利用解析树中的句法特征来改进端到端 TTS
摘要
端到端 TTS 可以直接从给定的字素或音素序列预测语音,其性能优于传统 TTS。 然而,它的预测能力仍然受到训练数据的声学/语音覆盖范围的限制,通常受训练集大小的限制。 为了进一步提高发音、韵律和感知自然度的 TTS 质量,我们建议利用嵌入在句法分析树中的信息,其中句子的短语/单词信息组织在多级树结构中。 具体来说,研究了两个关键特征:短语结构和相邻词之间的关系。 在三个测试集上测量的主观听力实验结果表明,所提出的方法可有效提高基线系统合成语音的发音清晰度、韵律和自然度。
Introduction
文本到语音 (TTS) 系统的评估侧重于测量可懂度、自然度、韵律和说话人相似度等几个因素。传统的基于语音参数的 TTS 系统已经实现了高可懂度,例如,基于 GMM-HMM 的和基于 NN 的统计语音合成。最近,基于 WaveNet 或 WaveRNN 的神经声码器的语音质量也有了很大的提高,它可以通过从生成的声学特征中预测语音样本来产生高质量的语音。然而,它在发音、韵律和自然度方面的预测能力仍然受到其声学/语音覆盖范围和可用于训练的数据量的限制。
在传统的英语 TTS 中,通常使用 ToBI 标签来转录韵律变化,包括:重音、强调、停顿等。训练数据的语音韵律可以在 ToBI 中手动或自动进行注释,以训练一个 ToBI 韵律模型来预测给定文本中的 ToBI 标签。注释基于文本和音频,但在预测中只有文本可用。需要考虑长期上下文来预测韵律的高质量 ToBI 韵律模型可能难以使用有限的文本-语音配对数据进行训练。此外,需要预测持续时间、中断、发声和 F0 轮廓的模型可以使训练更具挑战性。韵律模型的预测误差可以累积,然后降低对 TTS 频谱参数的预测,并导致合成语音中出现意外故障。此外,ToBI 标签序列不能完全表征韵律信息。
最近,提出了端到端的 TTS 训练,例如,char2wav、Tacotron和 Tacotron2以统一的方式直接从字素或音素预测语音参数,无需手动注释语音数据来训练模型。它可以通过最小化迭代训练循环中的预测误差,通过语言空间到声学空间之间的灵活映射来学习各种声学模式。端到端模型中的所有模块都是联合训练的,因此可以避免因训练模块分离而导致的累积误差。实验结果表明,端到端模型的性能优于传统的统计 TTS。但是,仍然会出现问题,例如错误的重音模式、不合理的中断、错误的发音,特别是对于训练数据覆盖的域之外的长而复杂的测试句子。由此产生的较差的泛化会严重降低相应的 TTS 性能。
