法到韵律映射证明了句法结构和韵律信息之间的高度相关性。提出了一组基于规则的句法特征,例如词性 (POS) 和当前词在父短语中的位置,并用于基于隐马尔可夫模型 (HMM) 的声学模型。为了利用更多的句法结构信息,在基于神经网络的 TTS 中提出了基于短语结构的特征(PSF)和基于词关系的特征(WRF)。 PSF 和 WRF 扩展了 HMM 模型中使用的句法特征集。进一步引入了更多特征,例如以当前词开头的最高级别短语(HBCW)和最低共同祖先(LCA),以对句法结构进行建模。
然而,扩展的特征仍然是手动设计的特征,而不是自动学习的高级表示。 PSF 仅包含来自整个句法树结构的有限层的特征。 WRF 仅从整个句法分析树中暴露部分节点和边的信息。
为了更好地利用句法信息,受神经机器翻译中句法解析树遍历方法的启发,我们提出了一种句法表示学习方法,以进一步提高基于神经网络的 TTS 中合成语音的韵律和自然度。句法分析树通过左先和右先遍历线性化为两个组成标签序列。然后对每个序列使用不同的单向 GRU 网络从组成标签序列中提取句法表示。之后,句法表示从词级到音素级上采样,并与音素嵌入连接。 Tacotron 2 用于从连接的句法表示和音素嵌入生成频谱图,并使用 Griffin-Lim 来重建波形。将核范数最大化损失 (NML) 引入组成标签嵌入层以增强可辨别性和多样性。与仅使用左先遍历 相比,提出了右先遍历以减轻歧义。
实验结果表明,我们提出的模型在韵律和自然度方面优于基线。与基线方法相比,平均意见得分 (MOS) 从 3.70 增加到 3.82(t 检验,p=0.0079)。 ABX 偏好率超过基线方法 17%。对于具有多个不同句法解析树的句子,可以从相应的合成语音中清楚地感知韵律差异。
方法论
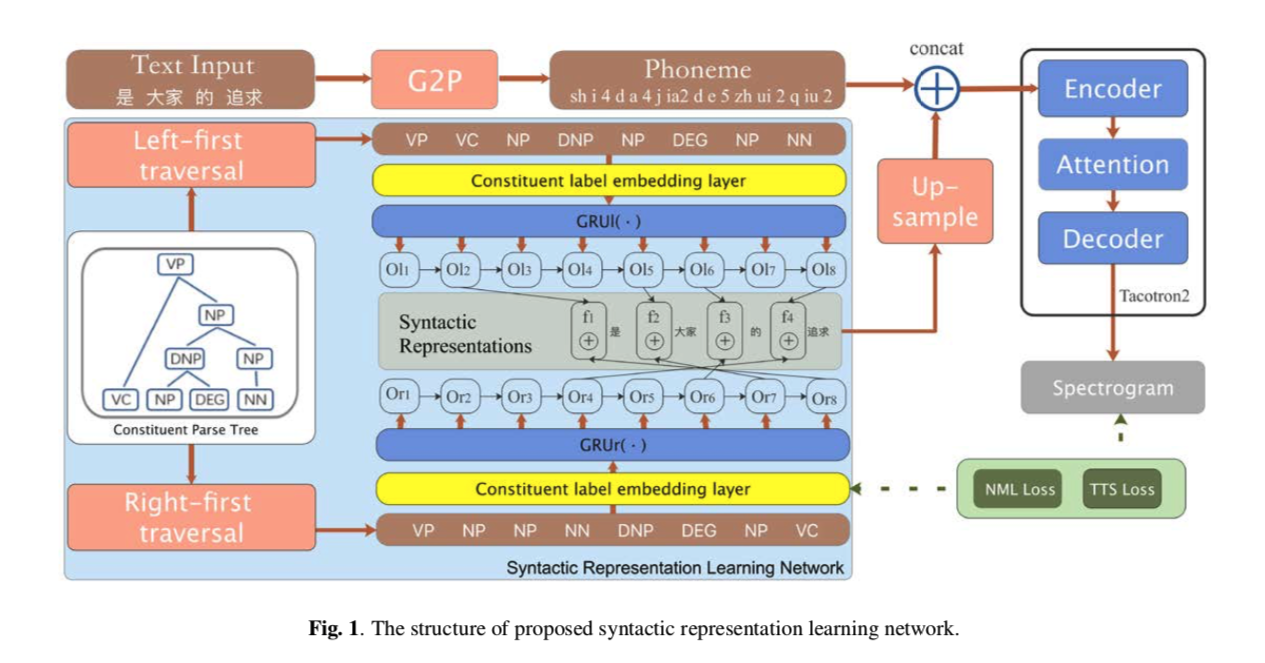
bi-traversal-fig1
图 1 显示了我们提出的方法的框架。 我们的工作主要集中在引入可训练的句法结构信息提取器作为基于神经网络的 TTS 系统的一部分,以提高合成语音的韵律和自然度。
2.1 句法表征学习
为了向基于神经网络的 TTS 系统提供具有丰富句法信息的高级句法表示,我们提出了一种基于句法分析树遍历的句法表示学习网络。 提取成分分析树,包括成分的标签和树结构。
为了表示基于神经网络的 TTS 的树结构,可以使用深度优先遍历将句法分析树线性化为组成序列。 由于任何单树遍历算法都会将多个句法分析树映射到同一序列,因此建议使用左优先和右优先来减轻歧义。 两次遍历生成的组成标签序列可以表示为以下等式:
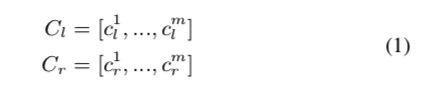
bi-traversal-al1
其中 \(C_l\) 和 \(C_r\) 分别是从左先遍历和右先遍历生成的组成标签序列,\(c^i_l\) 和 \(c^i_r\) 是组成标签,\(m\) 是序列的长度。 然后,组成标签由共享嵌入层嵌入,并由两个不同的单向 GRU 网络建模,每个序列一个 GRU 网络。 该过程可以表示为:
