ADASPEECH: ADAPTIVE TEXT TO SPEECH FOR CUSTOM VOICE
Abstract
自定义语音是商业语音平台中的一种特定文本到语音 (TTS) 服务,旨在调整源 TTS 模型以使用来自她/他的少量语音合成目标说话者的个人语音。自定义语音对 TTS 自适应提出了两个独特的挑战:1)为了支持不同的客户,自适应模型需要处理可能与源语音数据非常不同的各种声学条件,以及 2)为了支持大量客户,每个目标说话者的自适应参数需要足够小,以减少内存使用,同时保持高语音质量。在这项工作中,我们提出了 AdaSpeech,这是一种自适应 TTS 系统,用于高质量和高效地定制新语音。我们在 AdaSpeech 中设计了几种技术来解决自定义语音中的两个挑战:1)为了处理不同的声学条件,我们在话语和音素级别对声学信息进行建模。具体来说,在预训练和微调期间,我们使用一个声学编码器来提取话语级(utterance-level vector)向量,另一个从目标语音中提取一系列音素级向量(phoneme-level vector);在推理中,我们从参考语音中提取话语级别向量,并使用声学预测器来预测音素级别向量。 2)为了更好地权衡自适应参数和语音质量,我们在 AdaSpeech 的梅尔谱图解码器中引入了条件层归一化,并在自适应的说话人嵌入之外对这部分进行了微调。我们在 LibriTTS 数据集上预训练源 TTS 模型,并在 VCTK 和 LJSpeech 数据集(与 LibriTTS 具有不同的声学条件)上对其进行微调,自适应数据很少,例如,20 个句子,大约 1 分钟的演讲。实验结果表明,AdaSpeech 实现了比基线方法更好的自适应质量,每个说话者只有大约 5K 的特定参数,这证明了其对自定义语音的有效性。
Introduction
文本转语音 (TTS) 旨在从文本中合成自然和可理解的语音,并在机器学习社区中引起了很多兴趣。 TTS 模型在使用大量高质量和单说话人录音进行训练时可以合成自然的人声,并且已经扩展到多说话人场景使用多说话人语料库。 然而,这些语料库包含一组固定的说话者,其中每个说话者仍然有一定数量的语音数据。
如今,自定义语音在个人助理、新闻广播和音频导航等不同应用场景中越来越受到关注,并在商业语音平台(部分自定义语音服务包括微软Azure、亚马逊AWS和谷歌云)中得到广泛支持。在自定义语音中,源TTS模型通常适用于自适应数据很少的个性化语音,因为自定义语音的用户为了方便起见,更喜欢记录尽可能少的自适应数据(几分钟或几秒)。很少有自适应数据对自适应语音的自然性和相似性提出了很大的挑战。此外,自定义语音还存在几个独特的挑战:1)自定义用户的录音通常与源语音数据(用于训练源 TTS 模型的数据)具有不同的声学条件。