使用 Transformer 网络进行无声码器的端到端语音转换
摘要
与原始频谱相比,基于梅尔频率滤波器组 (MFB) 的方法具有学习语音的优势,因为 MFB 具有较小的特征尺寸。然而,使用 MFB 方法的语音生成器需要额外的声码器,这需要大量的训练过程计算开销。附加的前/后处理(例如 MFB 和声码器)对于将真实的人类语音转换为其他语音不是必不可少的。可以只使用原始频谱和相位来生成具有清晰发音的不同风格的声音。在这方面,我们提出了一种快速有效的方法,以并行方式使用原始频谱转换逼真的声音。我们的基于转换器的模型架构没有任何 CNN 或 RNN 层,显示了快速学习的优势,并解决了传统 RNN 顺序计算的局限性。在本文中,我们介绍了一种使用 Transformer 网络的无声码器的端到端语音转换方法。所提出的转换模型也可用于语音识别的说话人自适应。我们的方法可以在不使用 MFB 和声码器的情况下将源语音转换为目标语音。我们可以通过将转换后的幅度乘以相位来获得用于语音识别的自适应 MFB。我们分别使用自然度、相似度和清晰度等指标和平均意见得分对 TIDIGITS 数据集进行语音转换实验。
Introduction
语音转换在各个工业领域都获得了相当大的关注。最近,使用循环神经网络 (RNN) 构建的编码器-解码器模型,例如长短期记忆 (LSTM) 、双向长短期记忆 (BiLSTM) 和门控循环单元 (GRU) 已被广泛用于序列建模。有很多基于 RNN 编码器-解码器结构的神经网络模型,也称为序列到序列(Seq2Seq),它们在语音转换任务中取得了良好的效果。
然而,RNN 为每个序列一个一个地处理单词。 RNN 的这种顺序特性可能成为 GPU 并行计算的障碍,并使训练速度变慢。最重要的是,如果这些时间信息变长,模型往往会忘记远处位置的内容或将其与下一个位置的内容混合。 Transformer 网络通过使用注意力机制来推导输入和输出之间的全局依赖性,部分解决了 RNN 的这些问题,在许多领域达到了最先进的性能。没有任何卷积神经网络 (CNN) 或 RNN 层的 Transformer 显示了快速学习的优势,并解决了传统 RNN 顺序计算的局限性。
将波形语音作为语音转换的模型输入,短时傅立叶变换 (STFT) 将其转换为时频域形式的原始频谱。用 STFT 计算的频谱可以提供比波形语音更有用的信息。特别是,文本到语音 (TTS)、语音转换和语音识别中使用的传统方法通过原始频谱传递梅尔滤波器组以生成梅尔频率滤波器组(MFB,也称为梅尔谱图)。在 MFB 中,频谱的频率分量是在 STFT 之后获得的。之后,根据反映人耳耳蜗特性的梅尔曲线对其进行压缩。在 MFB 中,相位信息在压缩时会被删除。
