Parrotron: 端到端语音到语音转换模型及其在听障语音和语音分离中的应用
概述
Project Parrotron 致力于开发可以省略中间步骤,不参考视觉提示(如嘴部运动),直接将非标准语音转化为标准语音的技术,以帮助语言障碍者与人和设备都能更好的交流。
摘要
我们描述了 Parrotron,这是一种端到端训练的语音到语音转换模型,可将输入频谱图直接映射到另一个频谱图,而无需使用任何中间离散表示。该网络由编码器、频谱图解码器和音素解码器组成,最后接上一个声码器以合成时域波形。我们证明,该模型可以被训练,以归一化来自任何说话者的语音为具有固定口音和一致发音和韵律的单个规范目标说话者的语音,不管其口音、韵律和背景噪声如何。我们进一步表明,这种归一化模型可以适用于对聋哑人的高度非典型语音进行归一化,从而显着提高可懂度和自然度,通过语音识别器和听力测试进行测量。最后,展示了该模型在其他语音任务上的实用性,我们表明可以训练相同的模型架构来执行语音分离任务。
Introduction
具有注意力的编码器-解码器模型最近在建模各种复杂的序列到序列问题方面取得了相当大的成功。 这些模型已成功用于处理语音和自然语言处理中的各种任务,例如机器翻译、语音识别,甚至组合语音翻译。 他们还在端到端文本到语音 (TTS) 合成和自动语音识别 (ASR) 方面取得了最先进的结果,在给定几乎原始输入的情况下,使用单个神经网络直接生成目标序列。
在本文中,我们结合基于注意力的语音识别和合成模型来构建直接的端到端语音到语音序列转换器。 该模型根据不同的输入频谱图生成语音频谱图,没有中间离散表示。
我们测试这样一个统一模型是否足够强大,可以将来自多种口音、缺陷(可能包括背景噪声)的任意语音归一化,并在单个预定义目标说话者的语音中生成相同的内容。 任务是投射掉所有非语言信息,包括说话者特征,只保留所说的内容,而不是说的人、地点或方式。 这相当于一个独立于文本的多对一语音转换任务。 我们使用 ASR 和听力研究在此语音归一化任务上评估模型,验证它是否能够按预期保留基础语音内容并投射其他信息。
我们证明了预训练的归一化模型可以适应执行更具挑战性的任务,将聋哑人的高度非典型语音转换为流利的语音,显着提高可懂度和自然度。最后,我们评估同一网络是否能够执行语音分离任务。鼓励读者在配套网站上收听声音示例。
已经提出了多种语音转换技术,包括映射码本、神经网络、动态频率扭曲和高斯混合模型。最近的工作还涉及口音转换。在本文中,我们提出了一种直接生成目标信号的端到端架构,从头开始合成它。它与最近关于序列到序列语音转换的工作最相似。 使用类似的端到端模型,以说话人身份为条件,将来自多个说话人的词段转换为多个目标语音。与为每个源-目标说话人对训练单独模型的不同,我们专注于多对一转换。我们的模型在源-目标频谱图对上进行训练,没有使用来自预训练语音识别器的瓶颈特征来增强输入,以更明确地捕获源语音中的音素信息。然而,我们确实发现多任务训练模型来预测源语音音素很有帮助。最后,相比来说,我们在没有辅助对齐或自动编码损失的情况下训练模型。
类似的语音转换技术也已应用于提高有声乐障碍的说话者的可懂度,尤其是听力受损的说话者。 我们将更现代的机器学习技术应用于这个问题,并证明,如果有足够的训练数据,端到端训练的一对一转换模型可以显着提高聋哑人的清晰度和自然度。
模型架构
我们使用端到端的序列到序列模型架构,该架构采用输入源语音并生成/合成目标语音作为输出。 这种模型的唯一训练要求是成对的输入-输出语音的平行语料库。 我们将此语音到语音模型称为 Parrotron。
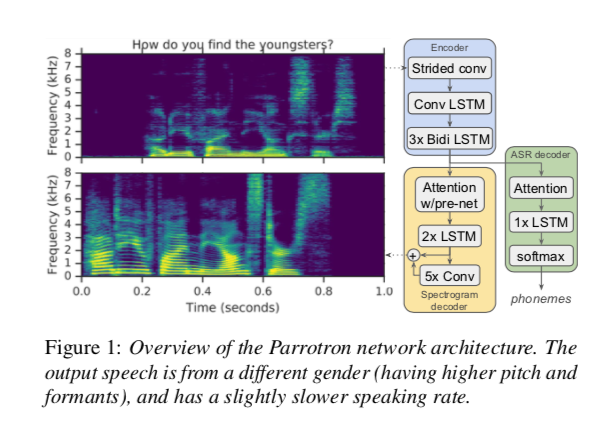
如图 1 所示,网络由一个编码器和一个带注意力的解码器组成,然后是一个声码器来合成时域波形。 编码器将一系列声学帧转换为隐藏特征表示,解码器使用该表示来预测频谱图。 核心架构基于最近基于注意力的端到端 ASR 模型和 TTS 模型,例如 Tacotron。