例如,适应数据通常记录有不同的说话韵律、风格、情绪、口音和录音环境。这些声学条件的不匹配使得源模型难以概括并导致较差的适应质量。 2) 在将源 TTS 模型适配到新语音时,需要在微调参数和语音质量之间进行权衡。一般来说,更多的适配参数通常会带来更好的语音质量,从而增加内存存储和服务成本。
虽然之前在 TTS 适配方面的工作已经很好地考虑了自定义语音中为数不多的适配数据设置,但还没有完全解决上述挑战。他们对整个模型或解码器部分进行了微调,实现了良好的质量,但导致了太多的自适应参数。商业化定制语音的部署需要减少适配参数的数量。否则,内存存储会随着用户的增加而爆炸。有些作品仅微调说话人嵌入,或训练说话人编码器模块在适应过程中不需要微调。虽然这些方法导致了轻量级和高效的适应,但它们导致了较差的适应质量。而且,之前的大部分工作都假设源语音数据和自适应数据在同一个域中,没有考虑不同声学条件的设置,这在自定义语音场景中是不切实际的。
在本文中,我们提出了 AdaSpeech,这是一种自适应 TTS 模型,用于高质量和高效的新语音定制。 AdaSpeech 为自定义语音采用三阶段管道:1) 预训练; 2)微调; 3) 推理。在预训练阶段,TTS模型在大规模多说话人数据集上进行训练,可以确保TTS模型覆盖多样化的文本和说话声音,有利于适应。在微调阶段,源 TTS 模型通过在具有不同声学条件的有限自适应数据上微调(部分)模型参数来适应新的语音。在推理阶段,TTS模型的未适配部分(所有自定义语音共享的参数)和适配部分(每个自定义语音都有特定的适配参数)都用于推理请求。我们基于流行的非自回归 TTS 模型构建 AdaSpeech,并进一步设计了几种技术来应对挑战在自定义语音中:
- 声学条件建模。为了处理不同的声学条件以进行适应,我们在预训练和微调中对话语和音素级别的声学条件进行建模。具体来说,我们使用两个声学编码器从目标语音中提取一个话语级向量和一系列音素级向量,作为梅尔谱解码器的输入,分别表示全局和局部声学条件。这样,解码器就可以根据这些声学信息预测不同声学条件下的语音。否则,模型会记住声学条件,不能很好地概括。在推理中,我们从参考语音中提取话语级别向量,并使用另一个建立在音素编码器上的声学预测器来预测音素级别向量。
- 条件层标准化。为了在确保自适应质量的同时微调尽可能少的参数,我们在预训练中修改了 Melspectrogram 解码器中的层归一化,通过使用说话人嵌入作为条件信息在层归一化中生成尺度和偏置向量。在微调中,我们只调整与条件层归一化相关的参数。通过这种方式,与微调整个模型相比,我们可以大大减少自适应参数,从而大大减少内存存储,但由于条件层归一化的灵活性,我们可以保持高质量的自适应语音。
