Wav2vec 无监督语音识别预训练
摘要
我们通过学习原始音频的表示来探索无监督的语音识别预训练。 wav2vec 在大量未标记的音频数据上进行训练,然后使用得到的表示来改进声学模型训练。 我们预训练了一个简单的多层卷积神经网络,该网络通过噪声对比二元分类任务进行了优化。 当只有几个小时的转录数据可用时,我们在 WSJ 上的实验将基于强字符的 log-mel 滤波器组基线的 WER 降低了 32%。 我们的方法在 nov92 测试集上实现了 2.78% 的 WER。 这优于 Deep Speech 2,这是文献中报道最好的基于字符的系统,同时使用的标记训练数据少了三个数量级。
Introduction
当前最先进的语音识别模型需要大量转录的音频数据才能获得良好的性能。 最近,神经网络的预训练已成为标记数据稀缺的设置的有效技术。关键思想是在有大量标记或未标记数据可用的设置中学习一般表示,并利用学习到的表示来提高数据量有限的下游任务的性能。这对于需要大量努力来获取标记数据的任务尤其有趣,例如语音识别。
在计算机视觉中,ImageNet (Deng et al., 2009) 和 COCO (Lin et al., 2014) 的表征已被证明可用于初始化诸如图像字幕 (Vinyals et al., 2016) 或姿态估计等任务的模型(帕夫洛等人,2019 年)。计算机视觉的无监督预训练也显示出前景(Doersch 等,2015)。在自然语言处理 (NLP) 中,语言模型的无监督预训练(Devlin 等人,2018 年;Radford 等人,2018 年;Baevski 等人,2019 年)改进了许多任务,例如文本分类、短语结构解析和机器学习翻译(Edunov 等人,2019 年;Lample & Conneau,2019 年)。在语音处理中,预训练侧重于情绪识别(Lian 等人,2018 年)、说话人识别(Ravanelli 和 Bengio,2018 年)、音素辨别(Synnaeve 和 Dupoux,2016a;van den Oord 等人,2018 年) ) 以及将 ASR 表示从一种语言转移到另一种语言 (Kunze et al., 2017)。已经有针对语音的无监督学习的工作,但结果表示尚未应用于改进有监督的语音识别(Synnaeve & Dupoux,2016b;Kamper 等,2017;Chung 等,2018;Chen 等,2018; Chorowski 等人,2019 年)。
