对抗性学习分离的语音表示,用于稳健的多因素语音转换
摘要
将语音分解为解开的语音表示对于在语音转换 (VC) 中实现高度可控的风格转换至关重要。 VC中传统的语音表征学习方法仅将语音分解为说话者和内容,对其他与韵律相关的因素缺乏可控性。针对更多语音因素的最先进的语音表示学习方法正在使用主要的解缠结算法,例如随机重采样(random resampling)和临时瓶颈层大小调整,但是很难确保稳健的语音表示解缠结。为了提高 VC 中多因素高度可控风格迁移的鲁棒性,我们提出了一种基于对抗性学习的解开语音表示学习框架。提取表征内容、音色、节奏和音高的四种语音表示,并通过受 BERT 启发的对抗网络进一步解开。对抗网络用于通过从其他表示中随机屏蔽和预测一个表示来最小化语音表示之间的相关性。还采用单词预测网络来学习更多信息的内容表示。实验结果表明,与最先进的方法相比,所提出的语音表示学习框架通过将转换率从 48.2% 提高到 57.1% 和 ABX 偏好超过 31.2%,显着提高了 VC 在多个因素上的鲁棒性。
Introduction
语音转换 (VC) 旨在将源说话者的输入语音转换为目标说话者所说的声音,而不改变语言内容 。 除了音色的转换外,还可以在韵律、音高、节奏或其他非语言领域等各种领域进行转换。 针对这些语音因素的表征学习方法已经被提出并应用于语音处理的许多研究领域。但是,将这些方法提取的语音表征直接应用到 VC 中 可能会导致其他语音因素的意外转换,因为它们可能不一定是正交的。 因此,解开语音信号中各种信息因素混合的表示对于实现高度可控的 VC 至关重要。
传统上,只有说话人和内容信息在 VC 中被分解。由编码器和解码器组成的自动编码器被提出并广泛用于 VC 。在训练期间,解码器从说话者和从编码器或其他预训练提取器提取的内容表示中重建语音。基于变分自编码器的方法将内容信息的潜在空间建模为高斯分布以追求正则化特性。进一步提出了基于矢量量化的方法,将内容信息建模为与语音信息分布更相关的离散分布。采用辅助对抗说话人分类器,通过最小化表示之间的互信息,鼓励编码器从内容信息中丢弃说话人信息。
为了克服在传统 VC 中替换说话人表示时韵律也被转换的情况,应用不同的信息瓶颈将说话人信息分解为音色和其他韵律相关因素,如节奏和音高。为了改善解纠缠,瓶颈层的受限尺寸鼓励编码器丢弃可以从其他瓶颈中学习的信息。还建议在信息瓶颈中使用随机重采样以从内容和音高表示中去除节奏信息。
然而,如果没有明确的解缠建模,随机重采样和限制瓶颈层的大小只能获得有限的语音表示解缠。 随机重采样通常被实现为使用时间维度上的线性插值分割和重采样语音段,只能用于去除与时间相关的信息,例如节奏。 此外,随机重采样被证明是一种部分解缠结算法,它只能污染节奏信息的随机部分。 此外,瓶颈层的大小需要仔细设计,以提取临时且可能不适合其他数据集的解开语音表示。 而内容编码器实际上是一个残差编码器,不能保证内容信息只在内容表示中建模。