MFB 由每个时间步长 40 到 80 个特征维度组成,与原始频谱相比具有学习速度的优势,因为 MFB 的特征尺寸较小。但是,由于丢失了相位信息,它不能直接转换为波形语音。因此,采用 MFB 方法的语音生成器需要额外的声码器,这需要大量的训练过程计算开销。换句话说,馈入 Seq2Seq 的 MFB 应该在合成线性标度谱的声码器的帮助下通过相位估计合成自然语音。然后,它可以将模型的最终输出转化为波形语音。
因此,采用 MFB 方法的语音生成器需要额外的声码器,这需要大量的训练计算过程。使用 Griffin-Lim 和 WaveNet 等声码器,可以通过合成获得更好的语音质量。相反,不可避免地要避免由于额外的计算而带来的复杂性问题。
然而,为了避免额外的前/后处理,如 MFB 和声码器,我们提出了一种快速有效的方法,以并行方式使用原始频谱转换逼真的声音,以生成具有清晰发音的不同风格的声音。在本文中,我们介绍了一种使用 Transformer 网络的无声码器端到端语音转换方法。我们专注于转换由 STFT 获得的原始频谱,而无需借助需要迭代合成的声码器。此外,还可以利用相位信息通过逆 STFT 还原波形语音。
我们提出的转换模型也可以用于语音识别的说话人适应。 我们的方法可以在不使用 MFB 和声码器的情况下将源语音转换为目标语音。 我们可以通过将转换后的幅度乘以相位来获得用于语音识别的自适应 MFB。 此外,还可以将语音识别性能较差的少数民族(老人、儿童、方言、残疾说话者)的声音转换为普通成年人的声音。 通过说话人自适应替代少数族裔和普通成年人的特征,可以实现更好的语音识别性能。 我们分别使用自然度、相似度和清晰度等指标和平均意见得分 (MOS) 在 TIDIGITS 数据集上执行我们的语音转换实验。
相关工作
在本节中,我们首先介绍我们在本文中使用的声码器、语音转换和transformer网络的先前研究。
Vocoder
声码器用于将线性尺度频谱合成为语音信号,通过相位估计合成自然语音。在 Griffin-Lim 算法中,计算上一步输出的语音信号的 STFT,并将幅度替换为作为输入的修正 STFT 幅度。该算法通过恢复原始信号的迭代过程来恢复STFT幅度与给定的修正STFT最相似的语音信号,以最小化新STFT和输入修正STFT幅度的平方误差。