在本文中,我们应用无监督预训练来改进有监督的语音识别。这使得能够利用比标记数据更容易收集的未标记音频数据。我们的模型 wav2vec 是一个卷积神经网络,它将原始音频作为输入并计算可以输入到语音识别系统的一般表示。目标是一个对比损失,需要将真实的未来音频样本与负样本区分开来(Collobert 等人,2011;Mikolov 等人,2013;van den Oord 等人,2018)。与之前的工作(van den Oord 等人,2018 年)不同,我们超越了逐帧音素分类,并将学习到的表示应用于改进强监督 ASR 系统。 wav2vec 依赖于完全卷积的架构,与之前工作中使用的循环自回归模型相比,该架构可以随着时间的推移在现代硬件上轻松并行化(第 2 节)。
我们在 WSJ 基准测试中的实验结果表明,基于大约 1,000 小时未标记语音的预训练表示可以显着改善基于字符的 ASR 系统,并优于文献 Deep Speech 2 中基于字符的最佳结果。 TIMIT 任务,预训练使我们能够匹配文献中报告的最佳结果。 在仅具有 8 小时转录音频数据的模拟低资源设置中,与仅依赖标记数据的基线模型(§3 和 §4)相比,wav2vec 将 WER 降低了 32%。
预训练方法
给定一个音频信号作为输入,我们优化我们的模型(第 2.1 节)以从给定的信号上下文中预测未来的样本。 这些方法的一个常见问题是需要对数据分布 $p(x)$ 进行准确建模,这具有挑战性。 我们通过首先将原始语音样本 $x$ 编码为较低时间频率的特征表示 $z$ 然后隐式建模类似于 van den Oord 等人的密度函数 $p(z_{i+k} |z_i . . . z_{i-r} )$ 来避免这个问题。
2.1 Model
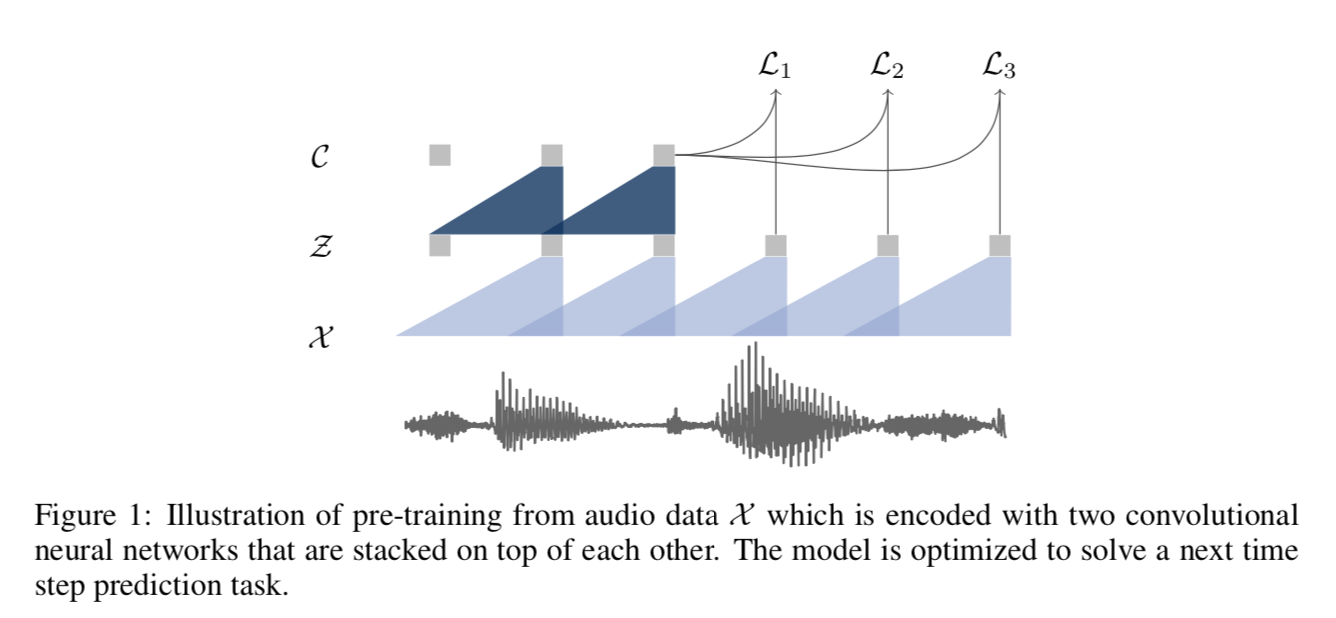
我们的模型将原始音频信号作为输入,然后应用两个网络。编码器网络将音频信号嵌入到潜在空间中,上下文网络结合编码器的多个时间步长来获得上下文化表示(图 1)。然后使用两个网络来计算目标函数(第 2.2 节)。