2.1 频谱编码器
基本编码器配置类似于Tacotron-2中的编码器,并且在第 3.1 节中评估了一些变化。从以 16 kHz 采样的输入语音信号中,我们提取了 125-7600 Hz 范围内的 80 维 log-mel 频谱图特征,使用 Hann 窗口、50 ms 帧长、12.5 ms 帧偏移和 1024 点计算短时傅立叶变换 (STFT)。
输入特征被传递到具有 ReLU 激活的两个卷积层的堆栈中,每个卷积层由 32 个内核组成,在时间 × 频率维度上,形状为 3 × 3 ,步幅为 2 × 2,按总因子4按时间对序列进行下采样,减少以下层的计算量。在每一层之后应用批量标准化。
使用 1 × 3 滤波器将此下采样序列传递到双向卷积 LSTM (CLSTM) 层,即在每个时间步长内仅在频率轴上进行卷积。最后,将其传递到每个方向上大小为 256 的三个双向 LSTM 层的堆栈中,与 512 维线性投影交错,然后是批处理规范和 ReLU 激活,以计算最终的 512 维编码器表示。
2.2 频谱解码器
解码器目标是 1025-dim STFT 幅度,使用与输入特征相同的帧和 2048 点 FFT 计算。我们使用Tacotron-2中描述的解码器网络,该网络由一个自回归 RNN 组成,以一次一帧地预测来自编码输入序列的输出频谱图。来自前一个解码器时间步长的预测首先通过一个包含 2 个全连接层的小型预网络,其中包含 256 个 ReLU 单元,这有助于学习注意力。 pre-net 输出和注意力上下文向量被连接起来,并通过 2 个单向 LSTM 层的堆栈,具有 1024 个单元。 LSTM 输出和注意力上下文向量的串联然后通过线性变换进行投影,以产生对目标频谱图帧的预测。最后,这些预测通过 5 层卷积 post-net,它预测要添加到初始预测的残差。每个 post-net 层都有 512 个过滤器,形状为 5 × 1,然后是批量归一化和 tanh 激活。
为了从预测的频谱图合成音频信号,我们主要使用 Griffin-Lim 算法来估计与预测幅度一致的相位,然后是逆 STFT。然而,在进行人类听力测试时,我们改为使用 WaveRNN神经声码器,该声码器已被证明可以显着提高合成保真度。
2.3 使用 ASR 解码器进行多任务训练
由于这项工作的目标是仅生成语音而不是任意音频,因此联合训练编码器网络以同时学习底层语言的高级表示有助于使频谱图解码器预测偏向于相同底层语音的表示内容。我们通过添加一个辅助 ASR 解码器来预测输出语音的(字素或音素)转录本,以编码器潜在表示为条件来实现这一点。这种经过多任务训练的编码器可以被认为是学习输入的潜在表示,该表示维护有关底层转录本的信息,即更接近在 TTS 序列到序列网络中学习的潜在表示。
解码器输入是通过将上一步发出的字素的 64 维嵌入和 512 维注意力上下文连接起来创建的。这被传递到一个 256 单元的 LSTM 层。最后,将注意力上下文和 LSTM 输出的串联传递到 softmax 中,以预测输出词汇表中每个字素的概率。
结论
我们描述了 Parrotron,这是一种端到端的语音到语音模型,可将输入频谱图直接转换为另一个频谱图,无需中间符号表示。我们发现可以训练该模型将来自不同说话者的语音标准化为单个目标说话者的语音,同时保留语言内容并投射掉非语言内容。然后我们表明,该模型可以成功地适用于改善失聪者语音的 WER 和自然度。我们最终证明,可以训练相同的模型来成功识别、分离和重建重叠语音混合中最响亮的说话者,从而提高 ASR 性能。 Parrotron 系统还有其他潜在的应用,例如通过将重口音或其他非典型语音转换为标准语音来提高可懂度。将来,我们计划在其他语言障碍上对其进行测试,并采用中的技术来保留说话者的身份。