端到端模型是一种高度依赖于序列信息的序列到序列模型。但是训练句子的大小不足以覆盖目标(文本)域,包括不同的长度和上下文。为了提高模型的泛化能力,我们需要尽可能提高我们的数据在文本域上的覆盖率,最好的方法是提高数据的泛化能力。仅由字素或音素组成的序列泛化性低,因为每个序列都指特定的案例,不能代表一些具有共同特征的案例。这就导致了很多情况在训练集中没有很好覆盖的问题。所以我们可以使用更高级、更抽象的特征来描述序列,以提高输入数据的覆盖率和泛化能力。语义信息和句法信息正是我们所需要的。
在本文中,我们将尝试利用句法信息,特别是从用于端到端 TTS 的句法解析树中得出的语言特征。 句法解析是一种广泛使用的句法分析工具。 它也称为“短语结构解析”,可以描述句子中单词之间的短语结构和短语级关系。 我们从 TTS 的角度对句法解析进行了系统的研究,并从不同的角度提出了一系列基于句法解析的特征,以帮助优化端到端的 TTS 模型。 我们使用三个不同的测试集从三个方面评估我们的模型,在普通测试集上的性能,在复杂句子上的性能和在病理测试集上的泛化。 实验结果表明,这些特征有助于提高韵律和泛化能力。
句法解析衍生的语言特征
2.1 句法解析
句法解析将句子分解为其句法短语树结构。树中的组件有其对应的级别和语法角色,例如名词短语和动词短语。包含多个单词的短语也可以进一步解析为子短语,直到到达单词的末端叶子为止。句法解析可以递归地对一个例句进行,如图1所示。近年来,解析技术的研究取得了长足的进步,出现了许多新的解析算法,如概率上下文无关文法(PCFG)、分解解析器、Shift-Reduce解析器和直接到树。改进的解析性能带来了更少的歧义和更稳定的句法分析。用具有丰富语法结构的大型文本数据库训练的句法解析模型可以为 TTS 提供有用的句法特征。
早些年,句法解析主要用于帮助构建更好的基于规则的韵律预测模块。例如,描述了一个基于规则的系统,通过句法解析来推断韵律短语。然后随着统计参数语音合成的发展,句法解析衍生的特征可以用作韵律预测的前端。在一些文献中,提出了从句法分析中提取的特征以改进韵律预测。在某文献中,作者的目的是建立一个模型,该模型可以从句法树映射到韵律树,以改进中断索引标记。新研究还尝试使用句法解析来改进基于 HMM 或 DNN 的声学模型。实验结果表明,句法解析可以改善 TTS 的韵律。