给定原始音频样本 $x_i ∈ X$,我们应用编码器网络 $f : X → Z$,我们将其参数化为类似于 van den Oord 等人的五层卷积网络。 或者,可以使用其他架构,例如 Zeghidour 等人的可训练前端等。编码器层具有内核大小 (5, 4, 2, 2, 2) 和步幅 (10, 8, 4, 4, 4)。编码器的输出是一个低频特征表示 $z_i ∈ Z$,它对 $16KHz$ 音频的大约 $30ms$ 进行编码,并且跨步导致每 $10ms$ 表示一次 $z_i$。
接下来,我们将上下文网络 $g : Z → C$ 应用于编码器网络的输出,以混合多个潜在表示 $z_i . . . z_{i-v}$ 转换为单个上下文化张量 $c_i = g(z_i . . z_{i-v} )$ 以获得大小为 $v$的感受野。上下文网络有七层,每层内核大小为 3,步幅为 1。上下文网络的总感受野约为 180ms。
两个网络的层都由一个具有 512 个通道的因果卷积、一个组归一化层和一个 ReLU 非线性组成。我们对每个样本的特征和时间维度进行归一化,这相当于使用单个归一化组进行组归一化 。我们发现选择对输入数据的缩放和偏移不变的归一化方案很重要。这种选择导致表示可以很好地跨数据集泛化。
2.2 目标函数
我们训练模型,通过最小化每个步骤 k = 1,…,K 的对比损失,将未来 k 步的样本 zi+k 与从提议分布 pn 中抽取的干扰样本 ̃z 区分开来:
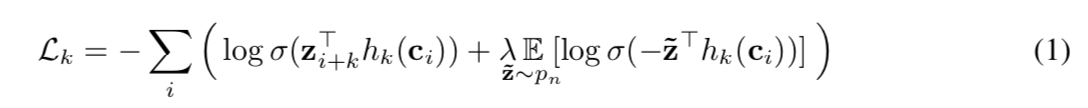
其中我们表示 $sigmoid σ(x) = 1/(1+exp(−x))$,其中 $σ(z^⊤_{i+k}h_k(c_i))$ 是 zi+k 是真实样本的概率。 我们考虑对每个步骤 $k$ 进行特定于步骤的仿射变换 $h_k(c_i) = W_kc_i+b_k$,这适用于 $c_i$(van den Oord 等人,2018 年)。 我们优化损失 $L = \sum^K_{k=1} L_k$,对不同步长求和 (1)。 在实践中,我们通过从每个音频序列中统一选择干扰项(即 $p_n(z) = \frac{1} {T}$,其中 $T$ 是序列长度,我们将 $λ$设置为负数的数量),通过对 10 个负样本进行采样来近似期望值。
训练后,我们将上下文网络 $c_i$ 产生的表示输入到声学模型中而不是 log-mel 滤波器组功能。
实验设置
3.1 数据