WaveNet 是一种自回归模型,它使用语音样本之间的顺序特征,并通过使用先前的样本预测下一个样本,成功地合成了高质量的语音。但是,生成速率的速度很慢,因为下一个样本是从前一个样本中一个一个地生成的。 Parallel WaveNet 旨在解决 WaveNet 的样本生成速度慢的问题,它使用逆自回归流来合成语音。由于逆自回归流在学习过程中不知道目标语音数据集的分布,所以通过使用训练有素的WaveNet(教师网络)提取目标数据集的分布信息并与结果进行比较来进行学习逆自回归流。它的优点是语音合成速度比 WaveNet 快,但合成语音的质量较低。与 Parallel WaveNet 不同,WaveGlow 不需要预训练的教师网络,并且具有快速语音合成的优势。但是,由于 WaveGlow 使用基于分布的损失函数,因此合成语音的质量很差。此外,当与 TTS 结合时,会出现合成语音的质量取决于从文本中预测的 MFB 质量的问题。
语音转换
在Parrotron中,将残疾说话者的声音转换为一般声音。编码器由 CNN 和三个 BiLSTM 组成,解码器由两个 LSTM 组成。使用编码器-解码器之间的注意力。为了解决信号到信号的转换问题,语音识别解码器连接到编码器输出以进行多任务学习,并且仅用于训练任务。
要在不同语言的语音之间进行翻译并将翻译后的输出合成为语音,通常必须通过语音识别、翻译和 TTS 任务。然而,在另一篇文章中,他们将不同语言的语音转换为基于端到端注意力的 Seq2Seq 网络。无需经过其他步骤,它可以直接将另一种语言的语音翻译成一种。 Encoder由8个BiLSTMs组成,编码器输出用于通过辅助任务预测输入和目标的音素时间信息。同样,这些辅助解码器仅用于学习。此外,解码器可以根据输入说话人进行任意调整。因此,可以通过使用预先训练的说话人编码器将语音转换为所需说话人的语音。他们考虑使用 WaveRNN 声码器而不是 Griffin-Lim,因为它可以显着提高语音质量。
Transformer
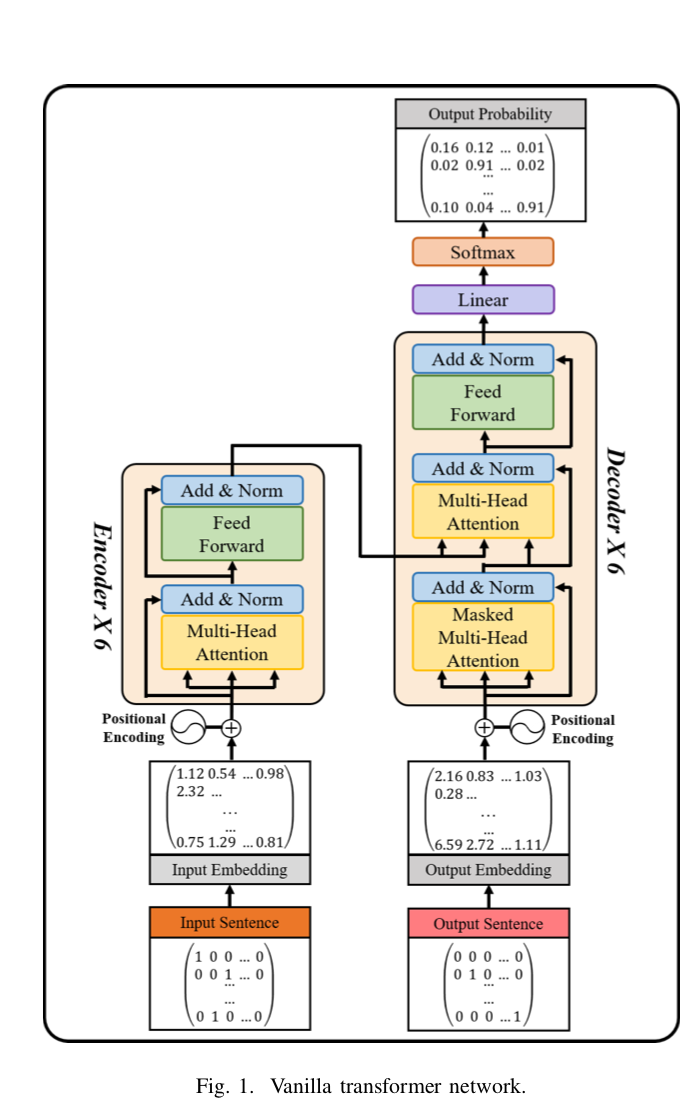
end2end-vc-transformer-fig1
RNN 广泛用于序列建模任务,例如神经翻译和语言建模。然而,由于 RNN 对每个序列一个一个地处理单词,这个顺序过程可能成为并行化和缓慢学习的障碍。最重要的是,如果这些时间信息变长,模型往往会忘记远处位置的内容,以便或与下一个位置的内容混合。 Transformer 网络是一种模型架构,它完全依赖于注意力机制来推导出输入和输出之间的全局依赖关系。如图 1 所示,没有 CNN 和 RNN 的 Transformer 模型架构显示了快速学习时间的优势。传统RNN由于在时间信息上表现不佳的缺点,已经通过self-attention解决了。 BERT是由transformer 演化而来的,不仅用于翻译,还包括句子相关性的总结和预测等许多自然语言处理(NLP)领域。