为了评估我们提出的 AdaSpeech 对自定义语音的有效性,我们进行了实验以在 LibriTTS 数据集上训练 TTS 模型,并在具有不同自适应设置的 VCTK 和 LJSpeech 数据集上调整模型。 实验结果表明,AdaSpeech 在 MOS(平均意见得分)和 SMOS(相似性 MOS)方面比基线方法实现了更好的适应质量,每个说话者只有大约 5K 的特定参数,证明了其对自定义语音的有效性。
AdaSpeech
在本节中,我们首先描述我们提出的 AdaSpeech 的整体设计,然后介绍解决自定义语音挑战的关键技术。 最后,我们列出了用于自定义语音的 AdaSpeech 的预训练、微调和推理管道。
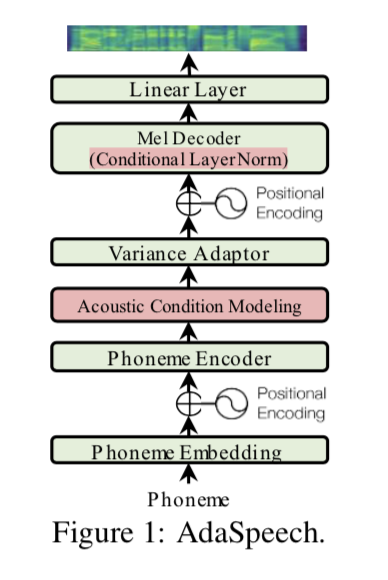
AdaSpeech 的模型结构如图 1 所示。我们采用 FastSpeech 2作为模型主干,因为 FastSpeech系列是非自回归 TTS。基本模型主干由音素编码器、梅尔谱解码器和方差适配器组成,该适配器将包括持续时间、音调和能量在内的方差信息提供到 Ren 等人的音素隐藏序列中。如图 1 所示,我们设计了两个额外的组件来解决自定义语音中的独特挑战:1)为了支持不同的客户,我们使用声学条件建模(Acoustic condition modeling)来捕获不同粒度的自适应语音的不同声学条件; 2)为了以负担得起的内存存储支持大量客户,我们在解码器中使用条件层归一化(Conditional LayerNorm),以在高语音质量的同时以较少的参数进行高效适应。在接下来的小节中,我们将分别介绍这些组件的详细信息。
2.1 声学条件建模
在自定义语音中,自适应数据可以用不同的韵律、风格、口音说话,并且可以在各种环境下记录,这可以使声学条件与源语音数据中的声学条件大不相同。这对适应源 TTS 模型提出了巨大的挑战,因为源语音不能涵盖自定义语音中的所有声学条件。缓解这个问题的一个实用方法是提高源 TTS 模型的适应性(通用性)。在文本到语音中,由于输入文本缺乏足够的声学条件(例如说话者音色、韵律和录音环境)来预测目标语音,因此模型倾向于记忆和过拟合训练数据,并且在适应过程中泛化能力较差。解决此类问题的一种自然方法是提供相应的声学条件作为输入,使模型学习合理的文本到语音映射,以实现更好的泛化而不是记忆。
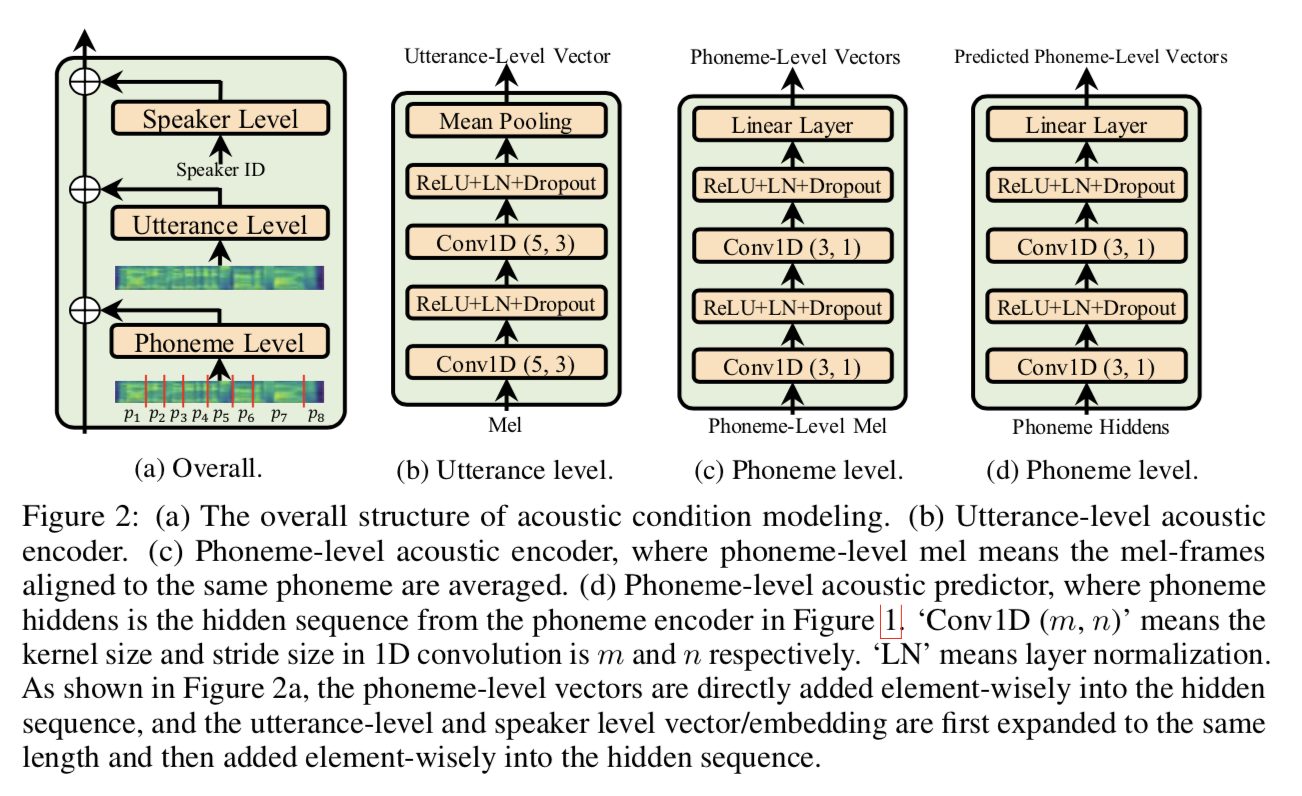