在本文中,为了实现多因素 VC 的鲁棒性和高度可控的风格迁移,我们提出了一种基于对抗性学习的解开语音表示学习框架。 所提出的框架通过受 BERT 启发的对抗性网络明确地消除了表征不同语音因素的语音表示之间的相关性。 语音首先被分解为四个语音表示,分别代表内容、音色和另外两个与韵律相关的因素,节奏和音高。在训练期间,对抗性掩码和预测 (MAP: mask-and-predict) 网络将随机掩蔽其中一个语音表示并从其余表示中推断出来。 MAP 网络被训练以最大化掩码和剩余表示之间的相关性,而语音表示编码器被训练以通过采用 MAP 网络的反向梯度来最小化相关性。通过这种方式,表示学习框架以对抗方式进行训练,语音表示编码器试图解开表示,而 MAP 网络试图最大化表示相关性。单词预测网络用于从内容表示中预测单词存在向量,内容表示指示每个词汇是否存在于参考语音中。解码器在训练期间根据表示重构语音,并通过替换相应的语音表示在多个因素上实现 VC。
实验结果表明,所提出的语音表示学习框架显着提高了 VC 在多个因素上的鲁棒性,与最先进的语音表示学习相比,转换率从 48.2% 提高到 57.1%,ABX 偏好超过 31.2% 多因素的方法。 此外,所提出的框架还避免了用于复杂瓶颈调整的费力手动工作。
Methodology
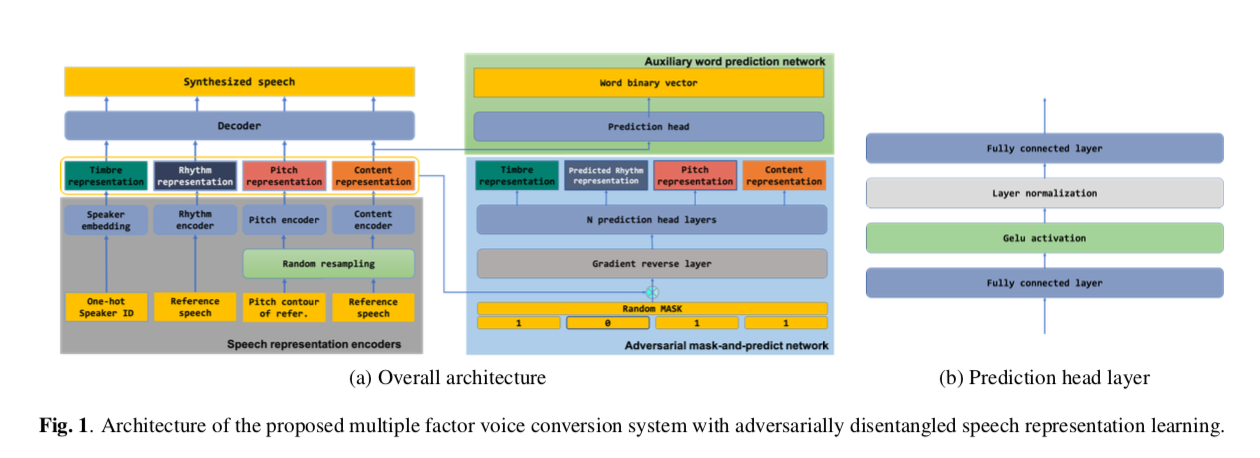
我们提出的解开语音表示学习框架,如图 1 所示,由三个子网络组成:(i)(multiple speech representation encoders) 多个语音表示编码器,将语音编码为不同的语音表示,表征内容、音色、节奏和音调,(ii) (Adversial mask-and-predict network) 一个对抗性 MAP 网络,它被训练来基于掩码和预测操作 (mask-and-predict) 来捕获不同语音表示之间的相关性,(iii) (Auxilliary word prediction network)一个辅助词预测网络,它预测一个二进制词存在向量,指示内容表示是否包含相应的词汇的话。 最后,使用解码器从这些解开的语音表示中合成语音。
2.1 语音表示学习
SpeechFlow 中的三个编码器经过微调,可以从帧级的参考语音中提取节奏、音调和内容表示。 One-hot 说话者标签(ID)嵌入在话语级别并用作音色表示。
2.2 语音表示解纠缠的对抗学习
受 BERT 启发的对抗性 MAP 网络旨在明确解开提取的语音表示。 在训练期间,这四种语音表示中的一种被随机屏蔽,对抗网络从其他表示中推断出屏蔽后的表示。 对抗网络由梯度反向层 和一堆预测头层 组成,它们也已用于掩蔽声学建模。 每个预测头层由一个全连接层、GeLU 激活层、层归一化 和另一个全连接层组成,如图 1(b) 所示。 在反向传播到语音表示编码器之前,对抗网络的梯度被梯度反转层 [20] 反转。 这里采用 L1 损失来衡量以下等式中展示的对抗性损失:
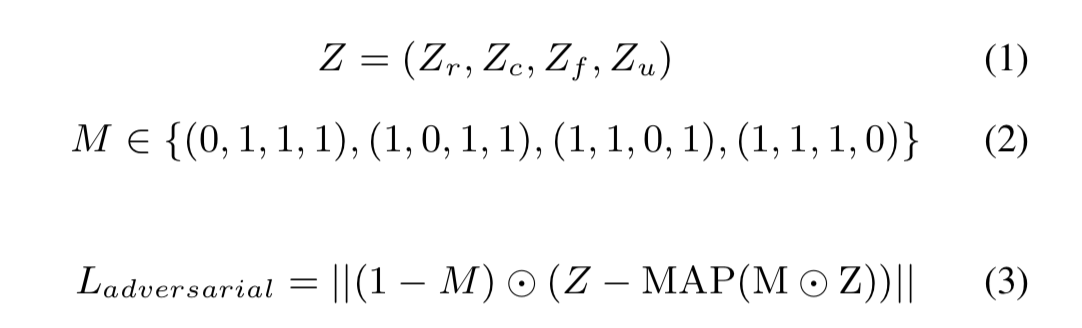
其中 $⊙$ 是逐元素乘积运算,$L_{adversarial}$ 是对抗性损失,$Z$ 是 $Z_r$、$Z_c$、$Z_f$、$Z_u$ 的串联,分别表示节奏、内容、音高和音色表示,M 是随机选择的对应于丢弃的二进制掩码 在表示被丢弃的地方值为 0 的区域,对于未屏蔽的表示,值为 1。
MAP 网络被训练为通过最小化对抗性损失来尽可能准确地预测掩码表示,而在反向传播中,梯度是反向的,这鼓励编码器学习的表示包含尽可能少的互信息。
2.3 辅助词预测网络
为了避免内容信息被编码到其他表示中,我们设计了一个辅助词预测网络来从内容表示中预测每个词汇表的存在。 词预测网络是一堆预测头层,它产生一个二进制的 词汇表尺寸 向量,其中每个维度表示该句子中是否存在相应的词汇词。 词存在向量表示为 $V_{word} =[v_1,v_2,…,v_n]$ 其中 $v_i = 1$ 如果词 $i $在语音中,否则 $v_i = 0$。这里应用交叉熵损失以强制内容预测尽可能准确:
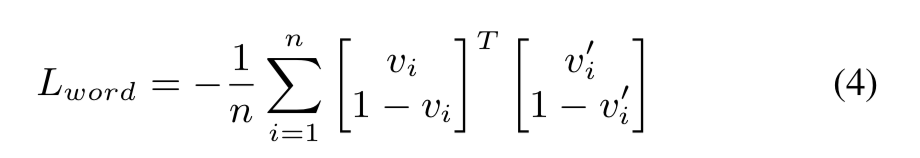
其中 $v_i^{‘}$ 是预测的单词存在指示符,$n$ 是词汇量的大小。 $v_i^{‘} = 1$ 如果单词 $i $被预测存在,否则 $v_i^{‘} = 0$。它旨在确保内容表示更具信息性并避免内容信息泄漏到其他表示中。 在语音转换和文本到语音系统中使用了类似的内容保留策略,这被证明是有效的并且可以提高性能。
2.4. 具有解纠缠语音表示的 VC
SpeechFlow 中的解码器用于从解开的语音表示中生成梅尔谱图。 在训练期间,从相同的话语中提取四个语音表示,并训练解码器从语音表示重建梅尔谱图,损失函数定义为以下等式:
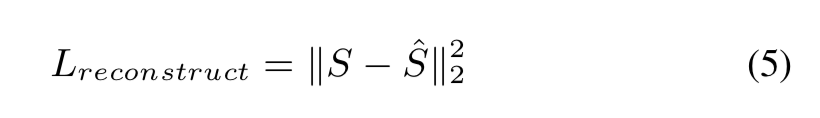
其中 $S$ 和 $\hat S$ 分别是输入和重建语音的梅尔谱图。 整个模型使用定义为以下等式的损失进行训练:
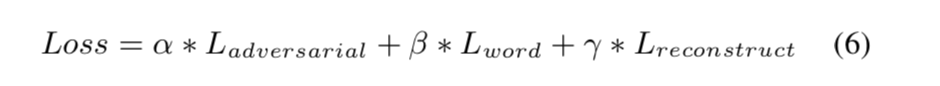
其中$α$、$β$、$γ$分别是对抗性损失、词预测损失和重建损失的损失权重。 为了提高我们提出的框架的鲁棒性,重建损失的损失权重被设计为指数衰减。
结论
为了提高 VC 中多因素高度可控风格迁移的鲁棒性,我们提出了一种基于对抗性学习的解开语音表示学习框架。 我们提取了四种表征内容、音色、节奏和音调的语音表示,我们采用了一个受 BERT 启发的对抗网络来进一步解开语音表示。 我们使用单词预测网络来学习更多信息的内容表示。 实验结果表明,所提出的语音表示学习框架显着提高了 VC 在多个因素上的鲁棒性。 在未来的工作中将探索不同的掩蔽策略。