BERT 与NLP 一起被广泛应用于其他领域。 VideoBERT 学习了从向量双向和语音识别导出的视觉和语言标记序列的双向联合分布,并输出视频数据。这导致了对各种任务的研究,包括动作分类和视频字幕。在Transformer-TTS中,将 Transformer 网络与 TTS 模型称为 Tacotron2,用于呈现语音合成的结果。在Transformer-VC中,基于 Transformer 网络执行语音转换,使用预训练的 TTS。他们使用基于声码器的合成使用预先训练的模型参数执行语音转换。
因此,声码器有助于提高语音合成的质量,但合成需要时间。 我们使用Transformer网络是因为它通过自我注意以及快速有效的并行学习技术的泛化性能。 此外,我们通过专注于原始频谱阶段的转换而不采用通过声码器的语音合成方法来执行我们的实验。 更多细节在第 3 节中给出。
本文方法
本节介绍在没有声码器帮助的情况下使用原始频谱而不是 MFB 进行端到端语音转换。
原始频谱
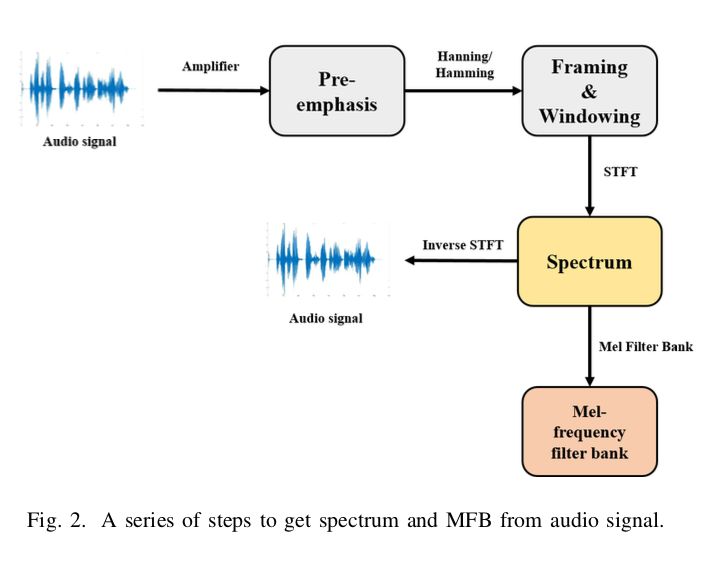
end2end-vc-transformer-fig2
图 2 显示了将波形语音转换为频谱、MFB 并返回波形语音的流程图。 给定一个连续的音频信号 \(x[n]\),这可以表示为:
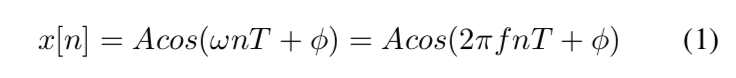
end2end-vc-transformer-al1
其中 \(A\) 是振幅,\(ω\)是径向角频率以radians/seconds为单位, \(f\) 是 \(ω/2π\), \(φ\) 是弧度的初始相位, \(n\) 是时间index, T 是 \(\frac{1}{f_s}\) 。 下一个过程是应用预加重滤波器到\(x\)以放大高频。预加重滤波器有多种用途。 高频一般小于低频。 因此,使用预加重滤波器有助于避免 STFT 期间的数值问题并提高信噪比。
随着信号频率随时间变化,经过预加重后,信号被分成短时间帧。 由于信号的频率轮廓随时间丢失,因此执行傅立叶变换时假设信号的频率在很短的时间内是静止的,而不是在整个信号上。 语音处理的典型帧大小为 20ms 到 40ms,有 50% 的重叠。 通常帧大小使用 25ms,步幅重叠大小使用 10ms(15ms 重叠)。
下一步是将信号切割成帧,并对每一帧应用汉明、汉宁窗函数。 可以通过对每一帧执行 N 点 FFT (NFFT) 来计算频谱。 这里,NFFT一般使用256(16ms)或512(32ms)。 最后,通过 STFT 获得的频谱可以用幅度和相位由以下等式表示:

end2end-vc-transformer-al2
其中 \(D\) 是复值频谱,\(S\) 是幅度,\(P\) 是相位。
总之,原始频谱可以直接从语音波形中恢复,如图 2 所示。因此,我们使用频谱以有效的方式进行语音转换,无需任何后处理。
提出的模型结构
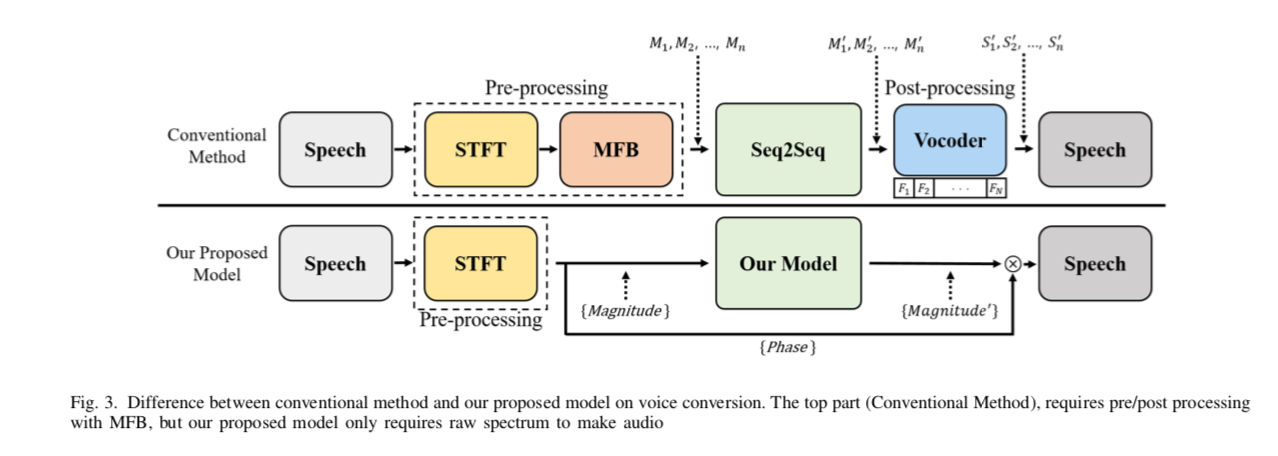
end2end-vc-transformer-fig3
- 模型数据流:第 2 节中提到的声码器复杂且计算量大,需要大量重复工作来恢复音频波形。 为了解决这个问题,我们专注于频谱级别的转换。 图 3 显示了在上半部分使用 MFB 的传统方法,在下半部分显示了本文提出的Transformer网络。 传统方法使用MFB的输出表示为\(M_1,M_2,...,M_n\)作为Seq2Seq的输入,通过声码器获得输出。 Seq2Seq 中的编码器输入考虑了所有时间信息。 它与我们的模型没有什么不同。 然而,解码器一次预测 n 帧 MFB,从而将解码器步骤的数量减少到 \(n/γ\),其中 \(γ\) 是缩减因子。 使用 CBHG(一维卷积组、高速公路网络、双向门控循环单元)模块对线性尺度谱 \(F\) 进行后处理,结果为 \(F_1 , F_2 , ..., F_n\) 。 声码器对于将 \(F\) 转换为表示为 \(S_1^{'} , S_2^{'} , ..., S_n^{'}\) 的波形至关重要。 使用先前输入来预测当前步骤的自回归声码器。 一旦我们得到 \(S_1^{'}\) ,使用 \(S_1^{'}\) 来预测 \(S_2^{'}\) ,最终得到 \(S_n^{'}\) 。 然而,这并不能降低计算成本。
另一方面,在图 3 中提出的模型中,幅度 \(S\) 和相位 \(P\) 是使用等式(2)获得的,来自经过 STFT 后的原始光谱。 然后,我们使用 \(S\) 作为模型编码器的输入。 解码器并行转换频谱。 在模型的最终输出 \(\hat x\) 和输入相位 \(P\) 之间进行元素乘法之后,可以通过逆 STFT 获得转换后的目标语音。 我们可以使用转换后的源幅度和相位立即恢复预测的语音,而无需声码器的帮助。 我们提出的模型是一种以并行方式使用原始频谱转换真实声音的快速有效方法。 我们的方法不依赖于后处理。
- 标记和零填充:语料库的模型输入通常是从词嵌入矩阵中向量化的。 与语料库不同,频谱由连续值组成。 频谱由时间 \(T\) 的 \(N\) 维组成。这些值不是稀疏表示。 语料库设置最大长度,将句首(SOS)放在语料库前面,句末(EOS)放在语料库末尾。