为了更好地模拟不同粒度的声学条件,我们对不同级别的声学条件进行分类,如图 2a 所示: 1) 说话人级别(speaker level),粗粒度的声学条件以捕获扬声器的整体特征; 2) 话语级别(utterance level),说话人每次话语的细粒度声学条件; 3)音素水平(phoneme level),话语的每个音素中更细粒度的声学条件,例如特定音素的重音、音高、韵律和时间环境噪声。由于说话人 ID(嵌入)被广泛用于捕捉多说话人场景中说话人级别的声学条件,因此默认情况下使用说话人嵌入,我们描述了话语级和音素级声学条件建模如下:
- 话语水平。 我们使用声学编码器从参考语音中提取向量,然后将其扩展并添加到音素隐藏序列中,以提供话语级声学条件。 如图 2b 所示,声学编码器由几个卷积层和一个平均池化层组成,以获得单个向量。 参考语音是训练时的目标语音,而推理时该说话者的随机选择语音。
- 音素水平。 我们使用另一个声学编码器(如图 2c 所示)从目标语音中提取一系列音素级向量并将其添加到音素隐藏序列中以提供音素级声学条件。 为了从语音中提取音素级信息,我们首先根据音素和梅尔谱序列之间的对齐(如图2a所示)对同一音素对应的语音帧进行平均,将语音帧序列的长度转换为长度音素序列。 在推理过程中,我们使用另一个基于原始音素编码器的音素级声学预测器(如图 2d 所示)来预测音素级向量。
使用语音编码器提取单个向量或向量序列来表示语音序列的特征在以前的工作中已经被采用。 他们通常利用它们来改善 TTS 模型的说话者音色或韵律,或提高模型的可控性。 在这项工作中,我们的声学条件建模的关键贡献是以新的视角对不同粒度的不同声学条件进行建模,从而使源模型更适应不同的适应数据。 如 4.2 节所分析,话语级和音素级声学建模确实可以帮助学习声学条件,并且对于确保适应质量至关重要。
2.2 CONDITIONAL LAYER NORMALIZATION
在使用小自适应参数的同时实现高自适应质量具有挑战性。 以前的工作使用说话人编码器的零样本自适应或仅微调扬声器嵌入无法达到满意的质量。 我们能否以略多但可以忽略不计的参数为代价大大提高语音质量? 为此,我们分析了 FastSpeech 2 的模型参数,它基本上建立在 Transformer 的结构之上,在每个 Transformer 块中都有一个自注意力网络和一个前馈网络。 self-attention 和两层前馈网络的 query、key、value 和 output 中的矩阵乘法都是参数密集型的,自适应效率不高。 我们发现解码器中的每个自注意力和前馈网络都采用层归一化,这可以极大地影响隐藏激活和最终预测的轻量级可学习尺度向量 $γ$ 和偏置向量 $β:LN (x) = γ \frac{x−μ}{\sigma} + β$,其中 $μ$ 和 $σ$ 是隐藏向量 $x$ 的均值和方差。