我们考虑以下语料库:对于 TIMIT (Garofolo et al., 1993) 上的音素识别,我们使用标准的训练、开发和测试分割,其中训练数据包含三个多小时的音频数据。 华尔街日报 (WSJ; Woodland et al., 1994) 包含大约 81 小时的转录音频数据。 我们在 si284 上训练,在 nov93dev 上验证并在 nov92 上测试。 Librispeech (Panayotov et al., 2015) 包含总共 960 小时的干净和嘈杂的训练语音。 对于预训练,我们使用 WSJ 语料库的完整 81 小时、干净的 Librispeech 的 80 小时子集、完整的 960 小时 Librispeech 训练集,或所有这些的组合。
为了训练基线声学模型,我们为步长为 10 毫秒的 25 毫秒滑动窗口计算了 80 个对数梅尔滤波器组系数。 最终模型根据单词错误率 (WER) 和字母错误率 (LER) 进行评估。
3.2 声学模型
我们使用 wav2letter++ 工具包来训练和评估声学模型(Pratap 等人,2018 年)。对于 TIMIT 任务,我们遵循 Zeghidour 等人的基于字符的 wav2letter++ 设置。 (2018a) 使用七个连续的卷积块(内核大小为 5,具有 1,000 个通道),然后是 PReLU 非线性和 0.7 的丢失率。最终表示被投影到 39 维音素概率。该模型使用自动分割标准 (ASG; Collobert et al., 2016)) 使用动量 SGD 进行训练。
我们 WSJ 基准的基线是 Collobert 等人中描述的 wav2letter++ 设置。 (2019) 这是一个带有门控卷积的 17 层模型 (Dauphin et al., 2017)。该模型预测了 31 个字素的概率,包括标准英文字母、撇号和句点、两个重复字符(例如,单词 ann 被转录为 an1)以及用作单词边界的静音标记 (|)。
所有声学模型都使用 fairseq 和 wav2letter++ 的分布式训练实现在 8 个 NVIDIA V100 GPU 上进行训练。在 WSJ 上训练声学模型时,我们使用学习率为 5.6 的普通 SGD 以及梯度剪裁(Collobert 等人,2019 年)并训练 1,000 个时期,总批次大小为 64 个音频序列。在使用 4-gram 语言模型评估检查点后,我们使用提前停止并根据验证 WER 选择模型。对于 TIMIT,我们使用 0.12 的学习率、0.9 的动量并在 8 个 GPU 上训练 1000 个时期,批量大小为 16 个音频序列。