组合序列的 SOS 用作解码器输入。 Seq2Seq 需要通过教师强制使用真实值进行训练。 因此,在推理阶段,解码器的输入仅使用 SOS 令牌。
通过这个,自回归变换器使用波束搜索或贪婪搜索进行预测。 我们将 EOS 令牌放入我们的解码器输入中并执行语音转换。 另外,由于beam search是基于beam depth和softmax,所以我们使用贪心搜索。
我们对所有频谱都使用了零填充。 使用零填充的原因是Transformer网络考虑整个序列并并行学习。 即使语音脚本相同,每个说话者的特征长度也不同。 出于这个原因,我们使用了零填充。
为了避免关注零值和实向量,当每个时间步的维度上有零值时,我们乘以\(-1e-9\)。 零填充将在下一节中描述。
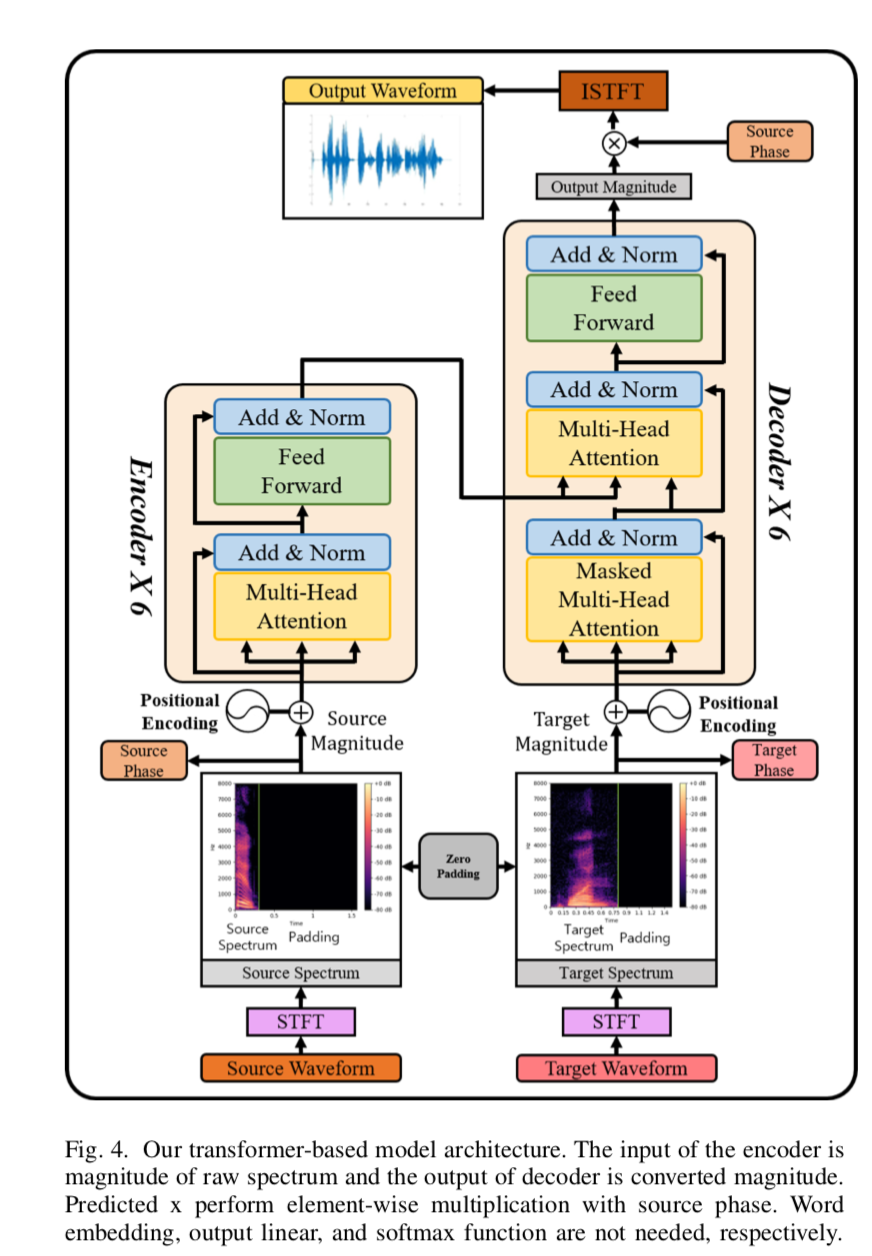
end2end-vc-transformer-fig4
- 基于 Transformer 的模型架构:图 4 显示了我们基于 Transformer 的模型架构。首先,我们获得依赖于 \(NFFT\) 系数的频谱,然后通过等式 (2) 将 \(S\) 和 \(P\) 分开(2)。\(S\) 用作编码器输入。在这种情况下,我们不使用词嵌入,因为 \(S\) 是一个时频域,它由沿时间轴的频率采样组成。最终输入是 \(S\) 加上通过 \(PE\) 的位置向量。然后通过 N$$ 编码器执行多头注意。多头注意力结果通过包含整流线性单元(ReLU)的两层前馈网络来重建未被清理的信息。到目前为止的过程是通过组合每个时间步的整个时间信息来制作新的上下文信息。然后我们执行一个残差连接,将输入数据添加到到目前为止获得的值中。这意味着未包括在输入时间信息中的上下文信息由输入处理并添加。编码器查看整个给定的时间信息,并将每个时间步信息编码为更好的表示。
解码器与编码器方法一样,仅使用从目标 \(y\) 的频谱信号中通过 STFT 的 \(S\),并根据已知信息创建新信息。然而,解码器的不同之处在于它在执行自注意力时使用了掩码多头注意力。使用 masked multi-head attention 的原因是为了通过在 self-attention 的 time step 之后覆盖特征来防止 self-attention。这表明transformer网络是自回归模型。之后,注意力被连接在编码器输出和解码器输出之间。这个过程决定了多少解码器使用输入频谱时间信息的 \(x\) 来表示 \(y_i\)。编码器-解码器注意力的结果被添加到解码器的屏蔽多头注意力结果中。然后将它们放入前馈网络。输出终于出来了。到目前为止,输出 \(\hat x\) 与输入 \(x\) 和目标 \(y\) 具有相同的维度 \(d_{model}\),只是幅度时间长度不同。最后,\(\hat x\) 目前只有从源 \(x\) 转换为目标 \(y\) 的幅度。然后我们将此值乘以 \(P\) 以制作包含复数的频谱。最后,可以使用逆 STFT 将其恢复为波形语音。