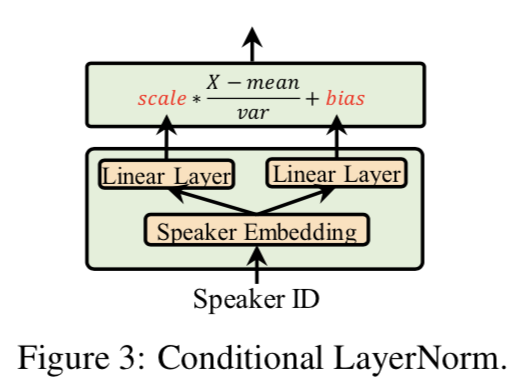
如果我们可以使用一个小的条件网络,根据相应的说话人特征确定层归一化中的尺度和偏置向量,那么我们就可以在适应新的语音时对这个条件网络进行微调,在保证适应质量的同时大大减少适应参数 . 如图 3 所示,条件网络由两个简单的线性层 $W_c^γ$ 和 $W_c^β$ 组成,它们以扬声器嵌入 $E^s$ 作为输入,分别输出尺度和偏置向量:
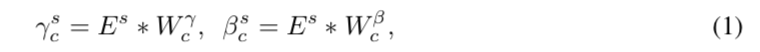
其中 $s$ 表示说话者 ID,$c ∈ [C]$ 表示解码器中有 $C$ 个条件层归一化(解码器层数为 $(C − 1)/2$,因为每层有两个条件层归一化对应于自注意力 和 Transformer 中的前馈网络,并且在最终输出处有一个额外的层归一化)并且每个都使用不同的条件矩阵。
2.3 AdaSpeech 的pipeline

我们在算法 1 中列出了 AdaSpeech 的预训练、微调和推理管道。 在微调期间,我们只对解码器和说话人嵌入 $E_s$ 中每个条件层归一化中的两个矩阵 $W_c^γ$ 和 $W_c^β$ 进行微调,其他 模型参数包括话语级和音素级声学编码器以及音素级声学预测器,如第 2.1 节所述。 在推理过程中,我们不直接在每个条件层归一化中使用两个矩阵 $W_c^γ$ 和 $W_c^β$,因为它们仍然有很大的参数。 取而代之的是,考虑到 $E_s$ 在推理中是固定的,我们使用这两个矩阵根据等式 1 从说话人嵌入 $E_s$ 计算每个尺度和偏置向量 $γ_c^s$ 和 $β_c^s$。 这样,我们可以节省大量的内存storage。
实验设置
数据集
我们在 LibriTTS 数据集上训练 AdaSpeech 源模型,该数据集是源自 LibriSpeech的多说话人语料库(2456 名说话人),包含 586 小时的语音数据。 为了在自定义语音场景中评估 AdaSpeech,我们使源模型适应其他数据集中的语音,包括 VCTK(具有 108 个扬声器和 44 小时语音数据的多扬声器数据集)和 LJSpeech(具有 24 小时语音数据的单扬声器高质量数据集),与 LibriTTS 具有不同的声学条件。 作为比较,我们还使源模型适应同一 LibriTTS 数据集中的语音。
我们从 LibriTTS 和 VCTK 的训练集中随机选择几个说话者(包括男性和女性)和 LJSpeech 训练集中唯一的单个说话者进行适应。对于每个选择的说话者,我们随机选择 K = 20 个句子进行适应,并在实验部分研究较小 K 的影响。我们使用 LibriTTS 训练集中的所有说话者(不包括选择进行适配的说话者)来训练源 AdaSpeech 模型,并使用这些数据集中与适应说话者对应的原始测试集来评估适应语音质量。