3.3 解码
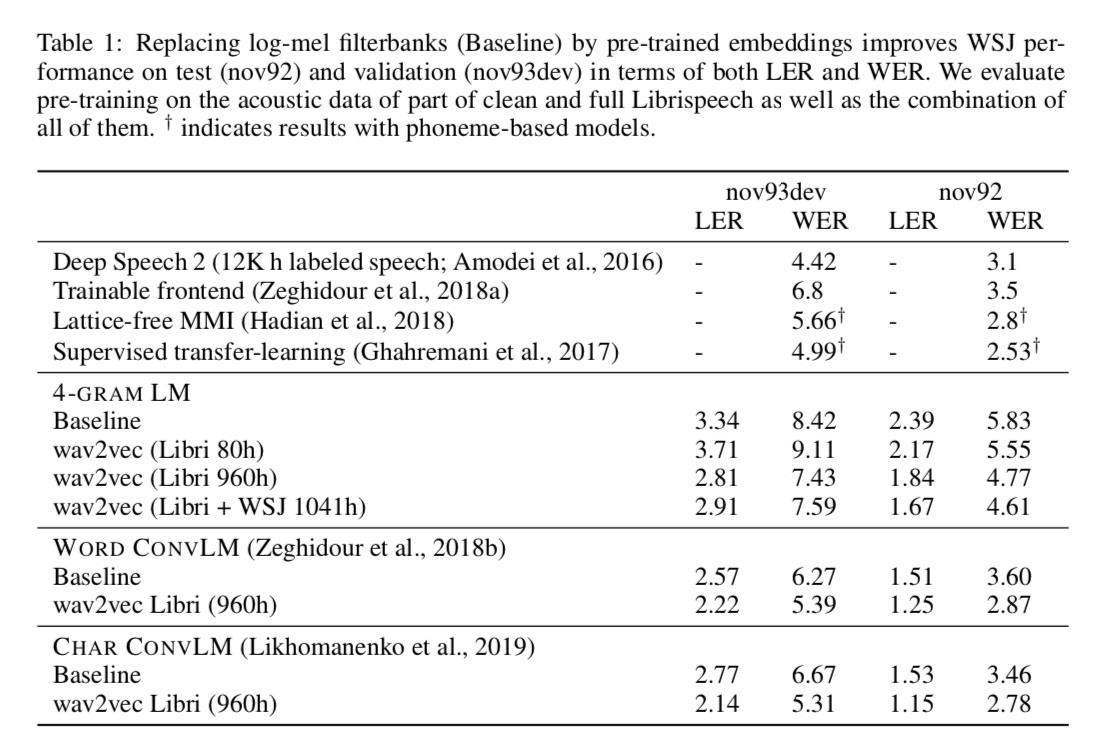
为了解码来自声学模型的输出,我们使用词典以及仅在 WSJ 语言建模数据上训练的单独语言模型。 我们考虑了一个 4-gram KenLM 语言模型(Heafield et al., 2013)、一个基于词的卷积语言模型(Collobert et al., 2019)和一个基于字符的卷积语言模型(Likhomanenko et al., 2019)。 我们使用 Collobert 等人的波束搜索解码器从上下文网络 c 或 log-mel 滤波器组的输出中解码单词序列 y,通过最大化
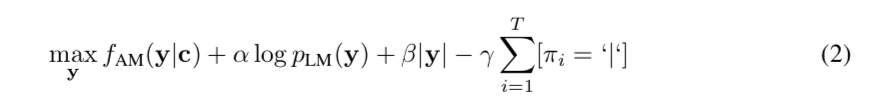
其中 $f_{AM}$ 是声学模型,$p_{LM}$ 是语言模型,$π = π_1, …, π_L$ 是 $y $的字符。 超参数 $α$、$β$ 和 $γ$ 是语言模型、词惩罚和沉默惩罚的权重。
为了解码 WSJ,我们使用随机搜索调整超参数 $α$、$β$ 和 $γ$。 最后,我们使用 $α$、$β$ 和 $γ$ 的最佳参数设置以及 4000 的波束大小和 250 的波束分数阈值来解码来自声学模型的发射。
3.4 预训练模型
预训练模型在 Fairseq 工具包 Ott 等人的 PyTorch 中实现。 我们使用 Adam Kingma & Ba (2015) 和余弦学习率计划 Loshchilov & Hutter (2016) 对它们进行了优化,该计划对 WSJ 和干净的 Librispeech 训练数据集进行了超过 40K 的更新步骤。我们从 1e-7 的学习率开始,逐渐将其预热 500 次更新至 0.005,然后按照余弦曲线将其衰减至 1e-6。我们为完整的 Librispeech 训练 400K 步。为了计算目标,我们对 10 个负样本进行抽样,并使用 K = 12 个任务。