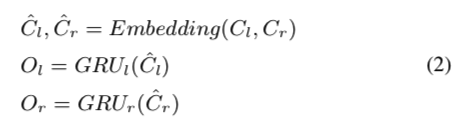
bi-traversal-al2
其中\(\hat C_l\)和\(\hat C_r\)是组成标签的嵌入序列,\(GRU_l(·)\)和\(GRU_r(·)\)是两个不同的单向GRU,\(O_l\)和\(O_r\)分别是\(GRU_l(·)\)和\(GRU_r(·)\)的输出。
句法特征是每个单词的 GRU 输出的串联,可以表示为:
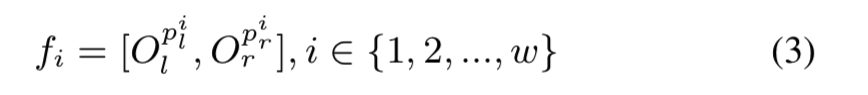
bi-traversal-al3
其中 \(p^i_l\) 和 \(p^i_r\) 是第 \(i\) 个单词在 \(C_l\) 和 \(C_r\) 中的位置,\(w\) 是输入文本的单词数,\(f_i\) 是学习到的句法表示。
2.2 核范数最小化损失
为了提高句法标签嵌入的可辨别性和多样性,提出了全局核范数最大化损失(NML)来增加所有可能的组成标签的嵌入的等级。 NML 定义为:
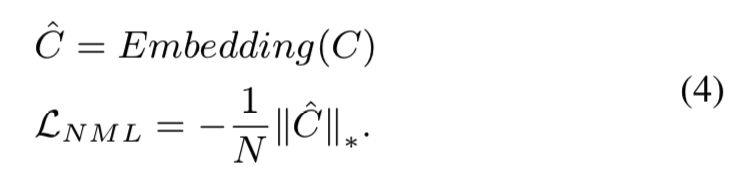
bi-traversal-al4
其中 \(C\) 是所有可能的组成标签的集合,\(\hat C\) 和 \(N\) 分别是 \(C\) 的嵌入和长度。 \(∥\hat C∥_∗\) 计算如下:

bi-traversal-al5
其中 \(σ_i\) 是 \(\hat C\) 的第 \(i\) 个奇异值。
2.3 带有句法表示的 TTS
学习到的句法表示与单词相关,它们被上采样到音素级别并与音素嵌入连接。 复制句法表示以匹配当前单词的音素序列长度。 Tacotron 2 用于从连接的句法表示和音素嵌入生成频谱图,并进一步利用 Griffin-Lim 来重建波形。 整个模型使用损失函数进行训练,损失函数可以表示为:
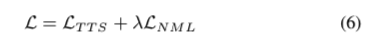
bi-traversal-al6
其中 \(L_{TTS}\) 是 Tacotron 2 中定义的损失函数,\(λ\) 是 NML 的损失权重。
实验
实验部分挺有趣的,只展示两张频谱图
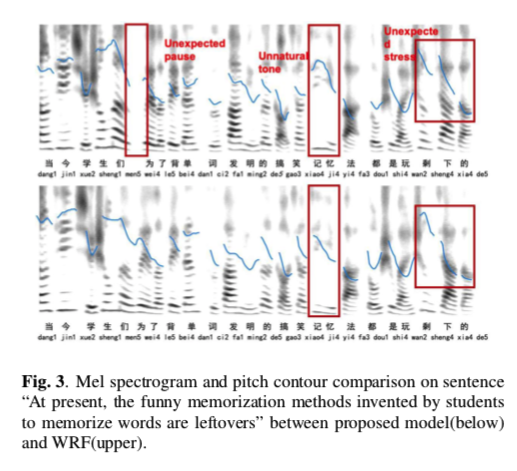
bi-traversal-fig3
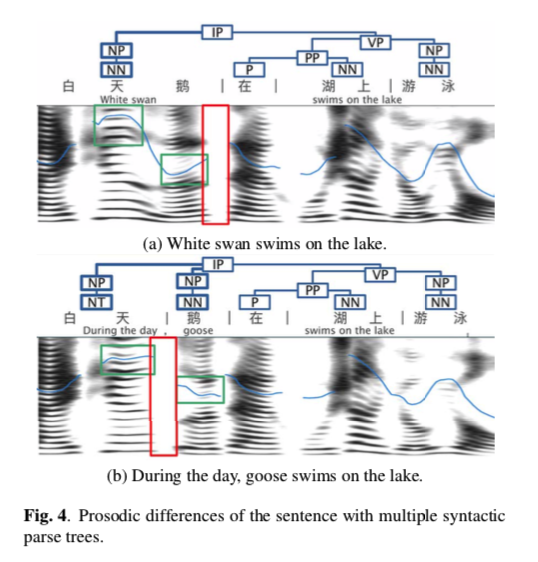
bi-traversal-fig4
结论
在这项研究中,我们研究了一种句法表示学习方法,以自动利用基于神经网络的 TTS 的句法结构信息。 引入核范数最大化损失以增强合成语音韵律的可辨别性和多样性。 实验结果证明了我们提出的方法的有效性。 对于具有多个句法分析树的句子,从合成的语音中可以清楚地观察到韵律差异。