结论
我们在原始频谱级别提出了具有自注意力机制的语音变换,而传统方法在 MFB 级别使用声码器。与原始频谱相比,基于 MFB 的方法具有计算学习方便的优势。然而,使用 MFB 方法的语音生成器需要声码器,这需要大量的训练过程计算开销。使用声码器,可以通过合成获得更好的语音质量。相反,由于额外计算而导致的复杂性问题是不可避免的。附加的前/后处理(例如 MFB 和声码器)对于将真实的人类语音转换为其他语音不是必不可少的。在本文中,我们提出了一种无声码器的端到端语音转换方法,该方法使用可以并行转换频谱的快速高效的Transformer网络。在没有重复声码器的帮助下用原始频谱获得转换结果的优点是使用原始相位信息来提供结果。我们收集了 38 名参与者,对转换后的语音的自然度、相似度和清晰度进行了 MOS 评估。在整体说话人平均 MOS 中,我们的实验结果得分分别为自然度 3.40±0.31、相似度 3.82±0.25 和清晰度 3.93±0.25。我们的结果表明,所提出的方法可以在保持自然性和相似性的适当性的同时,以良好的清晰度进行变换。
未来工作
在评估阶段,\(\hat x\) 有一个不自然的转换部分。这似乎是由错位引起的,因为 \(\hat x\) 和 \(phase_x\) 的长度显着偏离。这是转换为最大长度的基于Transformer的模型的一个特征。换句话说,由于零填充,所有数据集的长度都相同。但是,如果\(phase_x\) 的实际向量长度小于\(\hat x\),则会导致严重的错位问题。在上述情况下,恢复波形的质量可能很差。因此,音高被打破,自然度被削弱。因此,我们的模型需要进行相位变换来解决错位问题。该发现出乎意料,表明输入频谱长度存在问题。
我们发现了相位在研究中的重要性。如果 \(phase_x\) 和转换后的 \(\hat x\) 相互对齐,问题就可以解决。为了解决这个问题,我们必须使用复杂的神经网络来对齐原始频谱中包含的幅度和相位。如果可以根据转换后的幅度进行相位对齐,将提高人声的质量。将有可能将语音识别性能较差的少数民族的声音转换为普通成年人的声音。可以通过说话人自适应替代少数民族和普通成年人的特征来实现更好的语音识别性能。我们将研究相位适应和与量级的对齐作为我们的下一个任务。