我们在 8 个 GPU 上进行训练,并在每个 GPU 上放置可变数量的音频序列,每个 GPU 的预定义限制为 1.5M 帧。序列按长度分组,我们将它们裁剪为每个最大 150K 帧,或批次中最短序列的长度,以较小者为准。裁剪从序列的开头或结尾删除语音信号,我们随机决定每个样本的裁剪偏移量;我们重新采样每个时期。这是数据增强的一种形式,但也确保了 GPU 上所有序列的长度相等,并平均删除了 25% 的训练数据。裁剪后,GPU 的总有效批量大小约为 556 秒的语音信号(对于可变数量的音频序列)。
结果
与 van den Oord 等人不同。 (2018),我们直接在下游语音识别任务上评估预训练的表示。 我们在 WSJ 基准上测量语音识别性能并模拟各种低资源设置(第 4.1 节)。 我们还评估了 TIMIT 音素识别任务(第 4.2 节)并消除了各种建模选择(第 4.3 节)。
4.1 WSJ基准的预训练
我们考虑对 WSJ 的音频数据(无标签)、干净的 Librispeech 的一部分(大约 80 小时)和完整的 Librispeech 以及所有数据集的组合(§3.1)进行预训练。对于预训练实验,我们将上下文网络的输出提供给声学模型,而不是 log-mel 滤波器组特征。
表 1 显示,对更多数据进行预训练可以提高 WSJ 基准的准确性。预训练的表示可以大大提高我们基于字符的基线的性能,该基线是在 log-mel 滤波器组特征上训练的。这表明对未标记音频数据进行预训练可以比基于字符的最佳方法 Deep Speech 2(Amodei 等人,2016 年)在 11 月 92 日提高 0.3 WER。我们最好的预训练模型的性能与 Hadian 等人的基于音素的模型一样好。 (2018)。 Ghahremani 等人 (2017) 是一种基于音素的方法,它对转录的 Libirspeech 数据进行预训练,然后在 WSJ 上进行微调。相比之下,我们的方法只需要未标记的音频数据和 Ghahremani 等人 (2017) 还依赖于比我们的设置更强大的基线模型。
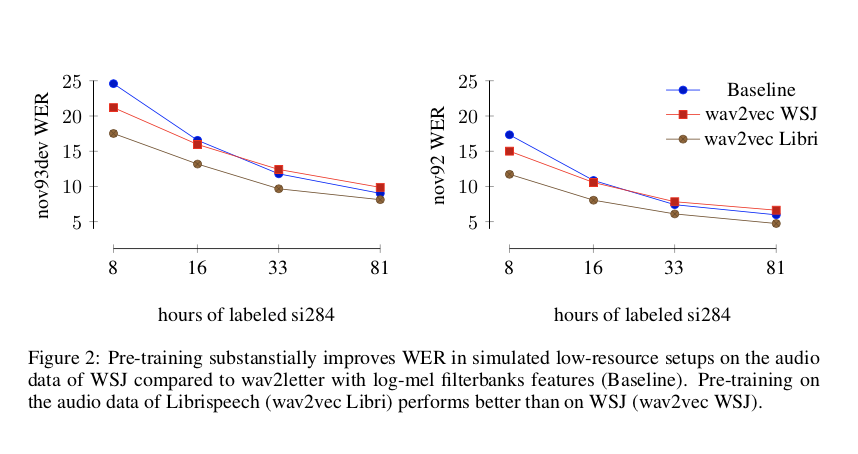
具有较少转录数据的预训练表示有什么影响?为了更好地理解这一点,我们使用不同数量的标记训练数据训练声学模型,并在使用和不使用预训练表示(对数梅尔滤波器组)的情况下测量准确性。预训练的表示在完整的 Librispeech 语料库上进行训练,我们在使用 4-gram 语言模型解码时根据 WER 测量准确性。图 2 显示,当只有大约 8 小时的转录数据可用时,预训练将 nov93dev 上的 WER 降低了 32%。与更大的 Librispeech (wav2vec Libri) 相比,仅对 WSJ (wav2vec WSJ) 的音频数据进行预训练的性能更差。这进一步证实了对更多数据进行预训练对于获得良好性能至关重要。
