基于带卷积小波核的 Dual-GAN 实现端到端的 F0 语音转换
摘要
本文提出了一种在表达性语音转换的背景下进行 F0 转换的端到端框架。 提出了一个单一的神经网络,其中第一个模块用于学习不同时间尺度上的 F0 表示,第二个对抗模块用于学习从一种情绪到另一种情绪的转换。 第一个模块由带有小波内核的卷积层组成,因此可以有效地编码 F0 变化的各种时间尺度。 单个分解/转换网络允许以端到端的方式直接从原始 F0 信号中学习对于转换而言最佳的 F0 分解。
Introduction
基频 (F0) 是人类语音交流和人机交互中必不可少的声学特征。 F0作为语音韵律的一个关键特征,在语音交际的各个方面都发挥着重要作用:它传达语言信息(F0有助于阐明话语的句法结构或用于语义强调),情感或社会态度等副语言信息,甚至通过他的说话风格成为说话者身份的一部分。因此,因此,生成式 F0 建模在文本到语音、语音身份转换 (VC) 和表达性语音转换领域非常有用,通过允许直接和参数控制F0 来操纵声音的表现力(例如说话风格或情绪)。从本质上讲,F0 变化发生在不同的时间尺度上,每个尺度都与特定功能相关,从微观变化到宏观轮廓,如强调、情绪和模式。为了涵盖 F0 建模的这些特性,已经提出了风格化方法和多级建模。
值得注意的是,在 VC 中,诸如高斯混合模型 和基于 LSTM 的序列到序列模型等生成模型被用于学习从中性语音到表达性语音的 F0 转换。 最近,各种工作集中在使用连续小波变换 (CWT) 作为 F0 的中间表示,在其上使用生成对抗网络 (GAN) 模型,例如 Dual-GAN、Cycle-GAN、VAW -GAN 或 VA-GAN 被训练来学习转换。 这些模型中的大多数是在并行数据和情感对上学习的,这允许学习话语的两种不同情感版本之间的直接映射,同时保留固定和受控的语言内容。
罗等人提出了一种称为 CWT 自适应尺度(CWT-AS)的有前途的方法。 CWT 在小波核上计算 F0 信号的分解,这允许在不同时间尺度上表示 F0,在表达性语音转换中具有各种应用。 使用 CWT 的 F0 建模最近被指定为可以在任意语言尺度(例如,音素、音节、单词和话语)上计算分解的可能性。 自适应尺度 (AS) 算法被描述为通过选择使 CWT 空间中情绪之间的平均距离最大化的尺度,为每对情绪选择最佳 CWT 表示。