我们对这些语料库中的语音和文本数据进行如下预处理:1)将所有语音数据的采样率转换为16kHz; 2)按照Shen等人的常见做法提取具有12.5ms跳跃大小和50ms窗口大小的mel谱图。 3)通过字素到音素的转换将文本序列转换为音素序列,并以音素作为编码器输入。
模型设置
AdaSpeech 的模型遵循 FastSpeech 2 中的基本结构,它由 4 个用于音素编码器和 Melspectrogram 解码器的前馈 Transformer 块组成。隐藏维度(包括音素嵌入、说话者嵌入、self-attention中的隐藏、前馈网络的输入和输出隐藏)设置为256。注意力头的数量、前馈滤波器大小和内核大小分别设置为 2、1024 和 9。输出线性层将 256 维隐藏转换为 80 维梅尔谱图。其他模型配置遵循 Fastspeech 除非另有说明。
音素级声学编码器(图 2c)和预测器(图 2d)共享相同的结构,由 2 个卷积层组成,滤波器大小和内核大小分别为 256 和 3,还有一个线性层将隐藏层压缩到一个维度4(我们根据我们的初步研究选择了 4 的维度,也与之前的工作一致。我们使用 MFA来提取音素和梅尔谱序列之间的对齐,用于准备音素级声学编码器的输入。我们还尝试将 VQ-VAE 用于音素级声学编码器,但没有发现明显的收益。话语级声学编码器由 2 个卷积层组成,滤波器大小、内核大小和步长大小分别为 256、5 和 3,以及一个池化层以获得单个向量。
训练、适配和推理
在源模型训练过程中,我们首先对 AdaSpeech 进行 60,000 步的训练,除音素级声学预测器的参数外,所有模型参数都进行了优化。然后我们对剩余的 40,000 步联合训练 AdaSpeech 和音素级声学预测器,其中音素级声学编码器的隐藏输出用作标签(停止梯度以防止回流到音素级声学编码器)以训练具有均方误差 (MSE) 损失的音素级声学预测器。我们在 4 个 NVIDIA P40 GPU 上训练 AdaSpeech,每个 GPU 的批量大小约为 12,500 个语音帧。 Adam 优化器与 $β_1 = 0.9、β_2 = 0.98、ε = 10^{−9}$ 一起使用。在
适配过程中,我们在 1 个 NVIDIA P40 GPU 上对 AdaSpeech 进行了 2000 步的微调,其中仅优化了扬声器嵌入和条件层归一化的参数。在推理过程中,从说话人的另一个参考语音中提取话语级声学条件,从音素级声学预测器预测音素级声学条件。我们使用 MelGAN 作为声码器从生成的梅尔频谱图合成波形。
结果