4.2 TIMIT预训练
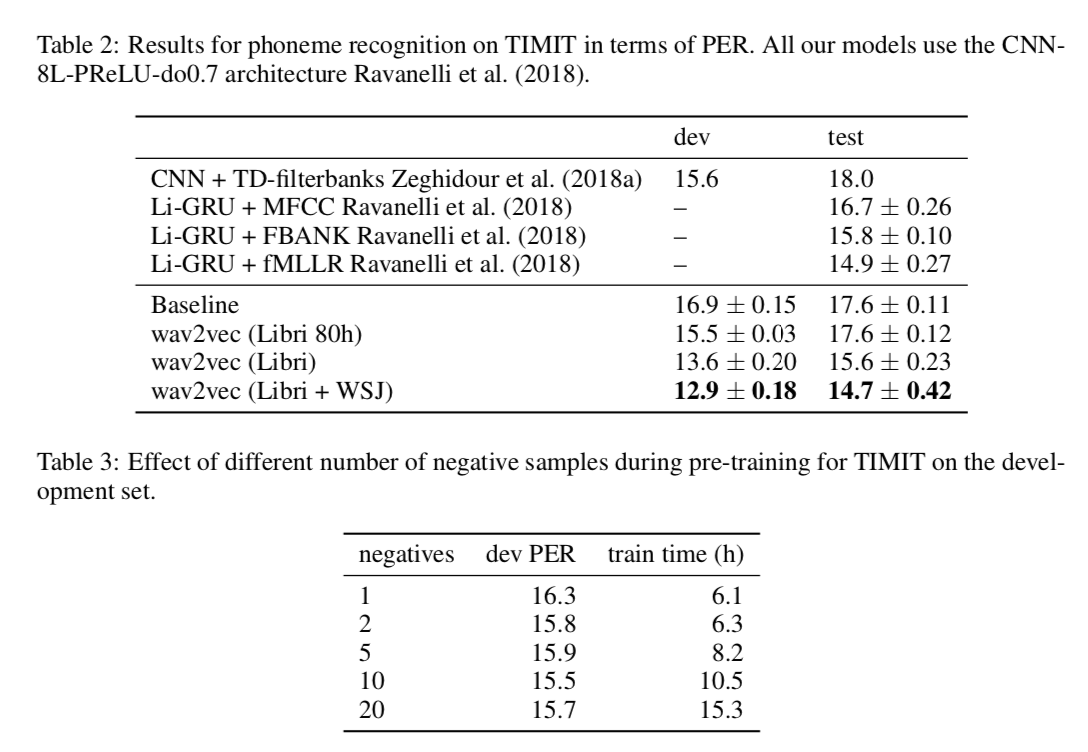
在 TIMIT 任务中,我们使用具有高辍学率的 7 层 wav2letter++ 模型(§3;Synnaeve 等人,2016 年)。 表 2 显示,当我们对 Librispeech 和 WSJ 音频数据进行预训练时,我们可以匹配最先进的技术。 随着更多数据用于预训练,准确率稳步提高,当我们使用最大量的数据进行预训练时,可以获得最佳准确率。
4.3 消融
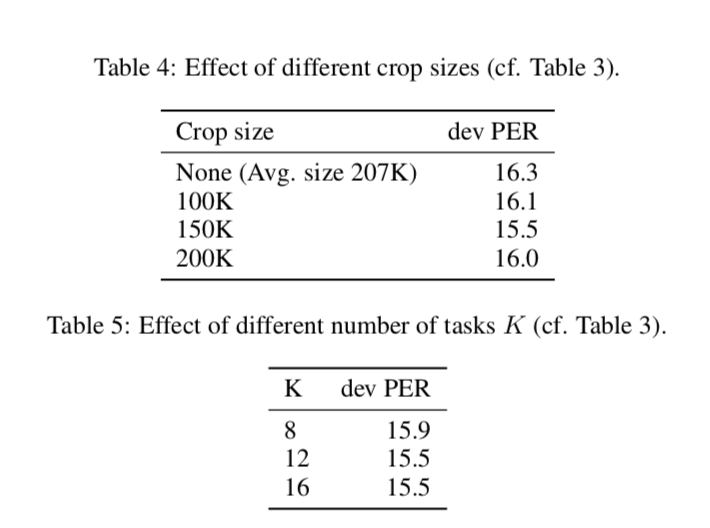
在本节中,我们分析了我们为 wav2vec 所做的一些设计选择。我们对干净的 Librispeech 的 80 小时子集进行预训练,并在 TIMIT 上进行评估。表 3 显示增加负样本的数量最多只能帮助十个样本。此后,随着训练时间的增加,性能趋于平稳。我们怀疑这是因为正样本的训练信号随着负样本数量的增加而减少。在这个实验中,除了负样本的数量外,一切都保持不变。
接下来,我们通过裁剪音频序列来分析数据增强的效果(第 3.4 节)。创建批次时,我们将序列裁剪为预定义的最大长度。表 4 显示 150K 帧的裁剪大小会产生最佳性能。不限制最大长度(无)给出了大约 207K 帧的平均序列长度,并导致最差的准确性。这很可能是因为该设置提供的数据增强量最少。
表 5 显示,预测未来超过 12 步不会带来更好的性能,并且增加步数会增加训练时间。
结论
我们介绍了 wav2vec,这是第一个使用完全卷积模型将无监督预训练应用于语音识别的应用。 我们的方法在 WSJ 的测试集上实现了 2.78 WER,这一结果优于文献中下一个最著名的基于字符的语音识别模型(Amodei 等,2016),同时使用的转录训练数据少了三个数量级。 我们表明,更多的预训练数据可以提高性能,而且这种方法不仅可以改进资源匮乏的设置,还可以改进使用所有《华尔街日报》训练数据的设置。 在未来的工作中,我们将研究可能进一步提高性能的不同架构和微调。