根据这些选定的尺度,计算 F0 轮廓的 CWT 分解。 最后,使用 Dual-GAN 从这些表示中学习每对情感之间的转换函数。 尽管这种方法看起来很有前景,但它有两个主要局限性:1)尺度选择仅基于情绪之间距离的最大化,而忽略了它们对 F0 信号的重建能力。 这可能会导致 F0 重建不佳,进而降低转换的质量和自然度; 2)F0信号的CWT-AS分解和dual-GAN是独立优化的,这构成了训练的瓶颈。 因此,就双 GAN 目标而言,CWT 分解可能不是最佳的。
为了克服这些限制,我们提出了一种端到端架构来有效地学习情绪之间的 F0 转换。 所提出的神经架构将 F0 分解和双 GAN 结合到一个网络中,从而在双 GAN 目标意义上优化 CWT 分解,并结合所得分解的分离和重建损失。 对社会态度语音转换的应用表明,与 CWT-AS 方法相比,所提出的方法显着提高了转换的质量。
提案方法
在本节中,我们将介绍我们基于 CWT-AS 的提案,并通过在转换学习过程之上集成 F0 风格化部分来展示它的不同之处,我们将其称为语音 f0 转换的端到端方法 Ⅱ-A。 我们的贡献的概念和技术细节在 II-B 和 II-C 中给出。
框架概述
由于我们提出的 VC 系统需要并行数据,因此考虑了分别与表达性 \(a\) 和 \(b\) 相关的话语集 \(X_a\) 和 \(X_b\)。 然后对一对话语进行采样并提取 \(F_0\) 序列,源 \(x_a\) 和目标 \(x_b\)。 除了表达性之外,一对中的每个话语都具有相同的内容(语言内容、说话者身份)。 源和目标 \(F_0\) 被赋予我们称为 Wevelet 小波核卷积编码器 (WKCE)。 一个分类器,表示为 C,其目标是预测表达能力,由 WKCE 输出提供。 如图 1 所示,这两个模块必须被视为 Dual-GAN (DG) 的预网络 (\(pN\)),可以进行预训练,也可以与 Dual-GAN 一起训练形成端到端系统 用于 f0 转换。
小波核卷积自编码器
作为一种多尺度建模方法,CWT 在尝试表示长期和短期依赖性时完全适合,韵律受其影响。 由于 CWT 只能应用于连续函数,因此需要在浊音 F0 段之间进行简单的线性插值以获得与短语相关的连续 F0 函数,然后可以在向量 \(x ∈ [0, 1]^T\) 中对其进行采样。