在本节中,我们首先评估 AdaSpeech 的自适应语音质量,并进行消融研究以验证 AdaSpeech 中每个组件的有效性,最后我们展示了我们的方法的一些分析。
4.1 自适应语音质量
我们根据自然度(合成声音听起来像人类的自然声音)和相似度(合成声音听起来如何与这个说话者相似)来评估自适应声音的质量。因此,我们使用 MOS(平均意见得分)对自然度和 SMOS(相似度 MOS)进行人工评估以进行相似性评估。每个句子由 20 名评委听。对于 VCTK 和 LibriTTS,我们将多个适配说话人的 MOS 和 SMOS 分数取平均值作为最终分数。我们将 AdaSpeech 与以下几种设置进行比较:1) GT,真实录音; 2)GT mel + Vocoder,使用ground-truth mel-spectrogram与MelGAN声码器合成波形; 3)Baseline(spk emb),一个基于FastSpeech2的baseline系统,它只在适应时微调说话人的嵌入,可以看作我们的下界; 4)Baseline(decoder),另一个基于FastSpeech2的baseline系统,在适配时对整个解码器进行微调,由于适配时使用了更多的参数,可以认为是一个很强的可比系统; 5) AdaSpeech,我们提出的 AdaSpeech 系统,在适应期间具有话语/音素级声学条件建模和条件层归一化。
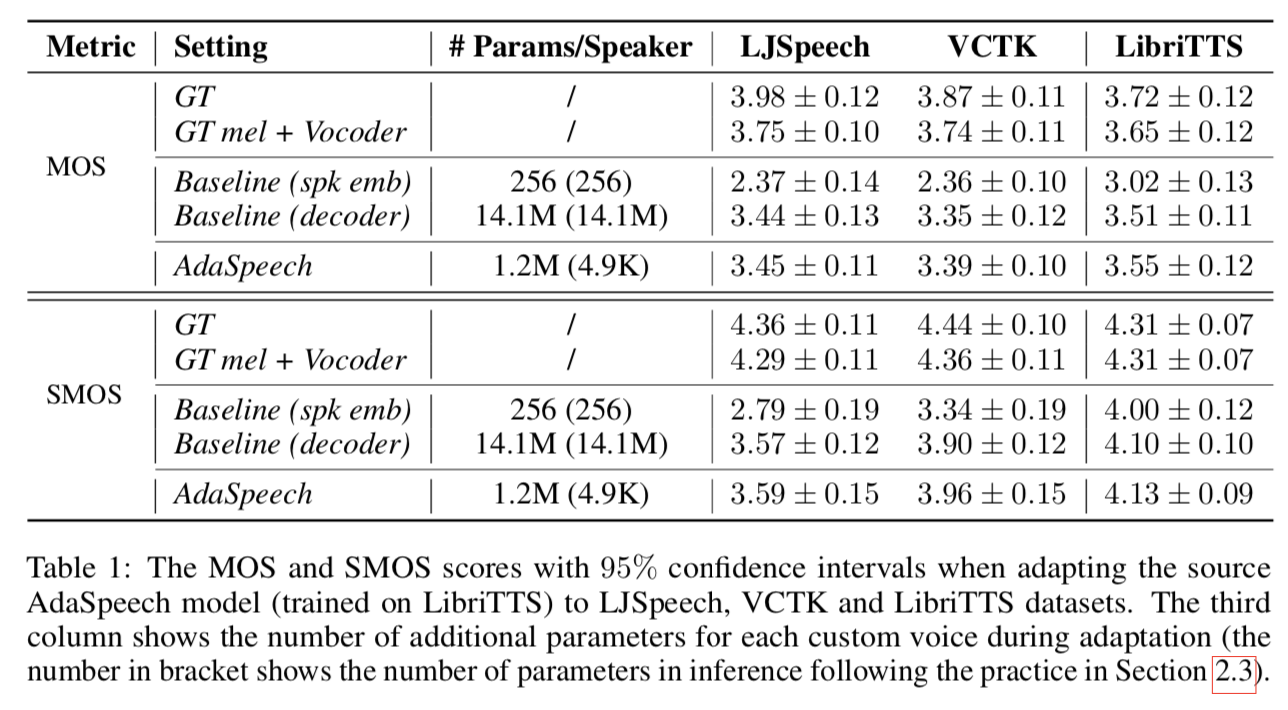
MOS 和 SMOS 结果如表 1 所示。我们有几个观察结果:1)将模型(在 LibriTTS 上训练)适应跨域数据集(LJSpeech 和 VCTK)比适应域内数据集(LibriTTS)更困难,因为在跨域数据集上,自适应模型(两个基线和 AdaSpeech)与真实 mel + 声码器设置之间的 MOS 和 SMOS 差距更大。这也证实了在自定义语音场景中建模不同声学条件的挑战。 2) 与仅微调说话人嵌入,即基线 (spk emb) 相比,AdaSpeech 在三个自适应数据集中在 MOS 和 SMOS 方面都实现了显着改进,仅在条件层归一化中利用了更多的参数。我们还在下一小节(表 3)中分析,即使我们增加基线的自适应参数以匹配或超过 AdaSpeech,它的性能仍然比 AdaSpeech 差很多。 3)与微调整个解码器,即基线(解码器)相比,AdaSpeech 在 MOS 和 SMOS 中都实现了稍微更好的质量,重要的是具有更小的自适应参数,这证明了我们提出的声学条件建模和条件的有效性和效率层归一化。请注意,对整个解码器进行微调会导致自适应参数过多,无法满足自定义语音场景。
4.2 方法分析