在本节中,我们将尝试从短语结构和词关系两个方面对句法解析进行系统分析,并测试深层句法解析衍生的语言特征以提高 TTS 性能。
2.2 基于短语结构的特征
当我们以宏观的方式研究句法树结构时,树在多个层次上描述了一个短语结构。 短语结构控制着句子的句法框架。 句子的节奏和语调本质上嵌入在基于树的短语结构中。 我们采用从短语结构中导出的特征来表征句法信息:
词性 (POS: Part-of-speech)
短语标签,例如 S、NP、VP 和 PP。
短语第一个词的短语边界标签
词在短语中的相对位置。 \(𝑅_𝑤 = 𝑃_𝑤/𝑁_𝑝\) \(𝑃_𝑤\):当前词在当前词组中的位置
\(𝑁_𝑝\):当前词组词数

syntactic-tree-tts-fig1
例如,图1中的“like”是其父节点的边界,即\(VP\); 它的POS是\(VBP\); 它在 \(S\) 中的相对位置是 \(𝑅_𝑤 = 5/9\)(“.”也是一个词); 它属于高级短语,\(S\) 和 \(VP\)。
这些特征可以捕获句子的结构信息,然后用该信息影响每个单词。 当我们使用基于短语结构的特征时,我们需要固定层数和选择特定层的方式。 不同的大小和方法会对韵律产生不同的影响。 在3.2.1中,我们将讨论层的选择。
2.3 基于词关系的特征
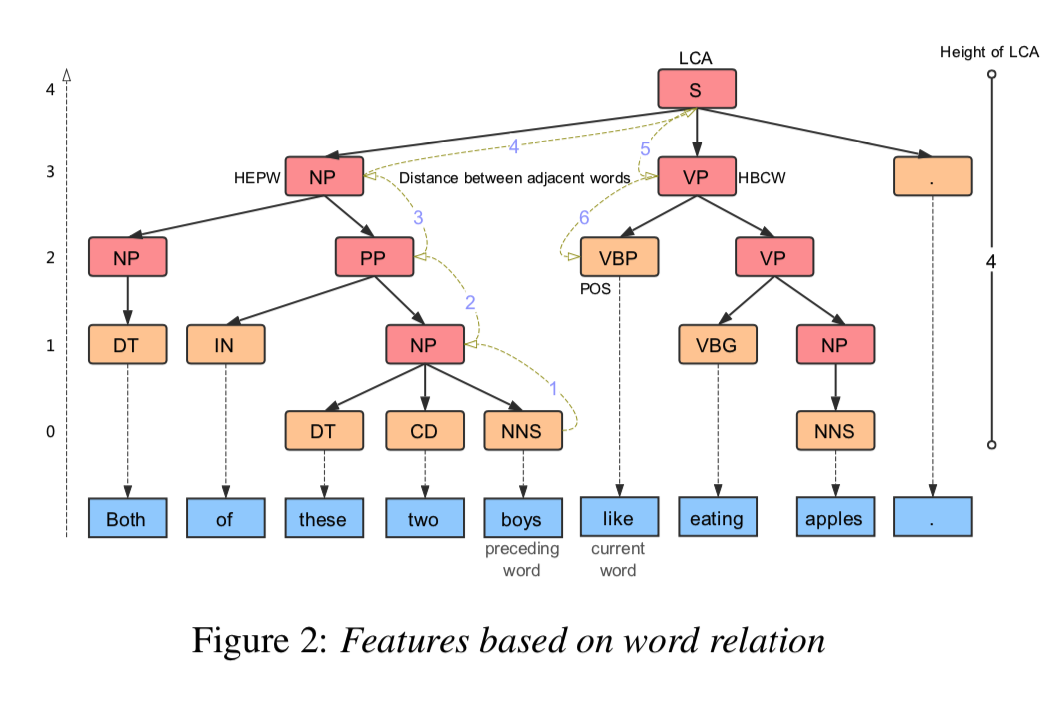
syntactic-tree-tts-fig2
短语结构中的高冗余使得仅使用有限的文本数据更难提取用于韵律预测的有用信息。 出于这个原因,我们建议改进功能。 我们都知道 ToBI 中的特征是基于单词或较低级别的音素,如重音、重音和中断。 因此,我们希望通过提取一些既可以描述单词的句法属性又可以描述两个相邻单词之间关系的特征来关注树中单词之间的关系,以帮助学习这些韵律特征。 我们定义特征并将它们用图 2 解释为:
一个词的词性。 (橙色部分)
与两个相邻词的结合点相关的短语。中断或停顿只发生在两个相邻词之间。我们在本文中对其进行了扩展,如果我们将 NONE 设置为每个单词的第一个短语,则会在两个相邻的短语之间发生中断。例如,“boys”和“like”交界处的短语是\(NP\)和\(VP\),“like”和“eating”交界处的短语是\(NONE\)和\(VP\)。为了找到这两个短语,我们采用以下两个标准:
当前单词开头的最高级别短语 (HBCW)。
以前一个词结尾的最高级别短语 (HEPW)。
最低共同祖先(LCA),由两个相邻词组成的最低级节点。在图2中,\(S\)是“boys”和“like”的\(LCA\),第二级\(VP\)是“eating”和“apples”的\(LCA\)。
句法距离。它显示了树中两个相邻单词之间的距离。更长的距离可能导致更高的概率中断更长的停顿。我们定义了以下与句法距离相关的特征:
- 高度 (\(𝐻\)):树中的水平。 \(𝐻_𝑙\) , \(𝐻_𝑐\) , \(𝐻_𝑝\) 分别表示 \(LCA\) 的级别,当前词的 POS 和前一个词的 POS。
- 距离(\(𝐷\)):树中节点之间的最短路径长度(不包括单词)。 \(𝐷_{𝑐𝑙}\), \(𝐷_{𝑝𝑙}\), \(𝐷_{𝑐𝑝}\) 是指 LCA 与当前 POS、LCA 与前一个 POS、当前 POS 和前一个 POS 之间的距离。
“like”的\(𝐷_{𝑐𝑝}\)是从NNS到VBP的最短路径的长度。 我们可以添加 \(𝐷_{𝑐𝑙}\) 和 \(𝐷_{𝑝𝑙}\) 来得到它的值。 (\(𝐷_{𝑐𝑙} = 𝐻_𝑙 -𝐻_𝑐;𝐷_{𝑝𝑙} = 𝐻_𝑙 -𝐻_𝑝;𝐷_{𝑐𝑝} = 𝐷_{𝑐𝑙} +D_{pl}\))
模型结构图见如下图3
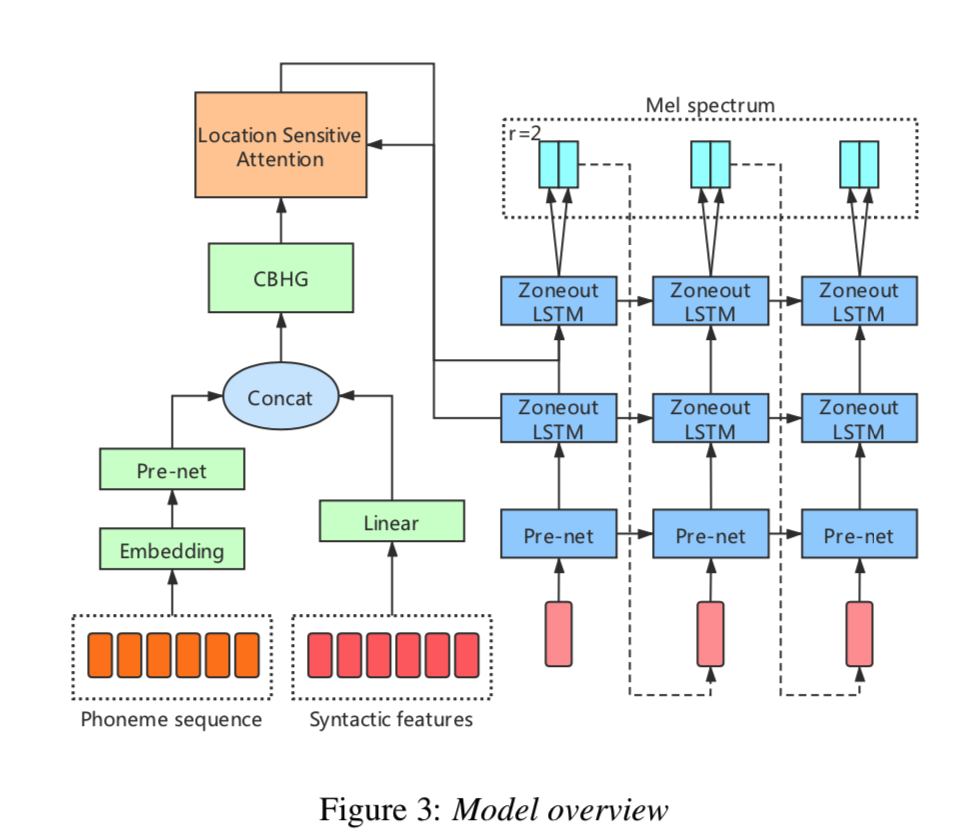
syntactic-tree-tts-fig3
实验结果见如下图4,其中本文提出的模型对于4个had进行了较好程度的建模,建模出了不同的音高和韵律。
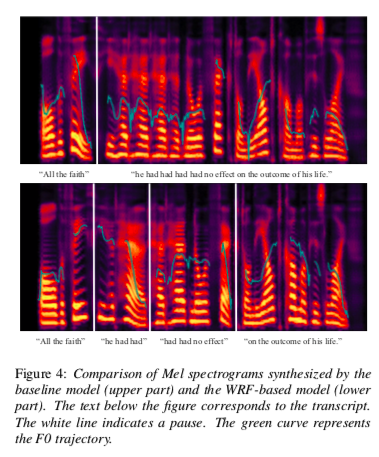
syntactic-tree-tts-fig4
结论
在这项研究中,我们研究了嵌入在解析树中的句法解析派生特征,以提高端到端 TTS 合成性能。 两个特定的特征,短语结构和词关系,被有利地选择来测试它们对韵律预测、发音清晰度、自然性和端到端 TTS 合成的泛化的影响。 实验结果表明,句法特征确实可以提高合成语音在韵律、可理解性和概括性方面的质量。 基于词关系的特征 (WRF) 在检查的三个测试集上产生最佳性能。