我们的 WKCE 基于为时间向量 \(t ∈ R^T\) 定义的母小波 \(ψ_s ∈ R^T\) 在 F0 信号 \(x\) 和小波核之间执行卷积
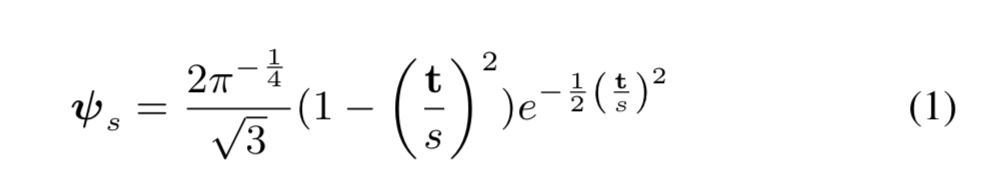
f0-vc-al1
考虑到小波内核依赖于控制组成内核的每个小波的宽度的 \(N\) 个可学习参数 \(s\),时间级别 \(s\) 对 F0 信号 \(x\)的贡献 \(h^s_x\) 是 \(x\) 和 \(ψ_s\) 之间的卷积。 因此,输入 \(x\),我们的 WKCE 模块将输出 \(W_e (x) = [h^{s_0}_x,...,h^{s_N}_x ] ∈ R^{N×T}\)。 如果我们将 \(W_r\) 表示为重建操作,则重建信号 \(\hat x\) 由下式给出
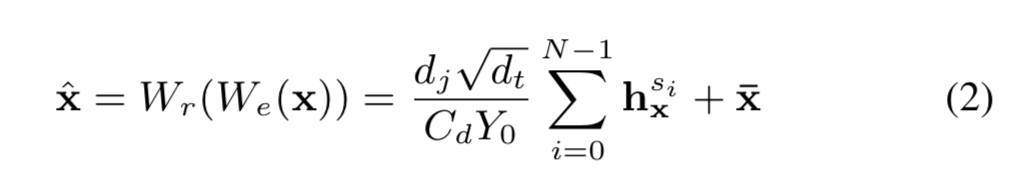
f0-vc-al2
\(x ̄\) 是 \(x\) 的平均值,\(d_t = 1.2\),\(d_j = 0.125\),\(C_d = 3.541\) 和 \(Y_0 = 0.867\)(详情参见 [17])
如果我们表示 \(E\),数学期望并考虑分别从源分布和目标分布 \(P (x^a )\) 和 \(P (x^b )\) 采样的 \(x^a\) 和 \(x^b\),则可以针对 L1 损失训练该模块以实现重建目标,公式如下
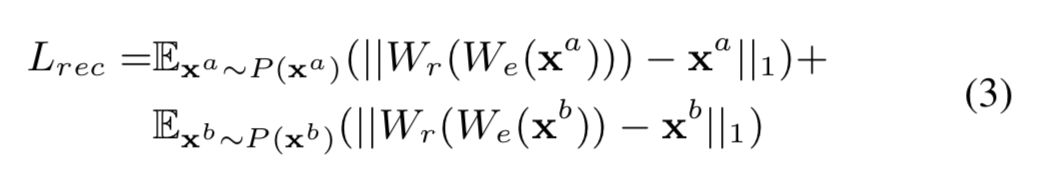
f0-vc-al3
可以添加对 CWTs 潜在空间的分类约束,\(W_e\) 和 \(C\) 是针对 \(L_{cl}\)、预测源表达性 \(\hat a = C(W_e(x^a))\) 和真实值 \(a\) 之间的交叉熵 (CE) 损失进行训练的 与 \(\hat b\) 和 \(b\) 之间的 CE 相加。
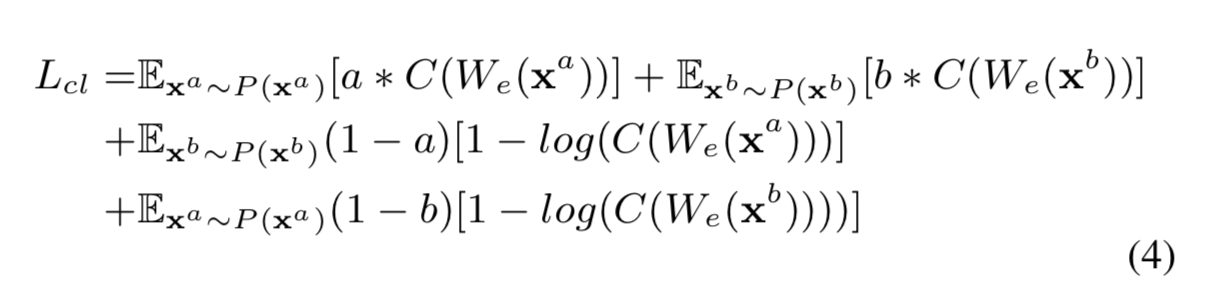
f0-vc-al4
模型
在本文中,我们专注于称为 Dual-GAN 的特定 GAN 网络,它能够学习并行数据对之间的映射。该网络基于两个概念:1)对抗性学习,即训练生成模型在两个神经网络(称为生成器 G 和判别器 D)之间的最小-最大博弈中找到解决方案。2)双重监督学习即同时训练两个双重任务的模型,利用它们之间的概率相关性来规范训练过程。结合这些突破,可以利用 GAN 产生现实转换的能力以及由于双重监督学习带来的显着改进。