在本节中,我们首先进行消融研究以验证 AdaSpeech 中每个组件的有效性,包括话语级和音素级声学条件建模以及条件层归一化,然后对我们提出的 AdaSpeech 进行更详细的分析。
Ablation Study
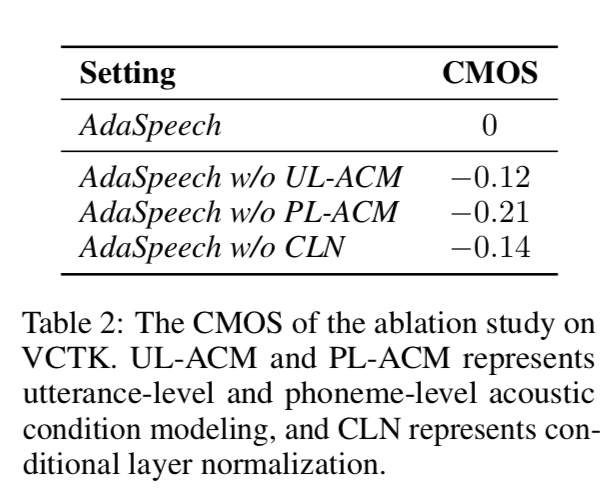
我们在 VCTK 测试集上比较了AdaSpeech 中去除每个组件时自适应语音质量的CMOS(比较MOS)(每个句子由20 个评委听)。 具体来说,当去除条件层归一化时,我们只微调说话人嵌入。 从表 2 中我们可以看出,去除话语级和音素级声学建模以及条件层归一化都会导致语音质量的性能下降,证明了 AdaSpeech 中每个组件的有效性。
声学条件建模分析
我们分析了从 LibriTTS 数据集上的几个说话者的话语级声学编码器中提取的向量。我们在图 4a 中使用 t-SNE 来说明它们,其中每个点代表一个话语级别向量,每种颜色都属于同一个说话者。 可以看出,同一个说话者的不同话语聚集在一起,但在声学条件上存在差异。 也有一些例外,例如棕色实心圆圈中的两个粉红色点和一个蓝色点。 根据我们对相应语音数据的调查,这些点对应于声音短而情绪化的话语,因此虽然属于不同的说话者,但彼此接近。
条件层归一化分析
我们进一步将条件层归一化 (CLN) 与其他两种设置进行比较:1) LN + 微调尺度/偏差:去除扬声器嵌入条件,仅微调层归一化和扬声器嵌入中的尺度/偏差; 2) LN + 微调其他:去除说话人嵌入的条件,而是微调解码器中的其他(类似甚至更多)参数。 CMOS 评估如表 3 所示。可以看出,与条件层归一化相比,这两种设置导致的质量较差,这验证了其有效性。
变化的适应数据
我们在 VCTK 和 LJSpeech 上研究了不同数量的自适应数据(少于默认设置)的语音质量,并进行了如图 4b 所示的 MOS 评估。 可以看出,当自适应数据减少时,语音质量继续下降,当自适应数据少于10个句子时,语音质量下降很快。
结论
在本文中,我们开发了 AdaSpeech,这是一种自适应 TTS 系统,用于支持自定义语音中的独特要求。我们提出声学条件建模,使源 TTS 模型更适合具有各种声学条件的自定义语音。我们进一步设计了条件层归一化以提高适应效率:微调少量模型参数以实现高语音质量。我们最终展示了 AdaSpeech 中用于自定义语音的预训练、微调和推理管道。实验结果表明,AdaSpeech 可以支持具有不同声学条件的自定义语音,内存存储量少,同时语音质量高。对于未来的工作,我们将进一步改进源 TTS 模型中声学条件的建模,并研究更多样化的声学条件,例如自定义语音中的嘈杂语音。我们还将研究未转录数据的自适应设置并进一步压缩模型大小以支持更多自定义语音。