这第二点意味着正向和逆向变换,分别是 \(G_{a→b} : (W_e(x^a), z^a) → x^b\) 和 \(G_{b→a} : (W_e(x^b, z^b) → x^a\), 是联合学习的,其中 \(z^a\) 和 \(z^b\) 是在 \(G_a\) 和 \(G_b\) 的每一层以 dropout 形式提供的随机独立噪声。需要第一个损失 \(L_{a↔b}\) 来训练 \(G_{a→b}\)、\(G_{b→a}\) 和 \(W_e\)。
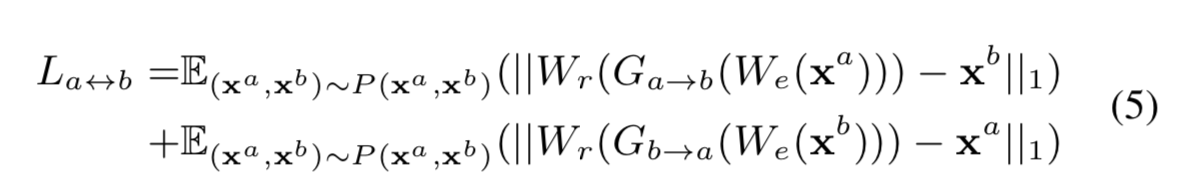
f0-vc-al5
同时,\(D_a\) 区分 \(G_{a→b}\) 的转换输出 \(\hat X^b\) 和域 \(X_b\) 的真实样本,\(D_b\) 类似地完成对抗机制。 训练 \(G_{a→b}\)、\(G_{b→a}\)、\(D_a\)、\(D_b\) 和 \(W_e\) 需要对抗性损失 \(L_{ADV}\)
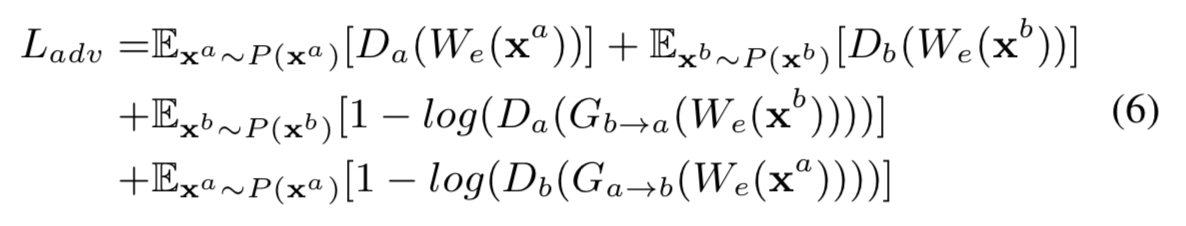
f0-vc-al6
添加了第三个约束,称为 Dual loss,以加强 \(G_{a→b}\) 和 \(G_{b→a}\)之间的内在联系,可以理解为过程的正则化。
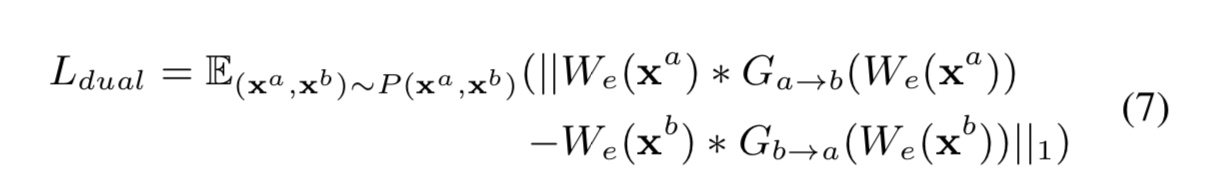
f0-vc-al7
因此,可以为 pre-Net 预训练和适当的 Dual-GAN 训练制定两个最终损失,分别是 \(L_{pN}\) 和 \(L_{DG}\),分别具有 \(α\)、\(β\)、\(λ\) 和 \(γ\) 加权重建、分类、转换和双重目标。
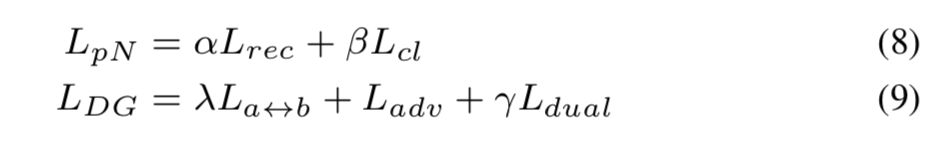
f0-vc-al8
结论
在本文中,我们提出了一种在表达性语音转换的上下文中进行 F0 转换的端到端框架,将不同时间级别的 F0 分解及其在单个网络中的转换结合在一起。 客观和主观评估都表明我们的方法可以实现比基线更好的性能。 我们旨在推广多说话人 F0 转换,并通过构建表达性嵌入来避免配对学习。